init
This commit is contained in:
commit
cbfd966555
79 changed files with 11596 additions and 0 deletions
.github/image
.gitignoreLICENSEREADME.mdanalysis
data
detection
data
eval
lightning
main.pymodels
__init__.pyclassification.py
detection
__init__.pydetectron.py
efficientdet
yolo
plots
sandbox
util
plot
requirements.txtstreetview
util
BIN
.github/image/detections.png
vendored
Normal file
BIN
.github/image/detections.png
vendored
Normal file
{kind=link}
Binary file not shown.
|
After 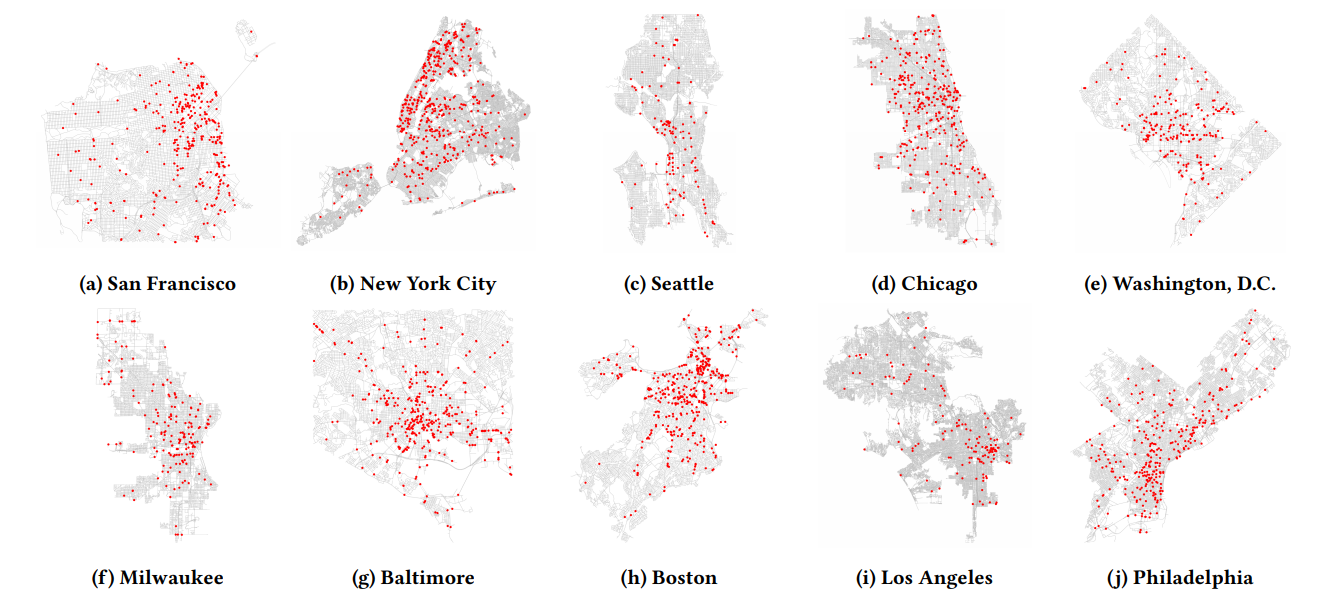
(image error) Size: 356 KiB |
141
.gitignore
vendored
Normal file
141
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,141 @@
|
||||||
|
# Byte-compiled / optimized / DLL files
|
||||||
|
__pycache__/
|
||||||
|
*.py[cod]
|
||||||
|
*$py.class
|
||||||
|
|
||||||
|
# C extensions
|
||||||
|
*.so
|
||||||
|
|
||||||
|
# Distribution / packaging
|
||||||
|
.Python
|
||||||
|
build/
|
||||||
|
develop-eggs/
|
||||||
|
dist/
|
||||||
|
downloads/
|
||||||
|
eggs/
|
||||||
|
.eggs/
|
||||||
|
lib/
|
||||||
|
lib64/
|
||||||
|
parts/
|
||||||
|
sdist/
|
||||||
|
var/
|
||||||
|
wheels/
|
||||||
|
pip-wheel-metadata/
|
||||||
|
share/python-wheels/
|
||||||
|
*.egg-info/
|
||||||
|
.installed.cfg
|
||||||
|
*.egg
|
||||||
|
MANIFEST
|
||||||
|
|
||||||
|
# PyInstaller
|
||||||
|
# Usually these files are written by a python script from a template
|
||||||
|
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||||
|
*.manifest
|
||||||
|
*.spec
|
||||||
|
|
||||||
|
# Installer logs
|
||||||
|
pip-log.txt
|
||||||
|
pip-delete-this-directory.txt
|
||||||
|
|
||||||
|
# Unit test / coverage reports
|
||||||
|
htmlcov/
|
||||||
|
.tox/
|
||||||
|
.nox/
|
||||||
|
.coverage
|
||||||
|
.coverage.*
|
||||||
|
.cache
|
||||||
|
nosetests.xml
|
||||||
|
coverage.xml
|
||||||
|
*.cover
|
||||||
|
*.py,cover
|
||||||
|
.hypothesis/
|
||||||
|
.pytest_cache/
|
||||||
|
|
||||||
|
# Translations
|
||||||
|
*.mo
|
||||||
|
*.pot
|
||||||
|
|
||||||
|
# Django stuff:
|
||||||
|
*.log
|
||||||
|
local_settings.py
|
||||||
|
db.sqlite3
|
||||||
|
db.sqlite3-journal
|
||||||
|
|
||||||
|
# Flask stuff:
|
||||||
|
instance/
|
||||||
|
.webassets-cache
|
||||||
|
|
||||||
|
# Scrapy stuff:
|
||||||
|
.scrapy
|
||||||
|
|
||||||
|
# Sphinx documentation
|
||||||
|
docs/_build/
|
||||||
|
|
||||||
|
# PyBuilder
|
||||||
|
target/
|
||||||
|
|
||||||
|
# Jupyter Notebook
|
||||||
|
.ipynb_checkpoints
|
||||||
|
|
||||||
|
# IPython
|
||||||
|
profile_default/
|
||||||
|
ipython_config.py
|
||||||
|
|
||||||
|
# pyenv
|
||||||
|
.python-version
|
||||||
|
|
||||||
|
# pipenv
|
||||||
|
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||||
|
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||||
|
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||||
|
# install all needed dependencies.
|
||||||
|
#Pipfile.lock
|
||||||
|
|
||||||
|
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
||||||
|
__pypackages__/
|
||||||
|
|
||||||
|
# Celery stuff
|
||||||
|
celerybeat-schedule
|
||||||
|
celerybeat.pid
|
||||||
|
|
||||||
|
# SageMath parsed files
|
||||||
|
*.sage.py
|
||||||
|
|
||||||
|
# Environments
|
||||||
|
.env
|
||||||
|
.venv
|
||||||
|
env/
|
||||||
|
venv/
|
||||||
|
ENV/
|
||||||
|
env.bak/
|
||||||
|
venv.bak/
|
||||||
|
|
||||||
|
# Spyder project settings
|
||||||
|
.spyderproject
|
||||||
|
.spyproject
|
||||||
|
|
||||||
|
# Rope project settings
|
||||||
|
.ropeproject
|
||||||
|
|
||||||
|
# mkdocs documentation
|
||||||
|
/site
|
||||||
|
|
||||||
|
# mypy
|
||||||
|
.mypy_cache/
|
||||||
|
.dmypy.json
|
||||||
|
dmypy.json
|
||||||
|
|
||||||
|
# Pyre type checker
|
||||||
|
.pyre/
|
||||||
|
|
||||||
|
# IPython Notebook
|
||||||
|
*.ipynb
|
||||||
|
*.csv
|
||||||
|
*.ckpt
|
||||||
|
output/
|
||||||
|
cache/
|
||||||
|
figures/
|
||||||
|
notebook/
|
||||||
|
|
||||||
|
# Images
|
||||||
|
*.jpg
|
||||||
21
LICENSE
Normal file
21
LICENSE
Normal file
|
|
@ -0,0 +1,21 @@
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2020 Hao Sheng
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
86
README.md
Normal file
86
README.md
Normal file
|
|
@ -0,0 +1,86 @@
|
||||||
|
# Surveilling Surveillance: Estimating the Prevalence of Surveillance Cameras with Street View Data
|
||||||
|
### [Project page](https://stanford-policylab.github.io/surveillance/) | [Paper](https://arxiv.org/abs/2105.01764)
|
||||||
|
|
||||||
|

|
||||||
|
__Locations of verified cameras in 10 large U.S. cities for the period 2016–2020. Densely clustered areas of points indicate regions with high camera density in each city. Camera density varies widely between neighborhoods. Note: Scale varies
|
||||||
|
between cities.__
|
||||||
|
|
||||||
|
This is the code base of the [Surveillance Camera](https://arxiv.org/abs/2105.01764) paper:
|
||||||
|
```
|
||||||
|
@article{sheng2021surveilling,
|
||||||
|
title={Surveilling Surveillance: Estimating the Prevalence of Surveillance Cameras with Street View Data},
|
||||||
|
author={Sheng, Hao and Yao, Keniel and Goel, Sharad},
|
||||||
|
journal={arXiv e-prints},
|
||||||
|
pages={arXiv--2105},
|
||||||
|
year={2021}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Camera Detection
|
||||||
|
### Requirements
|
||||||
|
- Linux or macOS with Python ≥ 3.6
|
||||||
|
- [PyTorch](https://pytorch.org/) ≥ 1.6 and [torchvision](https://github.com/pytorch/vision/) that matches the PyTorch installation. Install them together at [pytorch.org](https://pytorch.org/) to make sure of this
|
||||||
|
- [Detection2](https://github.com/facebookresearch/detectron2). The installation instruction of Detection2 can be found [here](https://detectron2.readthedocs.io/en/latest/tutorials/install.html)
|
||||||
|
|
||||||
|
Install Python dependencies by running:
|
||||||
|
```shell
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
### Download street-view images
|
||||||
|
```shell
|
||||||
|
python main.py download_streetview_image --key GOOGLE_API_KEY --sec GOOGLE_API_SECRET
|
||||||
|
```
|
||||||
|
|
||||||
|
### Model training
|
||||||
|
```shell
|
||||||
|
cd detection && python main.py train --exp_name EXPERIMENT_NAME --[hyparameter] [value]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Model inference
|
||||||
|
```shell
|
||||||
|
cd detection && python main.py test --deploy --deploy_meta_path [DEPLOY_META_PATH]
|
||||||
|
```
|
||||||
|
, where `DEPLOY_META_PATH` is a path to a csv file of the following format:
|
||||||
|
|
||||||
|
| save_path | panoid | heading | downloaded |
|
||||||
|
| --------- | ------ | ------- | ---------- |
|
||||||
|
| /dY/5I/l8/4NW89-ChFSP71GiA/344.png | dY5Il84NW89-ChFSP71GiA | -105.55188877562128 | True |
|
||||||
|
| ... | | |
|
||||||
|
|
||||||
|
Here, `panoid` and `heading` refer to the ID and heading of each street-view image.
|
||||||
|
|
||||||
|
|
||||||
|
## Analysis
|
||||||
|
To reproduce the figures and tables in our paper, run the `analysis/results.Rmd` script.
|
||||||
|
|
||||||
|
You'll need to download our camera and road network data [available here](https://storage.googleapis.com/scpl-surveillance/camera-data.zip) into a `data` directory in the root of this repository.
|
||||||
|
|
||||||
|
## Artifacts
|
||||||
|
|
||||||
|
### Annotations
|
||||||
|
|
||||||
|
Our collected camera annotations can be downloaded as follows:
|
||||||
|
|
||||||
|
| #images | # cameras | link | md5 |
|
||||||
|
| ------- | :---------: | ---- | --- |
|
||||||
|
| 3,155 | 1,696 | [download](https://storage.googleapis.com/scpl-surveillance/meta.csv) | `b2340143c6af2d1e6bfefd5001fd94c1` |
|
||||||
|
|
||||||
|
- *2021-5-20: This dataset is larger than the one reported in the paper as we include verified examples from our pilot.*
|
||||||
|
- *2021-5-18: The metadata can also be found in this repo as `./data/meta.csv`*.
