Stable diffusion fine-tune repo for Paris shopfront experiment (This Place Does Exist)
| assets | ||
| configs | ||
| data | ||
| examples | ||
| ldm | ||
| models | ||
| scripts | ||
| .gitignore | ||
| LICENSE | ||
| main.py | ||
| notebook_helpers.py | ||
| README.md | ||
| requirements.txt | ||
| setup.py | ||
Experiments with Stable Diffusion
This repository extends and adds to the original training repo for Stable Diffusion.
Currently it adds:
Fine tuning
Makes it easy to fine tune Stable Diffusion on your own dataset. For example generating new Pokemon from text:

Girl with a pearl earring, Cute Obama creature, Donald Trump, Boris Johnson, Totoro, Hello Kitty
For a step by step guide see the Lambda Labs examples repo.
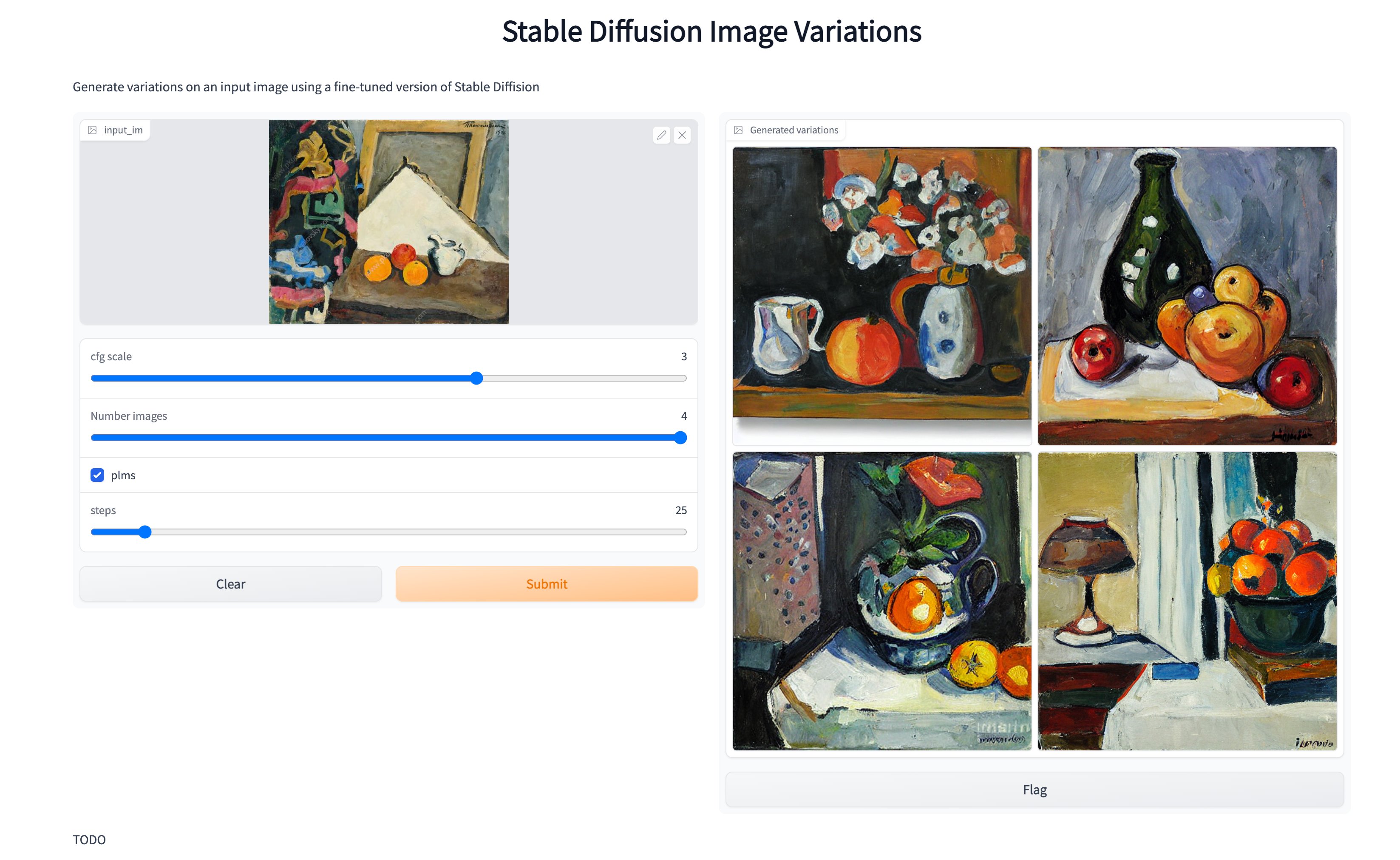
Image variations

![]()
For more details on the Image Variation model see the model card.
- Get access to a Linux machine with a decent NVIDIA GPU (e.g. on Lambda GPU Cloud)
- Clone this repo
- Make sure PyTorch is installed and then install other requirements:
pip install -r requirements.txt - Get model from huggingface hub lambdalabs/stable-diffusion-image-conditioned
- Put model in
models/ldm/stable-diffusion-v1/sd-clip-vit-l14-img-embed_ema_only.ckpt - Run
scripts/image_variations.pyorscripts/gradio_variations.py
All together:
git clone https://github.com/justinpinkney/stable-diffusion.git
cd stable-diffusion
mkdir -p models/ldm/stable-diffusion-v1
wget https://huggingface.co/lambdalabs/stable-diffusion-image-conditioned/resolve/main/sd-clip-vit-l14-img-embed_ema_only.ckpt -O models/ldm/stable-diffusion-v1/sd-clip-vit-l14-img-embed_ema_only.ckpt
pip install -r requirements.txt
python scripts/gradio_variations.py
Then you should see this:
Trained by Justin Pinkney (@Buntworthy) at Lambda