|
||||||
|
|
||||||
|
### Pre-trained Models
|
||||||
|
|
||||||
|
Our pre-trained camera detection model can be downloaded as follows:
|
||||||
|
|
||||||
|
| architecture | Size | link | md5 |
|
||||||
|
| ------------ | ----- | ---- | --- |
|
||||||
|
| FasterRCNN | 472 Mb| [download](https://storage.googleapis.com/scpl-surveillance/model.zip) | `dba44ad36340d3291102e72b340568a0` |
|
||||||
|
|
||||||
|
- *2021-5-20: We updated the model architecture (FasterRCNN).*
|
||||||
|
|
||||||
|
### Detection and Road Network Data
|
||||||
|
|
||||||
|
| Size | link | md5 |
|
||||||
|
| ----- | ---- | --- |
|
||||||
|
| 97 Mb| [download](https://storage.googleapis.com/scpl-surveillance/camera-data.zip) | `6ceab577c53ba8dbe60b0ff1c8d5069a` |
|
||||||
252
analysis/figures.R
Normal file
252
analysis/figures.R
Normal file
|
|
@ -0,0 +1,252 @@
|
||||||
|
estimate_detection_metrics <- function(df, recall = 0.63) {
|
||||||
|
df %>%
|
||||||
|
left_join(city_data) %>%
|
||||||
|
transmute(
|
||||||
|
city,
|
||||||
|
type,
|
||||||
|
period,
|
||||||
|
road_network_length_km ,
|
||||||
|
m_per_pano,
|
||||||
|
pop_pano = 2 * road_network_length_km * 1000 / m_per_pano, # N
|
||||||
|
n_pano,
|
||||||
|
n_detection,
|
||||||
|
# detection rate (unadjusted detections per pano)
|
||||||
|
p_hat = n_detection / n_pano,
|
||||||
|
# infinite population sd:
|
||||||
|
p_hat_sd = sqrt(p_hat * (1 - p_hat) / n_pano),
|
||||||
|
# for finite population sd:
|
||||||
|
# p_hat_sd = sqrt((p_hat * (1 - p_hat) / n_pano) * ((pop_pano - n_pano) / (pop_pano - 1))),
|
||||||
|
# detection rate (detections per km counting both sides of the road per km)
|
||||||
|
est_detections_per_km = p_hat * (1000 / m_per_pano) * (2 / recall),
|
||||||
|
se_detections_per_km = p_hat_sd * (1000 / m_per_pano) * (2 / recall),
|
||||||
|
# detection count
|
||||||
|
est_detections = est_detections_per_km * road_network_length_km,
|
||||||
|
se_detections = se_detections_per_km * road_network_length_km
|
||||||
|
) %>%
|
||||||
|
ungroup() %>%
|
||||||
|
select(-p_hat, -p_hat_sd)
|
||||||
|
}
|
||||||
|
|
||||||
|
plot_camera_density <- function(df, legend = TRUE) {
|
||||||
|
if (legend) {
|
||||||
|
legend_position = "bottom"
|
||||||
|
} else {
|
||||||
|
legend_position = "none"
|
||||||
|
}
|
||||||
|
|
||||||
|
df %>%
|
||||||
|
ggplot(aes(x = city, y = est_detections_per_km, fill = type)) +
|
||||||
|
geom_col() +
|
||||||
|
geom_linerange(aes(
|
||||||
|
ymin = est_detections_per_km - 1.96*se_detections_per_km,
|
||||||
|
ymax = est_detections_per_km + 1.96*se_detections_per_km
|
||||||
|
)) +
|
||||||
|
scale_x_discrete(name = "") +
|
||||||
|
scale_y_continuous(
|
||||||
|
name = "Estimated cameras per km",
|
||||||
|
position = "right",
|
||||||
|
expand = expansion(mult = c(0, 0.1))
|
||||||
|
) +
|
||||||
|
scale_fill_discrete(name = "") +
|
||||||
|
coord_flip() +
|
||||||
|
theme(
|
||||||
|
panel.border = element_blank(),
|
||||||
|
axis.line = element_line(size = 1, color = "black"),
|
||||||
|
axis.title.x = element_text(family = "Helvetica", color = "black"),
|
||||||
|
axis.text = element_text(family = "Helvetica", color = "black"),
|
||||||
|
legend.position = legend_position,
|
||||||
|
panel.grid.major.x = element_blank(),
|
||||||
|
panel.grid.major.y = element_blank(),
|
||||||
|
panel.grid.minor = element_blank()
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
load_road_network <- function(city_name){
|
||||||
|
stopifnot(city_name %in% city_data$city)
|
||||||
|
|
||||||
|
path <- here::here("data", "road_network", city_name, "edges.shp")
|
||||||
|
read_sf(path)
|
||||||
|
}
|
||||||
|
|
||||||
|
get_max_points <- function(df){
|
||||||
|
df %>%
|
||||||
|
select(geometry) %>%
|
||||||
|
st_cast("POINT") %>%
|
||||||
|
st_coordinates() %>%
|
||||||
|
as_tibble() %>%
|
||||||
|
summarize(
|
||||||
|
x_max = max(X),
|
||||||
|
x_min = min(X),
|
||||||
|
y_max = max(Y),
|
||||||
|
y_min = min(Y)
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
generate_sampled_point_map <- function(df, city_name){
|
||||||
|
# load road network
|
||||||
|
road_network <- load_road_network(city_name)
|
||||||
|
|
||||||
|
# get crs
|
||||||
|
road_network_crs <- st_crs(road_network) %>%
|
||||||
|
as.integer()
|
||||||
|
road_network_crs <- road_network_crs[1]
|
||||||
|
|
||||||
|
# find bounding coordinates of road network
|
||||||
|
bbox <- st_bbox(road_network)
|
||||||
|
|
||||||
|
# plot points
|
||||||
|
road_network %>%
|
||||||
|
ggplot() +
|
||||||
|
geom_sf(fill = "white", color = "gray", alpha = 0.6) +
|
||||||
|
geom_sf(
|
||||||
|
data = df %>%
|
||||||
|
filter(city == city_name) %>%
|
||||||
|
st_as_sf(coords = c("lon", "lat"),
|
||||||
|
# ensure same crs as road network
|
||||||
|
crs = road_network_crs,
|
||||||
|
agr = "constant"),
|
||||||
|
color = "blue", size = 0.2,
|
||||||
|
shape = 16, alpha = 1
|
||||||
|
) +
|
||||||
|
scale_x_continuous(expand = expansion(mult = c(0.02, 0.02))) +
|
||||||
|
scale_y_continuous(expand = expansion(mult = c(0, 0.02))) +
|
||||||
|
coord_sf(xlim = c(bbox$xmin, bbox$xmax), ylim = c(bbox$ymin, bbox$ymax)) +
|
||||||
|
theme(
|
||||||
|
axis.text = element_blank(),
|
||||||
|
axis.ticks = element_blank(),
|
||||||
|
panel.grid = element_blank(),
|
||||||
|
panel.border = element_blank(),
|
||||||
|
legend.position = "bottom",
|
||||||
|
legend.text = element_text(size = 20)
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
generate_detected_point_map <- function(df, city_name){
|
||||||
|
# load road network
|
||||||
|
road_network <- load_road_network(city_name)
|
||||||
|
|
||||||
|
# get crs
|
||||||
|
road_network_crs <- st_crs(road_network) %>%
|
||||||
|
as.integer()
|
||||||
|
road_network_crs <- road_network_crs[1]
|
||||||
|
|
||||||
|
# find bounding coordinates of road network
|
||||||
|
bbox <- st_bbox(road_network)
|
||||||
|
|
||||||
|
# plot points
|
||||||
|
road_network %>%
|
||||||
|
ggplot() +
|
||||||
|
geom_sf(fill = "white", color = "gray", alpha = 0.6) +
|
||||||
|
geom_sf(
|
||||||
|
data = df %>%
|
||||||
|
filter(
|
||||||
|
city == city_name,
|
||||||
|
camera_count > 0
|
||||||
|
) %>%
|
||||||
|
st_as_sf(coords = c("lon", "lat"),
|
||||||
|
# ensure same crs as road network
|
||||||
|
crs = road_network_crs,
|
||||||
|
agr = "constant"),
|
||||||
|
color = "red", size = 0.5,
|
||||||
|
shape = 16, alpha = 1
|
||||||
|
) +
|
||||||
|
scale_x_continuous(expand = expansion(mult = c(0.02, 0.02))) +
|
||||||
|
scale_y_continuous(expand = expansion(mult = c(0, 0.02))) +
|
||||||
|
coord_sf(xlim = c(bbox$xmin, bbox$xmax), ylim = c(bbox$ymin, bbox$ymax)) +
|
||||||
|
theme(
|
||||||
|
axis.text = element_blank(),
|
||||||
|
axis.ticks = element_blank(),
|
||||||
|
panel.grid = element_blank(),
|
||||||
|
panel.border = element_blank(),
|
||||||
|
legend.position = "bottom",
|
||||||
|
legend.text = element_text(size = 20)
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
annotate_points_with_census <- function(df, city_name, census_var){
|
||||||
|
stopifnot(census_var %in% c("income", "race"))
|
||||||
|
|
||||||
|
# define state, county using `city_data`
|
||||||
|
state <- city_data %>%
|
||||||
|
filter(city == city_name) %>%
|
||||||
|
pull(state)
|
||||||
|
county <- city_data %>%
|
||||||
|
filter(city == city_name) %>%
|
||||||
|
pull(county)
|
||||||
|
|
||||||
|
|
||||||
|
# specify variables
|
||||||
|
summary_vars <- "B03002_001" # total population
|
||||||
|
if (census_var == "income") {
|
||||||
|
vars <- c(Income = "B19113_001")
|
||||||
|
} else if (census_var == "race") {
|
||||||
|
vars <- c(White = "B03002_003") #non-Hispanic white
|
||||||
|
}
|
||||||
|
|
||||||
|
# get census data
|
||||||
|
if (city_name == "New York") {
|
||||||
|
state = "NY"
|
||||||
|
counties <- c("New York County", "Kings County", "Queens County",
|
||||||
|
"Bronx County", "Richmond County")
|
||||||
|
|
||||||
|
new_york <- purrr::map(
|
||||||
|
counties,
|
||||||
|
~ get_acs(
|
||||||
|
state = state,
|
||||||
|
county = .x,
|
||||||
|
geography = "block group",
|
||||||
|
variables = vars,
|
||||||
|
summary_var = summary_vars,
|
||||||
|
geometry = TRUE
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
df_census_block_group <- bind_rows(new_york)
|
||||||
|
|
||||||
|
} else{
|
||||||
|
|
||||||
|
if (city_name == "Washington") {
|
||||||
|
county <- NULL
|
||||||
|
}
|
||||||
|
|
||||||
|
df_census_block_group <- get_acs(
|
||||||
|
state = state,
|
||||||
|
county = county,
|
||||||
|
geography = "block group",
|
||||||
|
variables = vars,
|
||||||
|
summary_var = summary_vars,
|
||||||
|
geometry = TRUE
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# add GIS features
|
||||||
|
df <- df %>%
|
||||||
|
filter(city == city_name) %>%
|
||||||
|
# ensure same coords as tidycensus
|
||||||
|
st_as_sf(
|
||||||
|
coords = c("lon", "lat"),
|
||||||
|
crs = 4269,
|
||||||
|
agr = "constant"
|
||||||
|
)
|
||||||
|
|
||||||
|
# annotate points with census data
|
||||||
|
if (census_var == "income") {
|
||||||
|
df <- st_join(
|
||||||
|
df,
|
||||||
|
df_census_block_group %>%
|
||||||
|
select(GEOID, NAME, median_household_income = estimate, geometry)
|
||||||
|
)
|
||||||
|
} else if (census_var == "race") {
|
||||||
|
df <- st_join(
|
||||||
|
df,
|
||||||
|
df_census_block_group %>%
|
||||||
|
transmute(
|
||||||
|
GEOID, NAME,
|
||||||
|
percentage_minority = (summary_est - estimate) / summary_est, geometry
|
||||||
|
)
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
df
|
||||||
|
}
|
||||||
280
analysis/results.Rmd
Normal file
280
analysis/results.Rmd
Normal file
|
|
@ -0,0 +1,280 @@
|
||||||
|
---
|
||||||
|
title: "results"
|
||||||
|
author: "Keniel Yao"
|
||||||
|
date: "4/26/2021"
|
||||||
|
output: html_document
|
||||||
|
---
|
||||||
|
|
||||||
|
```{r setup, include=FALSE}
|
||||||
|
knitr::opts_chunk$set(echo = TRUE)
|
||||||
|
```
|
||||||
|
|
||||||
|
```{r load-functions}
|
||||||
|
library(tidyverse)
|
||||||
|
library(sf)
|
||||||
|
library(glue)
|
||||||
|
library(tidycensus)
|
||||||
|
library(broom)
|
||||||
|
|
||||||
|
source(here::here('analysis', 'figures.R'))
|
||||||
|
|
||||||
|
theme_set(theme_bw(base_size = 14))
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
# Load data
|
||||||
|
|
||||||
|
```{r data}
|
||||||
|
df_pre <- read_csv(here::here("data", "cameras_2011-2015.csv")) %>%
|
||||||
|
mutate(period = "2011-2015")
|
||||||
|
df_post <- read_csv(here::here("data", "cameras_2015-2021.csv")) %>%
|
||||||
|
mutate(period = "2015-2021")
|
||||||
|
city_data <- read_csv(here::here("data", "city_metadata.csv"))
|
||||||
|
|
||||||
|
recall <- 0.63
|
||||||
|
```
|
||||||
|
|
||||||
|
# Figures
|
||||||
|
|
||||||
|
## Table 1: City metadata
|
||||||
|
|
||||||
|
```{r metadata}
|
||||||
|
city_data %>%
|
||||||
|
arrange(desc(type), desc(road_network_length_km)) %>%
|
||||||
|
transmute(
|
||||||
|
City = case_when(
|
||||||
|
city == "New York" ~ "New York City",
|
||||||
|
city == "Washington" ~ "Washington, D.C.",
|
||||||
|
TRUE ~ city
|
||||||
|
),
|
||||||
|
Population = formatC(round(population_census2010, -3), format = "d", big.mark=","),
|
||||||
|
`Area (sq. km)` = formatC(area_sqkm_census2010, format = "d", big.mark=","),
|
||||||
|
`Road length (km)` = formatC(road_network_length_km, format = "d", big.mark=",")
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Figure 5: Spatial distribution of sampled points
|
||||||
|
|
||||||
|
```{r sampled-points}
|
||||||
|
generate_sampled_point_map(df_post, "San Francisco")
|
||||||
|
generate_sampled_point_map(df_post, "Chicago")
|
||||||
|
generate_sampled_point_map(df_post, "New York")
|
||||||
|
```
|
||||||
|
|
||||||
|
## Table 3: Detection count, density and total camera estimates
|
||||||
|
|
||||||
|
```{r main-table}
|
||||||
|
bind_rows(
|
||||||
|
df_pre,
|
||||||
|
df_post
|
||||||
|
) %>%
|
||||||
|
group_by(city, period) %>%
|
||||||
|
summarize(
|
||||||
|
n_pano = n(),
|
||||||
|
n_detection = sum(camera_count)
|
||||||
|
) %>%
|
||||||
|
ungroup() %>%
|
||||||
|
estimate_detection_metrics(recall = recall) %>%
|
||||||
|
transmute(
|
||||||
|
rank = if_else(period == "2015-2021", est_detections_per_km, 0),
|
||||||
|
city = fct_reorder(city, - rank),
|
||||||
|
type,
|
||||||
|
period = if_else(period == "2015-2021", "2016-2020", period),
|
||||||
|
road_network_length_km = formatC(road_network_length_km, format = "d", big.mark=","),
|
||||||
|
m_per_pano = round(m_per_pano, 0),
|
||||||
|
n_detection,
|
||||||
|
est_detections_per_km = round(est_detections_per_km, 2),
|
||||||
|
se_detections_per_km = glue("({ round(se_detections_per_km, 2) })"),
|
||||||
|
est_detections = formatC(round(est_detections, -2), format = "d", big.mark=","),
|
||||||
|
se_detections = glue('({ formatC(round(se_detections, -2), format = "d", big.mark=",") })')
|
||||||
|
) %>%
|
||||||
|
pivot_wider(
|
||||||
|
id_cols = c(city, type, road_network_length_km, m_per_pano),
|
||||||
|
names_from = period,
|
||||||
|
values_from = c(n_detection, est_detections_per_km, se_detections_per_km, est_detections, se_detections)
|
||||||
|
) %>%
|
||||||
|
arrange(desc(type), city) %>%
|
||||||
|
mutate(
|
||||||
|
across(ends_with("2011-2015"), ~ str_replace_na(.x, "-")),
|
||||||
|
city = as.character(city)
|
||||||
|
) %>%
|
||||||
|
select(
|
||||||
|
city, road_network_length_km, m_per_pano,
|
||||||
|
`n_detection_2011-2015`, `n_detection_2016-2020`,
|
||||||
|
`est_detections_per_km_2011-2015`, `se_detections_per_km_2011-2015`,
|
||||||
|
`est_detections_per_km_2016-2020`, `se_detections_per_km_2016-2020`,
|
||||||
|
`est_detections_2011-2015`, `se_detections_2011-2015`,
|
||||||
|
`est_detections_2016-2020`, `se_detections_2016-2020`
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Figure 9: Maps of detected points
|
||||||
|
|
||||||
|
```{r detected-points}
|
||||||
|
generate_detected_point_map(df_post, "San Francisco")
|
||||||
|
generate_detected_point_map(df_post, "Chicago")
|
||||||
|
generate_detected_point_map(df_post, "New York")
|
||||||
|
```
|
||||||
|
|
||||||
|
## Figure 10: Pre-post estimated camera density
|
||||||
|
|
||||||
|
```{r density-plot}
|
||||||
|
df_post %>%
|
||||||
|
group_by(city, period) %>%
|
||||||
|
summarize(
|
||||||
|
n_pano = n(),
|
||||||
|
n_detection = sum(camera_count)
|
||||||
|
) %>%
|
||||||
|
ungroup() %>%
|
||||||
|
estimate_detection_metrics(recall = recall) %>%
|
||||||
|
mutate(
|
||||||
|
city = case_when(
|
||||||
|
city == "New York" ~ "New York City",
|
||||||
|
city == "Washington" ~ "Washington, D.C.",
|
||||||
|
T ~ city
|
||||||
|
),
|
||||||
|
type = factor(type, c("Global", "US")),
|
||||||
|
city = fct_reorder(city, est_detections_per_km)
|
||||||
|
) %>%
|
||||||
|
plot_camera_density(legend = FALSE)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Figure 11: Zone identification rate
|
||||||
|
|
||||||
|
```{r annotate-race-data}
|
||||||
|
us_cities <- city_data %>%
|
||||||
|
filter(type == "US") %>%
|
||||||
|
pull(city)
|
||||||
|
|
||||||
|
df_post_w_race <- us_cities %>%
|
||||||
|
map_dfr(~ annotate_points_with_census(df_post, .x, "race")) %>%
|
||||||
|
st_drop_geometry() %>%
|
||||||
|
mutate(
|
||||||
|
city = case_when(
|
||||||
|
city == "New York" ~ "New York City",
|
||||||
|
city == "Washington" ~ "Washington D.C.",
|
||||||
|
TRUE ~ city
|
||||||
|
),
|
||||||
|
city = factor(
|
||||||
|
city,
|
||||||
|
c("New York City", "San Francisco", "Boston", "Chicago", "Philadelphia",
|
||||||
|
"Washington D.C.", "Los Angeles", "Baltimore", "Seattle", "Milwaukee")
|
||||||
|
),
|
||||||
|
zone_type = str_to_title(zone_type),
|
||||||
|
zone_type = factor(
|
||||||
|
zone_type,
|
||||||
|
c("Public", "Residential", "Industrial", "Commercial", "Mixed"),
|
||||||
|
exclude = NULL
|
||||||
|
),
|
||||||
|
zone_type = fct_explicit_na(zone_type, na_level = "Unknown"),
|
||||||
|
camera_count = as.integer(camera_count)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
```{r zone-all}
|
||||||
|
df_post_w_race %>%
|
||||||
|
filter(zone_type != "Unknown") %>%
|
||||||
|
group_by(zone_type) %>%
|
||||||
|
summarize(
|
||||||
|
total = n(),
|
||||||
|
total_identified = sum(camera_count, na.rm=T),
|
||||||
|
perc_detected = sum(total_identified) / total
|
||||||
|
) %>%
|
||||||
|
mutate(se = sqrt(perc_detected * (1 - perc_detected) / total)) %>%
|
||||||
|
ungroup() %>%
|
||||||
|
mutate(
|
||||||
|
zone_type = fct_relevel(
|
||||||
|
zone_type,
|
||||||
|
c("Mixed", "Commercial", "Industrial", "Public", "Residential", "Unknown")
|
||||||
|
),
|
||||||
|
zone_type = fct_rev(zone_type)
|
||||||
|
) %>%
|
||||||
|
ggplot(aes(x = zone_type, y = perc_detected)) +
|
||||||
|
geom_point() +
|
||||||
|
geom_pointrange(aes(
|
||||||
|
ymin = perc_detected - 1.96 * se,
|
||||||
|
ymax = perc_detected + 1.96 * se
|
||||||
|
)) +
|
||||||
|
scale_x_discrete(name = "") +
|
||||||
|
scale_y_continuous(
|
||||||
|
name = "Identification rate",
|
||||||
|
position = "right",
|
||||||
|
labels = scales::percent_format(accuracy = 0.01),
|
||||||
|
expand = expansion(mult = c(0, 0.1)),
|
||||||
|
limits = c(0, NA)
|
||||||
|
) +
|
||||||
|
coord_flip() +
|
||||||
|
theme(
|
||||||
|
panel.grid = element_blank(),
|
||||||
|
panel.border = element_blank(),
|
||||||
|
axis.text = element_text(family = "Helvetica", color = "black"),
|
||||||
|
axis.title.x = element_text(family = "Helvetica", color = "black"),
|
||||||
|
axis.line = element_line(size = 0.5, color = "black"),
|
||||||
|
axis.ticks = element_line(size = 0.5, color = "black")
|
||||||
|
)
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
## Figure 12: Race identification rate
|
||||||
|
|
||||||
|
```{r race-all}
|
||||||
|
df_post_w_race %>%
|
||||||
|
ggplot(aes(x = percentage_minority, y = camera_count)) +
|
||||||
|
geom_smooth(
|
||||||
|
method = "lm",
|
||||||
|
formula = y ~ poly(x, degree = 2),
|
||||||
|
se = TRUE
|
||||||
|
) +
|
||||||
|
scale_x_continuous(
|
||||||
|
name = "Minority share of population (census block group)",
|
||||||
|
expand = expansion(mult = c(0, 0.05)),
|
||||||
|
labels = scales::percent_format(accuracy = 1)
|
||||||
|
) +
|
||||||
|
scale_y_continuous(
|
||||||
|
name = "Identification rate",
|
||||||
|
limits = c(0, NA),
|
||||||
|
oob = scales::squish,
|
||||||
|
expand = expansion(mult = c(0, 0.1)),
|
||||||
|
labels = scales::percent_format(accuracy = 0.1)
|
||||||
|
) +
|
||||||
|
theme(
|
||||||
|
panel.grid = element_blank(),
|
||||||
|
panel.border = element_blank(),
|
||||||
|
axis.text = element_text(family = "Helvetica", color = "black"),
|
||||||
|
axis.title = element_text(family = "Helvetica", color = "black"),
|
||||||
|
axis.line = element_line(size = 0.5, color = "black"),
|
||||||
|
axis.ticks.x = element_line(size = 0.5, color = "black"),
|
||||||
|
axis.ticks.y = element_line(size = 0.5, color = "black")
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Table 4: Regression output
|
||||||
|
|
||||||
|
```{r regression-model}
|
||||||
|
# reference level:
|
||||||
|
# - city: None (interceptless)
|
||||||
|
# - zone_type: residential
|
||||||
|
model_lm_poly <- df_post_w_race %>%
|
||||||
|
filter(zone_type != "Unknown") %>%
|
||||||
|
mutate(
|
||||||
|
detected = if_else(camera_count > 0, 1, 0),
|
||||||
|
zone_type = fct_relevel(
|
||||||
|
zone_type,
|
||||||
|
c("Residential", "Public", "Commercial", "Industrial", "Mixed", "Unknown")
|
||||||
|
)
|
||||||
|
) %>%
|
||||||
|
lm(detected ~ city-1 + zone_type + percentage_minority + I(percentage_minority^2), data = .)
|
||||||
|
|
||||||
|
tidy(model_lm_poly) %>%
|
||||||
|
filter(!str_detect(term, "^city")) %>%
|
||||||
|
transmute(
|
||||||
|
term,
|
||||||
|
estimate = formatC(estimate, format = "f"),
|
||||||
|
std.error = formatC(std.error, format = "f")
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
0
data/image/.keepme
Normal file
0
data/image/.keepme
Normal file
22
data/info.yaml
Normal file
22
data/info.yaml
Normal file
|
|
@ -0,0 +1,22 @@
|
||||||
|
author: Hao
|
||||||
|
class_names:
|
||||||
|
- Directed Camera
|
||||||
|
- Dome Camera
|
||||||
|
date: 2021-04-06
|
||||||
|
description: Camera detection dataset
|
||||||
|
name: camera-detection
|
||||||
|
sources:
|
||||||
|
- channels: null
|
||||||
|
date: null
|
||||||
|
height: 640
|
||||||
|
name: gsv
|
||||||
|
resolution: ''
|
||||||
|
width: 640
|
||||||
|
task:
|
||||||
|
- object detection
|
||||||
|
version:
|
||||||
|
description: Camera detection dataset
|
||||||
|
major: 1
|
||||||
|
minor: 0
|
||||||
|
patch: 0
|
||||||
|
version_str: 1.0.0
|
||||||
3156
data/meta.csv
Normal file
3156
data/meta.csv
Normal file
File diff suppressed because it is too large
Load diff
13
detection/data/__init__.py
Normal file
13
detection/data/__init__.py
Normal file
|
|
@ -0,0 +1,13 @@
|
||||||
|
import pandas as pd
|
||||||
|
import os
|
||||||
|
|
||||||
|
from .version import Version
|
||||||
|
from .base import BaseDataset
|
||||||
|
from .info import DatasetInfo
|
||||||
|
from . import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def get_dataset(split="train"):
|
||||||
|
meta = pd.read_csv("../data/meta.csv")
|
||||||
|
info = DatasetInfo.load("../data/info.yaml")
|
||||||
|
return BaseDataset(info, meta)[split]
|
||||||
77
detection/data/base.py
Normal file
77
detection/data/base.py
Normal file
|
|
@ -0,0 +1,77 @@
|
||||||
|
import numpy as np
|
||||||
|
import os
|
||||||
|
from PIL import Image
|
||||||
|
from tqdm import tqdm
|
||||||
|
from torch.utils.data import Dataset
|
||||||
|
|
||||||
|
from .info import DatasetInfoMixin
|
||||||
|
from .detection import DetectionMixin
|
||||||
|
from .util import _is_path
|
||||||
|
|
||||||
|
|
||||||
|
class BaseDataset(Dataset,
|
||||||
|
DatasetInfoMixin,
|
||||||
|
DetectionMixin):
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
info,
|
||||||
|
meta,
|
||||||
|
split=None,
|
||||||
|
):
|
||||||
|
DatasetInfoMixin.__init__(self,
|
||||||
|
info=info,
|
||||||
|
meta=meta,
|
||||||
|
split=split)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _load_image_file(file_path):
|
||||||
|
if not _is_path(file_path):
|
||||||
|
return None
|
||||||
|
image_pil = Image.open(file_path).convert('RGB')
|
||||||
|
image_np = np.array(image_pil)
|
||||||
|
return image_np
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _load_pickle_file(file_path):
|
||||||
|
with open(file_path, 'rb') as f:
|
||||||
|
data = pickle.load(f)
|
||||||
|
return data
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _load_numpy_file(file_path):
|
||||||
|
data = np.load(file_path)
|
||||||
|
return data
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _load_single_image(cls, sample_dict):
|
||||||
|
new_sample_dict = {}
|
||||||
|
for k, v in sample_dict.items():
|
||||||
|
if k.endswith("image_path"):
|
||||||
|
new_sample_dict[k.replace(
|
||||||
|
"_image_path", "_image")] = cls._load_image_file(v)
|
||||||
|
else:
|
||||||
|
new_sample_dict[k] = v
|
||||||
|
return new_sample_dict
|
||||||
|
|
||||||
|
def __getitem__(self, index):
|
||||||
|
if isinstance(index, str):
|
||||||
|
return self.get_split(index)
|
||||||
|
elif isinstance(index, slice):
|
||||||
|
return self.slice(index)
|
||||||
|
|
||||||
|
sample = self._meta.iloc[index].to_dict()
|
||||||
|
|
||||||
|
# Replace Nan
|
||||||
|
# TODO
|
||||||
|
|
||||||
|
# Load Images
|
||||||
|
sample = self._load_single_image(sample)
|
||||||
|
|
||||||
|
# Apply Format
|
||||||
|
if isinstance(self._format, list):
|
||||||
|
sample = {k: v for k, v in sample.items() if k in self._format}
|
||||||
|
elif isinstance(self._format, dict):
|
||||||
|
sample = {self._format[k]: v for k,
|
||||||
|
v in sample.items() if k in self._format}
|
||||||
|
|
||||||
|
return sample
|
||||||
1
detection/data/constants.py
Normal file
1
detection/data/constants.py
Normal file
|
|
@ -0,0 +1 @@
|
||||||
|
ANNOTATION_COLUMN = "annotations"
|
||||||
79
detection/data/detection.py
Normal file
79
detection/data/detection.py
Normal file
|
|
@ -0,0 +1,79 @@
|
||||||
|
import torch
|
||||||
|
from torch.utils.data import Dataset
|
||||||
|
|
||||||
|
from .info import DatasetInfoMixin
|
||||||
|
from . import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def trivial_batch_collator(batch):
|
||||||
|
return batch
|
||||||
|
|
||||||
|
|
||||||
|
class DetectionMixin:
|
||||||
|
def detection_dataloader(self,
|
||||||
|
augmentations=None,
|
||||||
|
is_train=True,
|
||||||
|
use_instance_mask=False,
|
||||||
|
image_path_col=None,
|
||||||
|
**kwargs):
|
||||||
|
from detectron2.data import DatasetMapper
|
||||||
|
if augmentations is None:
|
||||||
|
augmentations = []
|
||||||
|
mapper = DatasetMapper(is_train=is_train,
|
||||||
|
image_format="RGB",
|
||||||
|
use_instance_mask=use_instance_mask,
|
||||||
|
instance_mask_format="bitmask",
|
||||||
|
augmentations=augmentations
|
||||||
|
)
|
||||||
|
return DetectionDataset(info=self.info,
|
||||||
|
meta=self.meta,
|
||||||
|
split=self.split,
|
||||||
|
image_path_col=image_path_col,
|
||||||
|
mapper=mapper) \
|
||||||
|
.dataloader(**kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class DetectionDataset(Dataset, DatasetInfoMixin):
|
||||||
|
"""
|
||||||
|
Dataset class that provides standard Detectron2 model input format:
|
||||||
|
https://detectron2.readthedocs.io/en/latest/tutorials/models.html?highlight=input%20format#model-input-format
|
||||||
|
Notice the annotation column in the meta file need to follow Detectron2's
|
||||||
|
standard dataset dict format:
|
||||||
|
https://detectron2.readthedocs.io/en/latest/tutorials/datasets.html#standard-dataset-dicts
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, info, meta, mapper, split=None, image_path_col=None):
|
||||||
|
if C.ANNOTATION_COLUMN not in meta.columns:
|
||||||
|
raise ValueError(f"[{C.ANNOTATION_COLUMN}] column not found in the meta data.")
|
||||||
|
|
||||||
|
if image_path_col is None:
|
||||||
|
image_path_cols = [
|
||||||
|
c for c in meta.columns if c.endswith("image_path")]
|
||||||
|
if len(image_path_cols) == 0:
|
||||||
|
raise ValueError(
|
||||||
|
"No image path column found in the meta data. Please check meta data and use `image_path_col` argument to specify the column.")
|
||||||
|
elif len(image_path_cols) > 1:
|
||||||
|
raise ValueError(
|
||||||
|
"Multiple image path columns found in the meta data. Please use `image_path_col` argument to specify the column.")
|
||||||
|
else:
|
||||||
|
image_path_col = image_path_cols[0]
|
||||||
|
|
||||||
|
meta = meta.rename(columns={image_path_col: "file_name"})
|
||||||
|
|
||||||
|
self.mapper = mapper
|
||||||
|
|
||||||
|
DatasetInfoMixin.__init__(self,
|
||||||
|
info=info,
|
||||||
|
meta=meta,
|
||||||
|
split=split)
|
||||||
|
|
||||||
|
def __getitem__(self, index):
|
||||||
|
sample = self._meta.iloc[index].to_dict()
|
||||||
|
sample[C.ANNOTATION_COLUMN] = eval(sample[C.ANNOTATION_COLUMN])
|
||||||
|
return self.mapper(sample)
|
||||||
|
|
||||||
|
def dataloader(self, **kwargs):
|
||||||
|
return torch.utils.data.DataLoader(
|
||||||
|
self,
|
||||||
|
collate_fn=trivial_batch_collator,
|
||||||
|
**kwargs)
|
||||||
178
detection/data/info.py
Normal file
178
detection/data/info.py
Normal file
|
|
@ -0,0 +1,178 @@
|
||||||
|
import yaml
|
||||||
|
import dataclasses
|
||||||
|
import pandas as pd
|
||||||
|
from copy import deepcopy
|
||||||
|
from dataclasses import asdict, dataclass, field
|
||||||
|
from typing import List, Optional, Union
|
||||||
|
|
||||||
|
from .version import Version
|
||||||
|
|
||||||
|
|
||||||
|
class BaseInfo:
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, dataset_info_dict: dict) -> "DatasetInfo":
|
||||||
|
field_names = set(f.name for f in dataclasses.fields(cls))
|
||||||
|
return cls(
|
||||||
|
**{k: v for k, v in dataset_info_dict.items() if k in field_names})
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class ImageSourceInfo(BaseInfo):
|
||||||
|
# Required Fields
|
||||||
|
name: str = field(default_factory=str)
|
||||||
|
height: int = field(default_factory=int)
|
||||||
|
width: int = field(default_factory=int)
|
||||||
|
date: str = field(default_factory=str)
|
||||||
|
# Optional Fields
|
||||||
|
channels: Optional[list] = None
|
||||||
|
resolution: Optional[str] = field(default_factory=str)
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class DatasetInfo(BaseInfo):
|
||||||
|
name: str = field(default_factory=str)
|
||||||
|
description: str = field(default_factory=str)
|
||||||
|
author: str = field(default_factory=str)
|
||||||
|
version: Union[str, Version] = field(default_factory=Version)
|
||||||
|
date: str = field(default_factory=str)
|
||||||
|
task: List[str] = field(default_factory=list)
|
||||||
|
class_names: List[str] = field(default_factory=list)
|
||||||
|
sources: List[ImageSourceInfo] = field(default_factory=ImageSourceInfo)
|
||||||
|
|
||||||
|
def __post_init__(self):
|
||||||
|
if self.version is not None and not isinstance(self.version, Version):
|
||||||
|
if isinstance(self.version, str):
|
||||||
|
self.version = Version(self.version)
|
||||||
|
else:
|
||||||
|
self.version = Version.from_dict(self.version)
|
||||||
|
if self.sources is not None and not all(
|
||||||
|
[isinstance(s, ImageSourceInfo) for s in self.sources]):
|
||||||
|
sources = []
|
||||||
|
for source in self.sources:
|
||||||
|
if isinstance(source, ImageSourceInfo):
|
||||||
|
pass
|
||||||
|
elif isinstance(source, dict):
|
||||||
|
source = ImageSourceInfo.from_dict(source)
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"Unknown type for ImageSourceInfo: {type(source)}")
|
||||||
|
sources.append(source)
|
||||||
|
self.sources = sources
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def load(cls, path):
|
||||||
|
with open(path, "r") as f:
|
||||||
|
yaml_dict = yaml.load(f, Loader=yaml.SafeLoader)
|
||||||
|
return cls.from_dict(yaml_dict)
|
||||||
|
|
||||||
|
def save(self, path):
|
||||||
|
with open(path, "w") as f:
|
||||||
|
yaml.dump(asdict(self), f)
|
||||||
|
|
||||||
|
def dump(self, fileobj):
|
||||||
|
yaml.dump(asdict(self), fileobj)
|
||||||
|
|
||||||
|
|
||||||
|
class DatasetInfoMixin:
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
info: DatasetInfo,
|
||||||
|
meta: pd.DataFrame,
|
||||||
|
split: Optional[str] = None):
|
||||||
|
self._info = info
|
||||||
|
self._meta = meta
|
||||||
|
self._split = split
|
||||||
|
self._format = None
|
||||||
|
|
||||||
|
if self._split is not None and self._split != 'all':
|
||||||
|
self._meta.query(f"split == '{self._split}'", inplace=True)
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self._meta)
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
features = self.features
|
||||||
|
if len(features) < 5:
|
||||||
|
features_repr = "[" + ", ".join(features) + "]"
|
||||||
|
else:
|
||||||
|
features_repr = "[" + \
|
||||||
|
", ".join(features[:3] + ["...", features[-1]]) + "]"
|
||||||
|
return f"{type(self).__name__}(split: {self.split}, version: {self.version}, features[{len(features)}]: {features_repr}, samples: {self.__len__()})"
|
||||||
|
|
||||||
|
def get_split(self, split):
|
||||||
|
if split == "all":
|
||||||
|
return self
|
||||||
|
elif split in self.splits:
|
||||||
|
result = self.query(f"split == '{split}'")
|
||||||
|
result._split = split
|
||||||
|
return result
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"Unknown split {split}. Split has to be one of {list(self.splits.keys())}")
|
||||||
|
|
||||||
|
def slice(self, expr):
|
||||||
|
result = deepcopy(self)
|
||||||
|
result._meta = result._meta.iloc[expr]
|
||||||
|
return result
|
||||||
|
|
||||||
|
def query(self, expr):
|
||||||
|
result = deepcopy(self)
|
||||||
|
result._meta = result._meta.query(expr)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def filter(self, func):
|
||||||
|
result = deepcopy(self)
|
||||||
|
result._meta = result._meta[result._meta.apply(func, 1)].reset_index()
|
||||||
|
return result
|
||||||
|
|
||||||
|
def set_format(self, columns: Union[dict, list]):
|
||||||
|
self._format = columns
|
||||||
|
|
||||||
|
def reset_format(self):
|
||||||
|
self.set_format(None)
|
||||||
|
|
||||||
|
def value_counts(self, value):
|
||||||
|
return self._meta[value].value_counts().to_dict()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def info(self):
|
||||||
|
return self._info
|
||||||
|
|
||||||
|
@property
|
||||||
|
def meta(self):
|
||||||
|
return self._meta.copy()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def name(self):
|
||||||
|
return self._info.name
|
||||||
|
|
||||||
|
@property
|
||||||
|
def version(self):
|
||||||
|
return self._info.version
|
||||||
|
|
||||||
|
@property
|
||||||
|
def description(self):
|
||||||
|
return self._info.description
|
||||||
|
|
||||||
|
@property
|
||||||
|
def author(self):
|
||||||
|
return self._info.author
|
||||||
|
|
||||||
|
@property
|
||||||
|
def sources(self):
|
||||||
|
return [s.name for s in self._info.sources]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def split(self):
|
||||||
|
if self._split is None:
|
||||||
|
return "all"
|
||||||
|
return self._split
|
||||||
|
|
||||||
|
@property
|
||||||
|
def splits(self):
|
||||||
|
return self.value_counts("split")
|
||||||
|
|
||||||
|
@property
|
||||||
|
def features(self):
|
||||||
|
features = list(self._meta.columns)
|
||||||
|
return features
|
||||||
6
detection/data/util.py
Normal file
6
detection/data/util.py
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
from pathlib import Path, PosixPath
|
||||||
|
|
||||||
|
|
||||||
|
def _is_path(file_path):
|
||||||
|
return isinstance(file_path, (str, PosixPath))
|
||||||
|
|
||||||
99
detection/data/version.py
Normal file
99
detection/data/version.py
Normal file
|
|
@ -0,0 +1,99 @@
|
||||||
|
""" Adapted from
|
||||||
|
https://github.com/huggingface/datasets/blob/master/src/datasets/utils/version.py
|
||||||
|
"""
|
||||||
|
import dataclasses
|
||||||
|
import re
|
||||||
|
from dataclasses import dataclass
|
||||||
|
|
||||||
|
|
||||||
|
_VERSION_TMPL = r"^(?P<major>{v})" r"\.(?P<minor>{v})" r"\.(?P<patch>{v})$"
|
||||||
|
_VERSION_WILDCARD_REG = re.compile(_VERSION_TMPL.format(v=r"\d+|\*"))
|
||||||
|
_VERSION_RESOLVED_REG = re.compile(_VERSION_TMPL.format(v=r"\d+"))
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass()
|
||||||
|
class Version:
|
||||||
|
"""Dataset version MAJOR.MINOR.PATCH.
|
||||||
|
Args:
|
||||||
|
version_str: string. Eg: "1.2.3".
|
||||||
|
description: string, a description of what is new in this version.
|
||||||
|
"""
|
||||||
|
|
||||||
|
version_str: str
|
||||||
|
description: str = None
|
||||||
|
major: str = None
|
||||||
|
minor: str = None
|
||||||
|
patch: str = None
|
||||||
|
|
||||||
|
def __post_init__(self):
|
||||||
|
self.major, self.minor, self.patch = _str_to_version(self.version_str)
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return "{}.{}.{}".format(*self.tuple)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def tuple(self):
|
||||||
|
return self.major, self.minor, self.patch
|
||||||
|
|
||||||
|
def _validate_operand(self, other):
|
||||||
|
if isinstance(other, str):
|
||||||
|
return Version(other)
|
||||||
|
elif isinstance(other, Version):
|
||||||
|
return other
|
||||||
|
raise AssertionError("{} (type {}) cannot be compared to version.".format(other, type(other)))
|
||||||
|
|
||||||
|
def __hash__(self):
|
||||||
|
return hash(self.tuple)
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple == other.tuple
|
||||||
|
|
||||||
|
def __ne__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple != other.tuple
|
||||||
|
|
||||||
|
def __lt__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple < other.tuple
|
||||||
|
|
||||||
|
def __le__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple <= other.tuple
|
||||||
|
|
||||||
|
def __gt__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple > other.tuple
|
||||||
|
|
||||||
|
def __ge__(self, other):
|
||||||
|
other = self._validate_operand(other)
|
||||||
|
return self.tuple >= other.tuple
|
||||||
|
|
||||||
|
def match(self, other_version):
|
||||||
|
"""Returns True if other_version matches.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
other_version: string, of the form "x[.y[.x]]" where {x,y,z} can be a
|
||||||
|
number or a wildcard.
|
||||||
|
"""
|
||||||
|
major, minor, patch = _str_to_version(other_version, allow_wildcard=True)
|
||||||
|
return major in [self.major, "*"] and minor in [self.minor, "*"] and patch in [self.patch, "*"]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, dic):
|
||||||
|
field_names = set(f.name for f in dataclasses.fields(cls))
|
||||||
|
return cls(**{k: v for k, v in dic.items() if k in field_names})
|
||||||
|
|
||||||
|
|
||||||
|
def _str_to_version(version_str, allow_wildcard=False):
|
||||||
|
"""Return the tuple (major, minor, patch) version extracted from the str."""
|
||||||
|
reg = _VERSION_WILDCARD_REG if allow_wildcard else _VERSION_RESOLVED_REG
|
||||||
|
res = reg.match(version_str)
|
||||||
|
if not res:
|
||||||
|
msg = "Invalid version '{}'. Format should be x.y.z".format(version_str)
|
||||||
|
if allow_wildcard:
|
||||||
|
msg += " with {x,y,z} being digits or wildcard."
|
||||||
|
else:
|
||||||
|
msg += " with {x,y,z} being digits."
|
||||||
|
raise ValueError(msg)
|
||||||
|
return tuple(v if v == "*" else int(v) for v in [res.group("major"), res.group("minor"), res.group("patch")])
|
||||||
2
detection/eval/__init__.py
Normal file
2
detection/eval/__init__.py
Normal file
|
|
@ -0,0 +1,2 @@
|
||||||
|
from .loss import get_loss_fn
|
||||||
|
from .evaluator import *
|
||||||
4
detection/eval/detection/__init__.py
Normal file
4
detection/eval/detection/__init__.py
Normal file
|
|
@ -0,0 +1,4 @@
|
||||||
|
# Adapted from https://github.com/rafaelpadilla/Object-Detection-Metrics
|
||||||
|
from .evaluator import Evaluator
|
||||||
|
from .bbox import BoundingBox, BoundingBoxes
|
||||||
|
from .utils import BBType, BBFormat, CoordinatesType
|
||||||
232
detection/eval/detection/bbox.py
Normal file
232
detection/eval/detection/bbox.py
Normal file
|
|
@ -0,0 +1,232 @@
|
||||||
|
from .utils import *
|
||||||
|
|
||||||
|
|
||||||
|
class BoundingBox:
|
||||||
|
def __init__(self,
|
||||||
|
imageName,
|
||||||
|
classId,
|
||||||
|
x,
|
||||||
|
y,
|
||||||
|
w,
|
||||||
|
h,
|
||||||
|
typeCoordinates=CoordinatesType.Absolute,
|
||||||
|
imgSize=None,
|
||||||
|
bbType=BBType.GroundTruth,
|
||||||
|
classConfidence=None,
|
||||||
|
format=BBFormat.XYWH):
|
||||||
|
"""Constructor.
|
||||||
|
Args:
|
||||||
|
imageName: String representing the image name.
|
||||||
|
classId: String value representing class id.
|
||||||
|
x: Float value representing the X upper-left coordinate of the bounding box.
|
||||||
|
y: Float value representing the Y upper-left coordinate of the bounding box.
|
||||||
|
w: Float value representing the width bounding box.
|
||||||
|
h: Float value representing the height bounding box.
|
||||||
|
typeCoordinates: (optional) Enum (Relative or Absolute) represents if the bounding box
|
||||||
|
coordinates (x,y,w,h) are absolute or relative to size of the image. Default:'Absolute'.
|
||||||
|
imgSize: (optional) 2D vector (width, height)=>(int, int) represents the size of the
|
||||||
|
image of the bounding box. If typeCoordinates is 'Relative', imgSize is required.
|
||||||
|
bbType: (optional) Enum (Groundtruth or Detection) identifies if the bounding box
|
||||||
|
represents a ground truth or a detection. If it is a detection, the classConfidence has
|
||||||
|
to be informed.
|
||||||
|
classConfidence: (optional) Float value representing the confidence of the detected
|
||||||
|
class. If detectionType is Detection, classConfidence needs to be informed.
|
||||||
|
format: (optional) Enum (BBFormat.XYWH or BBFormat.XYX2Y2) indicating the format of the
|
||||||
|
coordinates of the bounding boxes. BBFormat.XYWH: <left> <top> <width> <height>
|
||||||
|
BBFormat.XYX2Y2: <left> <top> <right> <bottom>.
|
||||||
|
"""
|
||||||
|
self._imageName = imageName
|
||||||
|
self._typeCoordinates = typeCoordinates
|
||||||
|
if typeCoordinates == CoordinatesType.Relative and imgSize is None:
|
||||||
|
raise IOError(
|
||||||
|
'Parameter \'imgSize\' is required. It is necessary to inform the image size.')
|
||||||
|
if bbType == BBType.Detected and classConfidence is None:
|
||||||
|
raise IOError(
|
||||||
|
'For bbType=\'Detection\', it is necessary to inform the classConfidence value.')
|
||||||
|
# if classConfidence != None and (classConfidence < 0 or classConfidence > 1):
|
||||||
|
# raise IOError('classConfidence value must be a real value between 0 and 1. Value: %f' %
|
||||||
|
# classConfidence)
|
||||||
|
|
||||||
|
self._classConfidence = classConfidence
|
||||||
|
self._bbType = bbType
|
||||||
|
self._classId = classId
|
||||||
|
self._format = format
|
||||||
|
|
||||||
|
# If relative coordinates, convert to absolute values
|
||||||
|
# For relative coords: (x,y,w,h)=(X_center/img_width ,
|
||||||
|
# Y_center/img_height)
|
||||||
|
if (typeCoordinates == CoordinatesType.Relative):
|
||||||
|
(self._x, self._y, self._w, self._h) = convertToAbsoluteValues(
|
||||||
|
imgSize, (x, y, w, h))
|
||||||
|
self._width_img = imgSize[0]
|
||||||
|
self._height_img = imgSize[1]
|
||||||
|
if format == BBFormat.XYWH:
|
||||||
|
self._x2 = self._w
|
||||||
|
self._y2 = self._h
|
||||||
|
self._w = self._x2 - self._x
|
||||||
|
self._h = self._y2 - self._y
|
||||||
|
else:
|
||||||
|
raise IOError(
|
||||||
|
'For relative coordinates, the format must be XYWH (x,y,width,height)')
|
||||||
|
# For absolute coords: (x,y,w,h)=real bb coords
|
||||||
|
else:
|
||||||
|
self._x = x
|
||||||
|
self._y = y
|
||||||
|
if format == BBFormat.XYWH:
|
||||||
|
self._w = w
|
||||||
|
self._h = h
|
||||||
|
self._x2 = self._x + self._w
|
||||||
|
self._y2 = self._y + self._h
|
||||||
|
else: # format == BBFormat.XYX2Y2: <left> <top> <right> <bottom>.
|
||||||
|
self._x2 = w
|
||||||
|
self._y2 = h
|
||||||
|
self._w = self._x2 - self._x
|
||||||
|
self._h = self._y2 - self._y
|
||||||
|
if imgSize is None:
|
||||||
|
self._width_img = None
|
||||||
|
self._height_img = None
|
||||||
|
else:
|
||||||
|
self._width_img = imgSize[0]
|
||||||
|
self._height_img = imgSize[1]
|
||||||
|
|
||||||
|
def getAbsoluteBoundingBox(self, format=BBFormat.XYWH):
|
||||||
|
if format == BBFormat.XYWH:
|
||||||
|
return (self._x, self._y, self._w, self._h)
|
||||||
|
elif format == BBFormat.XYX2Y2:
|
||||||
|
return (self._x, self._y, self._x2, self._y2)
|
||||||
|
|
||||||
|
def getRelativeBoundingBox(self, imgSize=None):
|
||||||
|
if imgSize is None and self._width_img is None and self._height_img is None:
|
||||||
|
raise IOError(
|
||||||
|
'Parameter \'imgSize\' is required. It is necessary to inform the image size.')
|
||||||
|
if imgSize is not None:
|
||||||
|
return convertToRelativeValues(
|
||||||
|
(imgSize[0], imgSize[1]), (self._x, self._x2, self._y, self._y2))
|
||||||
|
else:
|
||||||
|
return convertToRelativeValues(
|
||||||
|
(self._width_img, self._height_img), (self._x, self._x2, self._y, self._y2))
|
||||||
|
|
||||||
|
def getImageName(self):
|
||||||
|
return self._imageName
|
||||||
|
|
||||||
|
def getConfidence(self):
|
||||||
|
return self._classConfidence
|
||||||
|
|
||||||
|
def getFormat(self):
|
||||||
|
return self._format
|
||||||
|
|
||||||
|
def getClassId(self):
|
||||||
|
return self._classId
|
||||||
|
|
||||||
|
def getImageSize(self):
|
||||||
|
return (self._width_img, self._height_img)
|
||||||
|
|
||||||
|
def getCoordinatesType(self):
|
||||||
|
return self._typeCoordinates
|
||||||
|
|
||||||
|
def getBBType(self):
|
||||||
|
return self._bbType
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def compare(det1, det2):
|
||||||
|
det1BB = det1.getAbsoluteBoundingBox()
|
||||||
|
det1ImgSize = det1.getImageSize()
|
||||||
|
det2BB = det2.getAbsoluteBoundingBox()
|
||||||
|
det2ImgSize = det2.getImageSize()
|
||||||
|
|
||||||
|
if det1.getClassId() == det2.getClassId() and \
|
||||||
|
det1.classConfidence == det2.classConfidenc() and \
|
||||||
|
det1BB[0] == det2BB[0] and \
|
||||||
|
det1BB[1] == det2BB[1] and \
|
||||||
|
det1BB[2] == det2BB[2] and \
|
||||||
|
det1BB[3] == det2BB[3] and \
|
||||||
|
det1ImgSize[0] == det1ImgSize[0] and \
|
||||||
|
det2ImgSize[1] == det2ImgSize[1]:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def clone(boundingBox):
|
||||||
|
absBB = boundingBox.getAbsoluteBoundingBox(format=BBFormat.XYWH)
|
||||||
|
# return (self._x,self._y,self._x2,self._y2)
|
||||||
|
newBoundingBox = BoundingBox(
|
||||||
|
boundingBox.getImageName(),
|
||||||
|
boundingBox.getClassId(),
|
||||||
|
absBB[0],
|
||||||
|
absBB[1],
|
||||||
|
absBB[2],
|
||||||
|
absBB[3],
|
||||||
|
typeCoordinates=boundingBox.getCoordinatesType(),
|
||||||
|
imgSize=boundingBox.getImageSize(),
|
||||||
|
bbType=boundingBox.getBBType(),
|
||||||
|
classConfidence=boundingBox.getConfidence(),
|
||||||
|
format=BBFormat.XYWH)
|
||||||
|
return newBoundingBox
|
||||||
|
|
||||||
|
|
||||||
|
class BoundingBoxes:
|
||||||
|
def __init__(self):
|
||||||
|
self._boundingBoxes = []
|
||||||
|
|
||||||
|
def addBoundingBox(self, bb):
|
||||||
|
self._boundingBoxes.append(bb)
|
||||||
|
|
||||||
|
def removeBoundingBox(self, _boundingBox):
|
||||||
|
for d in self._boundingBoxes:
|
||||||
|
if BoundingBox.compare(d, _boundingBox):
|
||||||
|
del self._boundingBoxes[d]
|
||||||
|
return
|
||||||
|
|
||||||
|
def removeAllBoundingBoxes(self):
|
||||||
|
self._boundingBoxes = []
|
||||||
|
|
||||||
|
def getBoundingBoxes(self):
|
||||||
|
return self._boundingBoxes
|
||||||
|
|
||||||
|
def getBoundingBoxByClass(self, classId):
|
||||||
|
boundingBoxes = []
|
||||||
|
for d in self._boundingBoxes:
|
||||||
|
if d.getClassId() == classId: # get only specified bounding box type
|
||||||
|
boundingBoxes.append(d)
|
||||||
|
return boundingBoxes
|
||||||
|
|
||||||
|
def getClasses(self):
|
||||||
|
classes = []
|
||||||
|
for d in self._boundingBoxes:
|
||||||
|
c = d.getClassId()
|
||||||
|
if c not in classes:
|
||||||
|
classes.append(c)
|
||||||
|
return classes
|
||||||
|
|
||||||
|
def getBoundingBoxesByType(self, bbType):
|
||||||
|
# get only specified bb type
|
||||||
|
return [d for d in self._boundingBoxes if d.getBBType() == bbType]
|
||||||
|
|
||||||
|
def getBoundingBoxesByImageName(self, imageName):
|
||||||
|
# get only specified bb type
|
||||||
|
return [d for d in self._boundingBoxes if d.getImageName() == imageName]
|
||||||
|
|
||||||
|
def count(self, bbType=None):
|
||||||
|
if bbType is None: # Return all bounding boxes
|
||||||
|
return len(self._boundingBoxes)
|
||||||
|
count = 0
|
||||||
|
for d in self._boundingBoxes:
|
||||||
|
if d.getBBType() == bbType: # get only specified bb type
|
||||||
|
count += 1
|
||||||
|
return count
|
||||||
|
|
||||||
|
def clone(self):
|
||||||
|
newBoundingBoxes = BoundingBoxes()
|
||||||
|
for d in self._boundingBoxes:
|
||||||
|
det = BoundingBox.clone(d)
|
||||||
|
newBoundingBoxes.addBoundingBox(det)
|
||||||
|
return newBoundingBoxes
|
||||||
|
|
||||||
|
def drawAllBoundingBoxes(self, image, imageName):
|
||||||
|
bbxes = self.getBoundingBoxesByImageName(imageName)
|
||||||
|
for bb in bbxes:
|
||||||
|
if bb.getBBType() == BBType.GroundTruth: # if ground truth
|
||||||
|
image = add_bb_into_image(image, bb, color=(0, 255, 0)) # green
|
||||||
|
else: # if detection
|
||||||
|
image = add_bb_into_image(image, bb, color=(255, 0, 0)) # red
|
||||||
|
return image
|
||||||
359
detection/eval/detection/evaluator.py
Normal file
359
detection/eval/detection/evaluator.py
Normal file
|
|
@ -0,0 +1,359 @@
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from .bbox import *
|
||||||
|
from .utils import *
|
||||||
|
|
||||||
|
|
||||||
|
class Evaluator:
|
||||||
|
def GetPascalVOCMetrics(
|
||||||
|
self,
|
||||||
|
boundingboxes,
|
||||||
|
IOUThreshold=0.5,
|
||||||
|
method=MethodAveragePrecision.EveryPointInterpolation):
|
||||||
|
"""Get the metrics used by the VOC Pascal 2012 challenge.
|
||||||
|
Get
|
||||||
|
Args:
|
||||||
|
boundingboxes: Object of the class BoundingBoxes representing ground truth and detected
|
||||||
|
bounding boxes;
|
||||||
|
IOUThreshold: IOU threshold indicating which detections will be considered TP or FP
|
||||||
|
(default value = 0.5);
|
||||||
|
method (default = EveryPointInterpolation): It can be calculated as the implementation
|
||||||
|
in the official PASCAL VOC toolkit (EveryPointInterpolation), or applying the 11-point
|
||||||
|
interpolatio as described in the paper "The PASCAL Visual Object Classes(VOC) Challenge"
|
||||||
|
or EveryPointInterpolation" (ElevenPointInterpolation);
|
||||||
|
Returns:
|
||||||
|
A list of dictionaries. Each dictionary contains information and metrics of each class.
|
||||||
|
The keys of each dictionary are:
|
||||||
|
dict['class']: class representing the current dictionary;
|
||||||
|
dict['precision']: array with the precision values;
|
||||||
|
dict['recall']: array with the recall values;
|
||||||
|
dict['AP']: average precision;
|
||||||
|
dict['interpolated precision']: interpolated precision values;
|
||||||
|
dict['interpolated recall']: interpolated recall values;
|
||||||
|
dict['total positives']: total number of ground truth positives;
|
||||||
|
dict['total TP']: total number of True Positive detections;
|
||||||
|
dict['total FP']: total number of False Positive detections;
|
||||||
|
"""
|
||||||
|
ret = [
|
||||||
|
] # list containing metrics (precision, recall, average precision) of each class
|
||||||
|
# List with all ground truths (Ex: [imageName,class,confidence=1, (bb
|
||||||
|
# coordinates XYX2Y2)])
|
||||||
|
groundTruths = []
|
||||||
|
# List with all detections (Ex: [imageName,class,confidence,(bb
|
||||||
|
# coordinates XYX2Y2)])
|
||||||
|
detections = []
|
||||||
|
# Get all classes
|
||||||
|
classes = []
|
||||||
|
# Loop through all bounding boxes and separate them into GTs and
|
||||||
|
# detections
|
||||||
|
for bb in boundingboxes.getBoundingBoxes():
|
||||||
|
# [imageName, class, confidence, (bb coordinates XYX2Y2)]
|
||||||
|
if bb.getBBType() == BBType.GroundTruth:
|
||||||
|
groundTruths.append([
|
||||||
|
bb.getImageName(),
|
||||||
|
bb.getClassId(), 1,
|
||||||
|
bb.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
|
||||||
|
])
|
||||||
|
else:
|
||||||
|
detections.append([
|
||||||
|
bb.getImageName(),
|
||||||
|
bb.getClassId(),
|
||||||
|
bb.getConfidence(),
|
||||||
|
bb.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
|
||||||
|
])
|
||||||
|
# get class
|
||||||
|
if bb.getClassId() not in classes:
|
||||||
|
classes.append(bb.getClassId())
|
||||||
|
classes = sorted(classes)
|
||||||
|
# Precision x Recall is obtained individually by each class
|
||||||
|
# Loop through by classes
|
||||||
|
for c in classes:
|
||||||
|
# Get only detection of class c
|
||||||
|
dects = []
|
||||||
|
[dects.append(d) for d in detections if d[1] == c]
|
||||||
|
# Get only ground truths of class c, use filename as key
|
||||||
|
gts = {}
|
||||||
|
npos = 0
|
||||||
|
for g in groundTruths:
|
||||||
|
if g[1] == c:
|
||||||
|
npos += 1
|
||||||
|
gts[g[0]] = gts.get(g[0], []) + [g]
|
||||||
|
|
||||||
|
# sort detections by decreasing confidence
|
||||||
|
dects = sorted(dects, key=lambda conf: conf[2], reverse=True)
|
||||||
|
TP = np.zeros(len(dects))
|
||||||
|
FP = np.zeros(len(dects))
|
||||||
|
# create dictionary with amount of gts for each image
|
||||||
|
det = {key: np.zeros(len(gts[key])) for key in gts}
|
||||||
|
|
||||||
|
# Loop through detections
|
||||||
|
for d in range(len(dects)):
|
||||||
|
# Find ground truth image
|
||||||
|
gt = gts[dects[d][0]] if dects[d][0] in gts else []
|
||||||
|
iouMax = sys.float_info.min
|
||||||
|
for j in range(len(gt)):
|
||||||
|
iou = Evaluator.iou(dects[d][3], gt[j][3])
|
||||||
|
if iou > iouMax:
|
||||||
|
iouMax = iou
|
||||||
|
jmax = j
|
||||||
|
# Assign detection as true positive/don't care/false positive
|
||||||
|
if iouMax >= IOUThreshold:
|
||||||
|
if det[dects[d][0]][jmax] == 0:
|
||||||
|
TP[d] = 1 # count as true positive
|
||||||
|
det[dects[d][0]][jmax] = 1 # flag as already 'seen'
|
||||||
|
else:
|
||||||
|
FP[d] = 1 # count as false positive
|
||||||
|
# - A detected "cat" is overlaped with a GT "cat" with IOU >= IOUThreshold.
|
||||||
|
else:
|
||||||
|
FP[d] = 1 # count as false positive
|
||||||
|
# compute precision, recall and average precision
|
||||||
|
acc_FP = np.cumsum(FP)
|
||||||
|
acc_TP = np.cumsum(TP)
|
||||||
|
rec = acc_TP / npos
|
||||||
|
prec = np.divide(acc_TP, (acc_FP + acc_TP))
|
||||||
|
# Depending on the method, call the right implementation
|
||||||
|
if method == MethodAveragePrecision.EveryPointInterpolation:
|
||||||
|
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(
|
||||||
|
rec, prec)
|
||||||
|
else:
|
||||||
|
[ap, mpre, mrec, _] = Evaluator.ElevenPointInterpolatedAP(
|
||||||
|
rec, prec)
|
||||||
|
# add class result in the dictionary to be returned
|
||||||
|
r = {
|
||||||
|
'class': c,
|
||||||
|
'precision': prec,
|
||||||
|
'recall': rec,
|
||||||
|
'AP': ap,
|
||||||
|
'interpolated precision': mpre,
|
||||||
|
'interpolated recall': mrec,
|
||||||
|
'total positives': npos,
|
||||||
|
'total TP': np.sum(TP),
|
||||||
|
'total FP': np.sum(FP)
|
||||||
|
}
|
||||||
|
ret.append(r)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def PlotPrecisionRecallCurve(
|
||||||
|
self,
|
||||||
|
boundingBoxes,
|
||||||
|
IOUThreshold=0.5,
|
||||||
|
method=MethodAveragePrecision.EveryPointInterpolation,
|
||||||
|
showAP=False,
|
||||||
|
showInterpolatedPrecision=False,
|
||||||
|
savePath=None,
|
||||||
|
showGraphic=True):
|
||||||
|
"""PlotPrecisionRecallCurve
|
||||||
|
Plot the Precision x Recall curve for a given class.
|
||||||
|
Args:
|
||||||
|
boundingBoxes: Object of the class BoundingBoxes representing ground truth and detected
|
||||||
|
bounding boxes;
|
||||||
|
IOUThreshold (optional): IOU threshold indicating which detections will be considered
|
||||||
|
TP or FP (default value = 0.5);
|
||||||
|
method (default = EveryPointInterpolation): It can be calculated as the implementation
|
||||||
|
in the official PASCAL VOC toolkit (EveryPointInterpolation), or applying the 11-point
|
||||||
|
interpolatio as described in the paper "The PASCAL Visual Object Classes(VOC) Challenge"
|
||||||
|
or EveryPointInterpolation" (ElevenPointInterpolation).
|
||||||
|
showAP (optional): if True, the average precision value will be shown in the title of
|
||||||
|
the graph (default = False);
|
||||||
|
showInterpolatedPrecision (optional): if True, it will show in the plot the interpolated
|
||||||
|
precision (default = False);
|
||||||
|
savePath (optional): if informed, the plot will be saved as an image in this path
|
||||||
|
(ex: /home/mywork/ap.png) (default = None);
|
||||||
|
showGraphic (optional): if True, the plot will be shown (default = True)
|
||||||
|
Returns:
|
||||||
|
A list of dictionaries. Each dictionary contains information and metrics of each class.
|
||||||
|
The keys of each dictionary are:
|
||||||
|
dict['class']: class representing the current dictionary;
|
||||||
|
dict['precision']: array with the precision values;
|
||||||
|
dict['recall']: array with the recall values;
|
||||||
|
dict['AP']: average precision;
|
||||||
|
dict['interpolated precision']: interpolated precision values;
|
||||||
|
dict['interpolated recall']: interpolated recall values;
|
||||||
|
dict['total positives']: total number of ground truth positives;
|
||||||
|
dict['total TP']: total number of True Positive detections;
|
||||||
|
dict['total FP']: total number of False Negative detections;
|
||||||
|
"""
|
||||||
|
results = self.GetPascalVOCMetrics(boundingBoxes, IOUThreshold, method)
|
||||||
|
result = None
|
||||||
|
# Each resut represents a class
|
||||||
|
for result in results:
|
||||||
|
if result is None:
|
||||||
|
raise IOError('Error: Class %d could not be found.' % classId)
|
||||||
|
|
||||||
|
classId = result['class']
|
||||||
|
precision = result['precision']
|
||||||
|
recall = result['recall']
|
||||||
|
average_precision = result['AP']
|
||||||
|
mpre = result['interpolated precision']
|
||||||
|
mrec = result['interpolated recall']
|
||||||
|
npos = result['total positives']
|
||||||
|
total_tp = result['total TP']
|
||||||
|
total_fp = result['total FP']
|
||||||
|
|
||||||
|
plt.close()
|
||||||
|
if showInterpolatedPrecision:
|
||||||
|
if method == MethodAveragePrecision.EveryPointInterpolation:
|
||||||
|
plt.plot(
|
||||||
|
mrec,
|
||||||
|
mpre,
|
||||||
|
'--r',
|
||||||
|
label='Interpolated precision (every point)')
|
||||||
|
elif method == MethodAveragePrecision.ElevenPointInterpolation:
|
||||||
|
nrec = []
|
||||||
|
nprec = []
|
||||||
|
for idx in range(len(mrec)):
|
||||||
|
r = mrec[idx]
|
||||||
|
if r not in nrec:
|
||||||
|
idxEq = np.argwhere(mrec == r)
|
||||||
|
nrec.append(r)
|
||||||
|
nprec.append(max([mpre[int(id)] for id in idxEq]))
|
||||||
|
plt.plot(
|
||||||
|
nrec,
|
||||||
|
nprec,
|
||||||
|
'or',
|
||||||
|
label='11-point interpolated precision')
|
||||||
|
plt.plot(recall, precision, label='Precision')
|
||||||
|
plt.xlabel('recall')
|
||||||
|
plt.ylabel('precision')
|
||||||
|
if showAP:
|
||||||
|
ap_str = "{0:.2f}%".format(average_precision * 100)
|
||||||
|
# ap_str = "{0:.4f}%".format(average_precision * 100)
|
||||||
|
plt.title(
|
||||||
|
'Precision x Recall curve \nClass: %s, AP: %s' %
|
||||||
|
(str(classId), ap_str))
|
||||||
|
else:
|
||||||
|
plt.title('Precision x Recall curve \nClass: %s' % str(classId))
|
||||||
|
plt.legend(shadow=True)
|
||||||
|
plt.grid()
|
||||||
|
if savePath is not None:
|
||||||
|
plt.savefig(os.path.join(savePath, str(classId) + '.png'))
|
||||||
|
if showGraphic is True:
|
||||||
|
plt.show()
|
||||||
|
# plt.waitforbuttonpress()
|
||||||
|
plt.pause(0.05)
|
||||||
|
return results
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def CalculateAveragePrecision(rec, prec):
|
||||||
|
mrec = []
|
||||||
|
mrec.append(0)
|
||||||
|
[mrec.append(e) for e in rec]
|
||||||
|
mrec.append(1)
|
||||||
|
mpre = []
|
||||||
|
mpre.append(0)
|
||||||
|
[mpre.append(e) for e in prec]
|
||||||
|
mpre.append(0)
|
||||||
|
for i in range(len(mpre) - 1, 0, -1):
|
||||||
|
mpre[i - 1] = max(mpre[i - 1], mpre[i])
|
||||||
|
ii = []
|
||||||
|
for i in range(len(mrec) - 1):
|
||||||
|
if mrec[1 + i] != mrec[i]:
|
||||||
|
ii.append(i + 1)
|
||||||
|
ap = 0
|
||||||
|
for i in ii:
|
||||||
|
ap = ap + np.sum((mrec[i] - mrec[i - 1]) * mpre[i])
|
||||||
|
return [ap, mpre[0:len(mpre) - 1], mrec[0:len(mpre) - 1], ii]
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
# 11-point interpolated average precision
|
||||||
|
def ElevenPointInterpolatedAP(rec, prec):
|
||||||
|
# def CalculateAveragePrecision2(rec, prec):
|
||||||
|
mrec = []
|
||||||
|
[mrec.append(e) for e in rec]
|
||||||
|
mpre = []
|
||||||
|
[mpre.append(e) for e in prec]
|
||||||
|
recallValues = np.linspace(0, 1, 11)
|
||||||
|
recallValues = list(recallValues[::-1])
|
||||||
|
rhoInterp = []
|
||||||
|
recallValid = []
|
||||||
|
# For each recallValues (0, 0.1, 0.2, ... , 1)
|
||||||
|
for r in recallValues:
|
||||||
|
# Obtain all recall values higher or equal than r
|
||||||
|
argGreaterRecalls = np.argwhere(mrec[:] >= r)
|
||||||
|
pmax = 0
|
||||||
|
# If there are recalls above r
|
||||||
|
if argGreaterRecalls.size != 0:
|
||||||
|
pmax = max(mpre[argGreaterRecalls.min():])
|
||||||
|
recallValid.append(r)
|
||||||
|
rhoInterp.append(pmax)
|
||||||
|
# By definition AP = sum(max(precision whose recall is above r))/11
|
||||||
|
ap = sum(rhoInterp) / 11
|
||||||
|
# Generating values for the plot
|
||||||
|
rvals = []
|
||||||
|
rvals.append(recallValid[0])
|
||||||
|
[rvals.append(e) for e in recallValid]
|
||||||
|
rvals.append(0)
|
||||||
|
pvals = []
|
||||||
|
pvals.append(0)
|
||||||
|
[pvals.append(e) for e in rhoInterp]
|
||||||
|
pvals.append(0)
|
||||||
|
cc = []
|
||||||
|
for i in range(len(rvals)):
|
||||||
|
p = (rvals[i], pvals[i - 1])
|
||||||
|
if p not in cc:
|
||||||
|
cc.append(p)
|
||||||
|
p = (rvals[i], pvals[i])
|
||||||
|
if p not in cc:
|
||||||
|
cc.append(p)
|
||||||
|
recallValues = [i[0] for i in cc]
|
||||||
|
rhoInterp = [i[1] for i in cc]
|
||||||
|
return [ap, rhoInterp, recallValues, None]
|
||||||
|
|
||||||
|
# For each detections, calculate IOU with reference
|
||||||
|
@staticmethod
|
||||||
|
def _getAllIOUs(reference, detections):
|
||||||
|
ret = []
|
||||||
|
bbReference = reference.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
|
||||||
|
for d in detections:
|
||||||
|
bb = d.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
|
||||||
|
iou = Evaluator.iou(bbReference, bb)
|
||||||
|
ret.append((iou, reference, d)) # iou, reference, detection
|
||||||
|
return sorted(ret, key=lambda i: i[0], reverse=True)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def iou(boxA, boxB):
|
||||||
|
if Evaluator._boxesIntersect(boxA, boxB) is False:
|
||||||
|
return 0
|
||||||
|
interArea = Evaluator._getIntersectionArea(boxA, boxB)
|
||||||
|
union = Evaluator._getUnionAreas(boxA, boxB, interArea=interArea)
|
||||||
|
iou = interArea / union
|
||||||
|
assert iou >= 0
|
||||||
|
return iou
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _boxesIntersect(boxA, boxB):
|
||||||
|
if boxA[0] > boxB[2]:
|
||||||
|
return False # boxA is right of boxB
|
||||||
|
if boxB[0] > boxA[2]:
|
||||||
|
return False # boxA is left of boxB
|
||||||
|
if boxA[3] < boxB[1]:
|
||||||
|
return False # boxA is above boxB
|
||||||
|
if boxA[1] > boxB[3]:
|
||||||
|
return False # boxA is below boxB
|
||||||
|
return True
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _getIntersectionArea(boxA, boxB):
|
||||||
|
xA = max(boxA[0], boxB[0])
|
||||||
|
yA = max(boxA[1], boxB[1])
|
||||||
|
xB = min(boxA[2], boxB[2])
|
||||||
|
yB = min(boxA[3], boxB[3])
|
||||||
|
# intersection area
|
||||||
|
return (xB - xA + 1) * (yB - yA + 1)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _getUnionAreas(boxA, boxB, interArea=None):
|
||||||
|
area_A = Evaluator._getArea(boxA)
|
||||||
|
area_B = Evaluator._getArea(boxB)
|
||||||
|
if interArea is None:
|
||||||
|
interArea = Evaluator._getIntersectionArea(boxA, boxB)
|
||||||
|
return float(area_A + area_B - interArea)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _getArea(box):
|
||||||
|
return (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
|
||||||
126
detection/eval/detection/utils.py
Normal file
126
detection/eval/detection/utils.py
Normal file
|
|
@ -0,0 +1,126 @@
|
||||||
|
from enum import Enum
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
class MethodAveragePrecision(Enum):
|
||||||
|
"""
|
||||||
|
Class representing if the coordinates are relative to the
|
||||||
|
image size or are absolute values.
|
||||||
|
|
||||||
|
Developed by: Rafael Padilla
|
||||||
|
Last modification: Apr 28 2018
|
||||||
|
"""
|
||||||
|
EveryPointInterpolation = 1
|
||||||
|
ElevenPointInterpolation = 2
|
||||||
|
|
||||||
|
|
||||||
|
class CoordinatesType(Enum):
|
||||||
|
"""
|
||||||
|
Class representing if the coordinates are relative to the
|
||||||
|
image size or are absolute values.
|
||||||
|
|
||||||
|
Developed by: Rafael Padilla
|
||||||
|
Last modification: Apr 28 2018
|
||||||
|
"""
|
||||||
|
Relative = 1
|
||||||
|
Absolute = 2
|
||||||
|
|
||||||
|
|
||||||
|
class BBType(Enum):
|
||||||
|
"""
|
||||||
|
Class representing if the bounding box is groundtruth or not.
|
||||||
|
|
||||||
|
Developed by: Rafael Padilla
|
||||||
|
Last modification: May 24 2018
|
||||||
|
"""
|
||||||
|
GroundTruth = 1
|
||||||
|
Detected = 2
|
||||||
|
|
||||||
|
|
||||||
|
class BBFormat(Enum):
|
||||||
|
"""
|
||||||
|
Class representing the format of a bounding box.
|
||||||
|
It can be (X,Y,width,height) => XYWH
|
||||||
|
or (X1,Y1,X2,Y2) => XYX2Y2
|
||||||
|
|
||||||
|
Developed by: Rafael Padilla
|
||||||
|
Last modification: May 24 2018
|
||||||
|
"""
|
||||||
|
XYWH = 1
|
||||||
|
XYX2Y2 = 2
|
||||||
|
|
||||||
|
|
||||||
|
def convertToRelativeValues(size, box):
|
||||||
|
"""Convert absolute box coordinates to relative ones.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
size (tuple of int): (width, height) of the image
|
||||||
|
box (tuple of int): (X1, X2, Y1, Y2) of the bounding box
|
||||||
|
"""
|
||||||
|
dw = 1. / (size[0])
|
||||||
|
dh = 1. / (size[1])
|
||||||
|
cx = (box[1] + box[0]) / 2.0
|
||||||
|
cy = (box[3] + box[2]) / 2.0
|
||||||
|
w = box[1] - box[0]
|
||||||
|
h = box[3] - box[2]
|
||||||
|
x = cx * dw
|
||||||
|
y = cy * dh
|
||||||
|
w = w * dw
|
||||||
|
h = h * dh
|
||||||
|
return (x, y, w, h)
|
||||||
|
|
||||||
|
|
||||||
|
def convertToAbsoluteValues(size, box):
|
||||||
|
"""Convert relative box coordinates to absolute ones.
|
||||||
|
Args:
|
||||||
|
size (tuple of int): (width, height) of the image
|
||||||
|
box (tuple of int): (centerX, centerY, w, h) of the bounding box relative to the image
|
||||||
|
"""
|
||||||
|
xIn = round(((2 * float(box[0]) - float(box[2])) * size[0] / 2))
|
||||||
|
yIn = round(((2 * float(box[1]) - float(box[3])) * size[1] / 2))
|
||||||
|
xEnd = xIn + round(float(box[2]) * size[0])
|
||||||
|
yEnd = yIn + round(float(box[3]) * size[1])
|
||||||
|
if xIn < 0:
|
||||||
|
xIn = 0
|
||||||
|
if yIn < 0:
|
||||||
|
yIn = 0
|
||||||
|
if xEnd >= size[0]:
|
||||||
|
xEnd = size[0] - 1
|
||||||
|
if yEnd >= size[1]:
|
||||||
|
yEnd = size[1] - 1
|
||||||
|
return (xIn, yIn, xEnd, yEnd)
|
||||||
|
|
||||||
|
|
||||||
|
def add_bb_into_image(image, bb, color=(255, 0, 0), thickness=2, label=None):
|
||||||
|
r = int(color[0])
|
||||||
|
g = int(color[1])
|
||||||
|
b = int(color[2])
|
||||||
|
|
||||||
|
font = cv2.FONT_HERSHEY_SIMPLEX
|
||||||
|
fontScale = 0.5
|
||||||
|
fontThickness = 1
|
||||||
|
|
||||||
|
x1, y1, x2, y2 = bb.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
|
||||||
|
x1 = int(x1)
|
||||||
|
y1 = int(y1)
|
||||||
|
x2 = int(x2)
|
||||||
|
y2 = int(y2)
|
||||||
|
cv2.rectangle(image, (x1, y1), (x2, y2), (b, g, r), thickness)
|
||||||
|
# Add label
|
||||||
|
if label is not None:
|
||||||
|
# Get size of the text box
|
||||||
|
(tw, th) = cv2.getTextSize(label, font, fontScale, fontThickness)[0]
|
||||||
|
# Top-left coord of the textbox
|
||||||
|
(xin_bb, yin_bb) = (x1 + thickness, y1 - th + int(12.5 * fontScale))
|
||||||
|
# Checking position of the text top-left (outside or inside the bb)
|
||||||
|
if yin_bb - th <= 0: # if outside the image
|
||||||
|
yin_bb = y1 + th # put it inside the bb
|
||||||
|
r_Xin = x1 - int(thickness / 2)
|
||||||
|
r_Yin = y1 - th - int(thickness / 2)
|
||||||
|
# Draw filled rectangle to put the text in it
|
||||||
|
cv2.rectangle(image, (r_Xin, r_Yin - thickness), (r_Xin + tw + \
|
||||||
|
thickness * 3, r_Yin + th + int(12.5 * fontScale)), (b, g, r), -1)
|
||||||
|
cv2.putText(image, label, (xin_bb, yin_bb), font, fontScale,
|
||||||
|
(0, 0, 0), fontThickness, cv2.LINE_AA)
|
||||||
|
return image
|
||||||
158
detection/eval/evaluator.py
Normal file
158
detection/eval/evaluator.py
Normal file
|
|
@ -0,0 +1,158 @@
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from . import detection
|
||||||
|
|
||||||
|
|
||||||
|
class DatasetEvaluator:
|
||||||
|
"""
|
||||||
|
Base class for a dataset evaluator.
|
||||||
|
|
||||||
|
This class will accumulate information of the inputs/outputs (by :meth:`process`),
|
||||||
|
and produce evaluation results in the end (by :meth:`evaluate`).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
"""
|
||||||
|
Preparation for a new round of evaluation.
|
||||||
|
Should be called before starting a round of evaluation.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError ("[reset] method need to be implemented in child class.")
|
||||||
|
|
||||||
|
def process(self, inputs, outputs):
|
||||||
|
"""
|
||||||
|
Process the pair of inputs and outputs.
|
||||||
|
If they contain batches, the pairs can be consumed one-by-one using `zip`:
|
||||||
|
|
||||||
|
Args:
|
||||||
|
inputs (list): the inputs that's used to call the model.
|
||||||
|
outputs (list): the return value of `model(inputs)`
|
||||||
|
"""
|
||||||
|
raise NotImplementedError ("[process] method need to be implemented in child class.")
|
||||||
|
|
||||||
|
def evaluate(self):
|
||||||
|
"""
|
||||||
|
Evaluate/summarize the performance, after processing all input/output pairs.
|
||||||
|
|
||||||
|
"""
|
||||||
|
raise NotImplementedError ("[evaluate] method need to be implemented in child class.")
|
||||||
|
|
||||||
|
|
||||||
|
class DetectionEvaluator(DatasetEvaluator):
|
||||||
|
"""
|
||||||
|
Evaluator for detection task.
|
||||||
|
This class will accumulate information of the inputs/outputs (by :meth:`process`),
|
||||||
|
and produce evaluation results in the end (by :meth:`evaluate`).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, iou_thresh=0.5):
|
||||||
|
self._evaluator = detection.Evaluator()
|
||||||
|
self._iou_thresh = iou_thresh
|
||||||
|
self.reset()
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
self._bbox = detection.BoundingBoxes()
|
||||||
|
|
||||||
|
def process(self, groudtruths, predictions):
|
||||||
|
"""
|
||||||
|
Inputs format:
|
||||||
|
https://detectron2.readthedocs.io/en/latest/tutorials/models.html?highlight=input%20format#model-input-format
|
||||||
|
Outputs format:
|
||||||
|
https://detectron2.readthedocs.io/en/latest/tutorials/models.html?highlight=input%20format#model-output-format
|
||||||
|
"""
|
||||||
|
for sample_input, sample_output in zip(groudtruths, predictions):
|
||||||
|
image_id = sample_input['image_id']
|
||||||
|
gt_instances = sample_input['instances']
|
||||||
|
pred_instances = sample_output['instances']
|
||||||
|
width = sample_input['width']
|
||||||
|
height = sample_input['height']
|
||||||
|
for i in range(len(gt_instances)):
|
||||||
|
instance = gt_instances[i]
|
||||||
|
class_id = instance.get(
|
||||||
|
'gt_classes').cpu().detach().numpy().item()
|
||||||
|
boxes = instance.get('gt_boxes')
|
||||||
|
for box in boxes:
|
||||||
|
box_np = box.cpu().detach().numpy()
|
||||||
|
bb = detection.BoundingBox(
|
||||||
|
image_id,
|
||||||
|
class_id,
|
||||||
|
box_np[0],
|
||||||
|
box_np[1],
|
||||||
|
box_np[2],
|
||||||
|
box_np[3],
|
||||||
|
detection.CoordinatesType.Absolute,
|
||||||
|
(width,
|
||||||
|
height),
|
||||||
|
detection.BBType.GroundTruth,
|
||||||
|
format=detection.BBFormat.XYX2Y2)
|
||||||
|
self._bbox.addBoundingBox(bb)
|
||||||
|
for i in range(len(pred_instances)):
|
||||||
|
instance = pred_instances[i]
|
||||||
|
class_id = instance.get(
|
||||||
|
'pred_classes').cpu().detach().numpy().item()
|
||||||
|
scores = instance.get('scores').cpu().detach().numpy().item()
|
||||||
|
boxes = instance.get('pred_boxes')
|
||||||
|
for box in boxes:
|
||||||
|
box_np = box.cpu().detach().numpy()
|
||||||
|
bb = detection.BoundingBox(
|
||||||
|
image_id,
|
||||||
|
class_id,
|
||||||
|
box_np[0],
|
||||||
|
box_np[1],
|
||||||
|
box_np[2],
|
||||||
|
box_np[3],
|
||||||
|
detection.CoordinatesType.Absolute,
|
||||||
|
(width,
|
||||||
|
height),
|
||||||
|
detection.BBType.Detected,
|
||||||
|
scores,
|
||||||
|
format=detection.BBFormat.XYX2Y2)
|
||||||
|
self._bbox.addBoundingBox(bb)
|
||||||
|
|
||||||
|
def evaluate(self):
|
||||||
|
results = self._evaluator.GetPascalVOCMetrics(self._bbox, self._iou_thresh)
|
||||||
|
if isinstance(results, dict):
|
||||||
|
results = [results]
|
||||||
|
metrics = {}
|
||||||
|
APs = []
|
||||||
|
for result in results:
|
||||||
|
metrics[f'AP_{result["class"]}'] = result['AP']
|
||||||
|
APs.append(result['AP'])
|
||||||
|
metrics['mAP'] = np.nanmean(APs)
|
||||||
|
self._evaluator.PlotPrecisionRecallCurve(self._bbox, savePath="./plots/", showGraphic=False)
|
||||||
|
return metrics
|
||||||
|
|
||||||
|
class DatasetEvaluators(DatasetEvaluator):
|
||||||
|
"""
|
||||||
|
Wrapper class to combine multiple :class:`DatasetEvaluator` instances.
|
||||||
|
|
||||||
|
This class dispatches every evaluation call to
|
||||||
|
all of its :class:`DatasetEvaluator`.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, evaluators):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
evaluators (list): the evaluators to combine.
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self._evaluators = evaluators
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
for evaluator in self._evaluators:
|
||||||
|
evaluator.reset()
|
||||||
|
|
||||||
|
def process(self, inputs, outputs):
|
||||||
|
for evaluator in self._evaluators:
|
||||||
|
evaluator.process(inputs, outputs)
|
||||||
|
|
||||||
|
def evaluate(self):
|
||||||
|
results = OrderedDict()
|
||||||
|
for evaluator in self._evaluators:
|
||||||
|
result = evaluator.evaluate()
|
||||||
|
if is_main_process() and result is not None:
|
||||||
|
for k, v in result.items():
|
||||||
|
assert (
|
||||||
|
k not in results
|
||||||
|
), "Different evaluators produce results with the same key {}".format(k)
|
||||||
|
results[k] = v
|
||||||
|
return results
|
||||||
16
detection/eval/loss.py
Normal file
16
detection/eval/loss.py
Normal file
|
|
@ -0,0 +1,16 @@
|
||||||
|
import torch
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
|
||||||
|
def get_loss_fn(loss_args):
|
||||||
|
loss_args_ = loss_args
|
||||||
|
if isinstance(loss_args, argparse.Namespace):
|
||||||
|
loss_args_ = vars(loss_args)
|
||||||
|
loss_fn = loss_args_.get("loss_fn")
|
||||||
|
|
||||||
|
if loss_fn == "BCE":
|
||||||
|
return torch.nn.BCEWithLogitsLoss()
|
||||||
|
elif loss_fn == "CE":
|
||||||
|
return torch.nn.CrossEntropyLoss()
|
||||||
|
else:
|
||||||
|
raise ValueError(f"loss_fn {loss_args.loss_fn} not supported.")
|
||||||
13
detection/lightning/__init__.py
Normal file
13
detection/lightning/__init__.py
Normal file
|
|
@ -0,0 +1,13 @@
|
||||||
|
import torch
|
||||||
|
|
||||||
|
from .detection import DetectionTask
|
||||||
|
from .util import get_ckpt_callback, get_early_stop_callback
|
||||||
|
from .util import get_logger
|
||||||
|
|
||||||
|
|
||||||
|
def get_task(args):
|
||||||
|
return DetectionTask(args)
|
||||||
|
|
||||||
|
def load_task(ckpt_path, **kwargs):
|
||||||
|
args = torch.load(ckpt_path, map_location='cpu')['hyper_parameters']
|
||||||
|
return DetectionTask.load_from_checkpoint(ckpt_path, **kwargs)
|
||||||
175
detection/lightning/detection.py
Normal file
175
detection/lightning/detection.py
Normal file
|
|
@ -0,0 +1,175 @@
|
||||||
|
import nni
|
||||||
|
import pickle as pkl
|
||||||
|
import json
|
||||||
|
import pytorch_lightning as pl
|
||||||
|
import os
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torchvision
|
||||||
|
from PIL import Image
|
||||||
|
import pandas as pd
|
||||||
|
from detectron2.data import transforms as T
|
||||||
|
from detectron2.structures import Instances, Boxes
|
||||||
|
from detectron2.utils.visualizer import Visualizer
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
from ignite.metrics import Accuracy
|
||||||
|
|
||||||
|
from models import get_model
|
||||||
|
from eval import DetectionEvaluator
|
||||||
|
from data import get_dataset
|
||||||
|
from util import constants as C
|
||||||
|
from util import get_concat_h_cut
|
||||||
|
from .logger import TFLogger
|
||||||
|
|
||||||
|
|
||||||
|
class DetectionTask(pl.LightningModule, TFLogger):
|
||||||
|
"""Standard interface for the trainer to interact with the model."""
|
||||||
|
|
||||||
|
def __init__(self, params):
|
||||||
|
super().__init__()
|
||||||
|
self.save_hyperparameters(params)
|
||||||
|
self.model = get_model(params)
|
||||||
|
self.evaluator = DetectionEvaluator()
|
||||||
|
|
||||||
|
def training_step(self, batch, batch_nb):
|
||||||
|
losses = self.model.forward(batch)
|
||||||
|
loss = torch.stack(list(losses.values())).mean()
|
||||||
|
return loss
|
||||||
|
|
||||||
|
def validation_step(self, batch, batch_nb):
|
||||||
|
losses = self.model.forward(batch)
|
||||||
|
loss = torch.stack(list(losses.values())).mean()
|
||||||
|
preds = self.model.infer(batch)
|
||||||
|
self.evaluator.process(batch, preds)
|
||||||
|
return loss
|
||||||
|
|
||||||
|
def validation_epoch_end(self, outputs):
|
||||||
|
avg_loss = torch.stack(outputs).mean()
|
||||||
|
self.log("val_loss", avg_loss)
|
||||||
|
metrics = self.evaluator.evaluate()
|
||||||
|
nni.report_intermediate_result(metrics['mAP'])
|
||||||
|
self.evaluator.reset()
|
||||||
|
self.log_dict(metrics, prog_bar=True)
|
||||||
|
|
||||||
|
def test_step(self, batch, batch_nb):
|
||||||
|
preds = self.model.infer(batch)
|
||||||
|
conf_threshold = self.hparams.get("conf_threshold", 0)
|
||||||
|
iou_threshold = self.hparams.get("iou_threshold", 0.5)
|
||||||
|
padding = self.hparams.get("padding", 10)
|
||||||
|
if self.hparams.get('visualize', False) or self.hparams.get("deploy", False):
|
||||||
|
for i, (sample, pred) in enumerate(zip(batch, preds)):
|
||||||
|
instances = pred['instances']
|
||||||
|
boxes = instances.get('pred_boxes').tensor
|
||||||
|
class_id = instances.get('pred_classes')
|
||||||
|
|
||||||
|
# Filter by scores
|
||||||
|
scores = instances.scores
|
||||||
|
keep_id_conf = scores > conf_threshold
|
||||||
|
boxes_conf = boxes[keep_id_conf]
|
||||||
|
scores_conf = scores[keep_id_conf]
|
||||||
|
class_id_conf = class_id[keep_id_conf]
|
||||||
|
if boxes_conf.size(0) == 0:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Filter by nms
|
||||||
|
keep_id_nms = torchvision.ops.nms(boxes_conf,
|
||||||
|
scores_conf,
|
||||||
|
iou_threshold)
|
||||||
|
|
||||||
|
boxes_nms = boxes_conf[keep_id_nms]
|
||||||
|
scores_nms = scores_conf[keep_id_nms]
|
||||||
|
class_id_nms = class_id_conf[keep_id_nms]
|
||||||
|
|
||||||
|
# Pad box size
|
||||||
|
boxes_nms[:, 0] -= padding
|
||||||
|
boxes_nms[:, 1] -= padding
|
||||||
|
boxes_nms[:, 2] += padding
|
||||||
|
boxes_nms[:, 3] += padding
|
||||||
|
boxes_nms = torch.clip(boxes_nms, 0, 640)
|
||||||
|
|
||||||
|
for j in range(len(scores_nms)):
|
||||||
|
instances = Instances((640, 640))
|
||||||
|
class_id_numpy = class_id_nms.to("cpu").numpy()[j]
|
||||||
|
box_numpy = boxes_nms.to("cpu").numpy()[j]
|
||||||
|
score_numpy = scores_nms.to("cpu").numpy()[j]
|
||||||
|
|
||||||
|
instances.pred_classes = np.array([class_id_numpy])
|
||||||
|
instances.pred_boxes = Boxes(box_numpy[np.newaxis,:])
|
||||||
|
instances.scores = np.array([score_numpy])
|
||||||
|
|
||||||
|
v = Visualizer(np.transpose(sample['image'].to("cpu"), (1,2,0)),
|
||||||
|
instance_mode=1,
|
||||||
|
metadata=C.META)
|
||||||
|
out = v.draw_instance_predictions(instances)
|
||||||
|
img_box = Image.fromarray(out.get_image())
|
||||||
|
|
||||||
|
if self.hparams.get("deploy", False):
|
||||||
|
panoid = sample['panoid']
|
||||||
|
heading = sample['heading']
|
||||||
|
save_path = f".output/{panoid[:2]}/{panoid}_{heading}_{j}.jpg"
|
||||||
|
json_save_path = f".output/{panoid[:2]}/{panoid}_{heading}_{j}.json"
|
||||||
|
|
||||||
|
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||||
|
|
||||||
|
img_org = Image.open(sample['save_path'])
|
||||||
|
img_out = get_concat_h_cut(img_org, img_box)
|
||||||
|
img_out.save(save_path)
|
||||||
|
data = {"panoid": panoid,
|
||||||
|
"heaidng": int(heading),
|
||||||
|
"detection_id": int(j),
|
||||||
|
"class_id": int(class_id_numpy),
|
||||||
|
"box": [int(x) for x in box_numpy],
|
||||||
|
"score": float(score_numpy),
|
||||||
|
"save_path": save_path}
|
||||||
|
with open(json_save_path, 'w') as fp:
|
||||||
|
json.dump(data, fp)
|
||||||
|
else:
|
||||||
|
img_box.save(f"outputs/{batch_nb}_{i}.jpg")
|
||||||
|
|
||||||
|
self.evaluator.process(batch, preds)
|
||||||
|
|
||||||
|
def test_epoch_end(self, outputs):
|
||||||
|
metrics = self.evaluator.evaluate()
|
||||||
|
nni.report_final_result(metrics['mAP'])
|
||||||
|
self.log_dict(metrics)
|
||||||
|
|
||||||
|
def configure_optimizers(self):
|
||||||
|
return [torch.optim.Adam(self.parameters(), lr=self.hparams['learning_rate'])]
|
||||||
|
|
||||||
|
def train_dataloader(self):
|
||||||
|
dataset = get_dataset('train')
|
||||||
|
return dataset.detection_dataloader(
|
||||||
|
shuffle=True,
|
||||||
|
augmentations=[
|
||||||
|
T.RandomBrightness(0.9, 1.1),
|
||||||
|
T.RandomFlip(prob=0.5),
|
||||||
|
],
|
||||||
|
batch_size=self.hparams['batch_size'],
|
||||||
|
num_workers=8)
|
||||||
|
|
||||||
|
def val_dataloader(self):
|
||||||
|
dataset = get_dataset('valid')
|
||||||
|
return dataset.detection_dataloader(
|
||||||
|
shuffle=False,
|
||||||
|
batch_size=1,
|
||||||
|
num_workers=8)
|
||||||
|
|
||||||
|
def test_dataloader(self):
|
||||||
|
if self.hparams.get('deploy', False):
|
||||||
|
dataset = load_dataset(self.hparams['dataset_name'])
|
||||||
|
df = pd.read_csv(self.hparams['deploy_meta_path']).query("downloaded == True")
|
||||||
|
df["image_id"] = df['save_path']
|
||||||
|
df["gsv_image_path"] = df['save_path']
|
||||||
|
df['annotations'] = "[]"
|
||||||
|
dataset._meta = df
|
||||||
|
return dataset.detection_dataloader(
|
||||||
|
shuffle=False,
|
||||||
|
batch_size=self.hparams.get("test_batch_size", 1),
|
||||||
|
num_workers=8)
|
||||||
|
else:
|
||||||
|
test_split = self.hparams.get("test_split", "valid")
|
||||||
|
dataset = get_dataset(test_split)
|
||||||
|
return dataset.detection_dataloader(
|
||||||
|
shuffle=False,
|
||||||
|
batch_size=1,
|
||||||
|
num_workers=8)
|
||||||
61
detection/lightning/logger.py
Normal file
61
detection/lightning/logger.py
Normal file
|
|
@ -0,0 +1,61 @@
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from util.constants import IMAGENET_MEAN, IMAGENET_STD
|
||||||
|
|
||||||
|
|
||||||
|
class TFLogger:
|
||||||
|
def log_images(self, images, tag, size=125):
|
||||||
|
"""
|
||||||
|
Log images and optionally detection to tensorboard
|
||||||
|
:param logger: [Tensorboard Logger] Tensorboard logger object.
|
||||||
|
:param images: [tensor] batch of images indexed
|
||||||
|
[batch, channel, size1, size2]
|
||||||
|
TODO: Include an argument for image labels;
|
||||||
|
Print the labels on the images.
|
||||||
|
"""
|
||||||
|
images = prep_images_for_logging(images,
|
||||||
|
pretrained=self.args['pretrained'],
|
||||||
|
size=size)
|
||||||
|
self.logger.experiment.add_images(tag, images)
|
||||||
|
|
||||||
|
|
||||||
|
def prep_images_for_logging(images, pretrained=False,
|
||||||
|
size=125):
|
||||||
|
"""
|
||||||
|
Prepare images to be logged
|
||||||
|
:param images: [tensor] batch of images indexed
|
||||||
|
[channel, size1, size2]
|
||||||
|
:param mean: [list] mean values used to normalize images
|
||||||
|
:param std: [list] standard deviation values used to normalize images
|
||||||
|
:param size: [int] new size of the image to be rescaled
|
||||||
|
:return: images that are reversely normalized
|
||||||
|
"""
|
||||||
|
if pretrained:
|
||||||
|
mean = IMAGENET_MEAN
|
||||||
|
std = IMAGENET_STD
|
||||||
|
else:
|
||||||
|
mean = [0, 0, 0]
|
||||||
|
std = [1, 1, 1]
|
||||||
|
images = normalize_inverse(images, mean, std)
|
||||||
|
images = F.interpolate(images, size=size,
|
||||||
|
mode='bilinear', align_corners=True)
|
||||||
|
return images
|
||||||
|
|
||||||
|
|
||||||
|
def normalize_inverse(images, mean=IMAGENET_MEAN, std=IMAGENET_STD):
|
||||||
|
"""
|
||||||
|
Reverse Normalization of Pytorch Tensor
|
||||||
|
:param images: [tensor] batch of images indexed
|
||||||
|
[batch, channel, size1, size2]
|
||||||
|
:param mean: [list] mean values used to normalize images
|
||||||
|
:param std: [list] standard deviation values used to normalize images
|
||||||
|
:return: images that are reversely normalized
|
||||||
|
"""
|
||||||
|
mean_inv = torch.FloatTensor(
|
||||||
|
[-m/s for m, s in zip(mean, std)]).view(1, 3, 1, 1)
|
||||||
|
std_inv = torch.FloatTensor([1/s for s in std]).view(1, 3, 1, 1)
|
||||||
|
if torch.cuda.is_available():
|
||||||
|
mean_inv = mean_inv.cuda()
|
||||||
|
std_inv = std_inv.cuda()
|
||||||
|
return (images - mean_inv) / std_inv
|
||||||
34
detection/lightning/util.py
Normal file
34
detection/lightning/util.py
Normal file
|
|
@ -0,0 +1,34 @@
|
||||||
|
"""Define Logger class for logging information to stdout and disk."""
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
from os.path import join
|
||||||
|
from pytorch_lightning.loggers.test_tube import TestTubeLogger
|
||||||
|
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
|
||||||
|
|
||||||
|
|
||||||
|
def get_ckpt_dir(save_path, exp_name):
|
||||||
|
return os.path.join(save_path, exp_name, "ckpts")
|
||||||
|
|
||||||
|
|
||||||
|
def get_ckpt_callback(save_path, exp_name, monitor="val_loss", mode="min"):
|
||||||
|
ckpt_dir = os.path.join(save_path, exp_name, "ckpts")
|
||||||
|
return ModelCheckpoint(filepath=ckpt_dir,
|
||||||
|
save_top_k=1,
|
||||||
|
verbose=True,
|
||||||
|
monitor=monitor,
|
||||||
|
mode=mode,
|
||||||
|
prefix='')
|
||||||
|
|
||||||
|
|
||||||
|
def get_early_stop_callback(patience=10):
|
||||||
|
return EarlyStopping(monitor='val_loss',
|
||||||
|
patience=patience,
|
||||||
|
verbose=True,
|
||||||
|
mode='min')
|
||||||
|
|
||||||
|
|
||||||
|
def get_logger(save_path, exp_name):
|
||||||
|
exp_dir = os.path.join(save_path, exp_name)
|
||||||
|
return TestTubeLogger(save_dir=exp_dir,
|
||||||
|
name='lightning_logs',
|
||||||
|
version="0")
|
||||||
115
detection/main.py
Normal file
115
detection/main.py
Normal file
|
|
@ -0,0 +1,115 @@
|
||||||
|
import os
|
||||||
|
import fire
|
||||||
|
from pytorch_lightning import Trainer
|
||||||
|
|
||||||
|
from util.nni import run_nni
|
||||||
|
from util import init_exp_folder, Args
|
||||||
|
from util import constants as C
|
||||||
|
from lightning import (get_task,
|
||||||
|
load_task,
|
||||||
|
get_ckpt_callback,
|
||||||
|
get_early_stop_callback,
|
||||||
|
get_logger)
|
||||||
|
|
||||||
|
|
||||||
|
def train(save_dir=C.SANDBOX_PATH,
|
||||||
|
tb_path=C.TB_PATH,
|
||||||
|
exp_name="DemoExperiment",
|
||||||
|
model="FasterRCNN",
|
||||||
|
task='detection',
|
||||||
|
gpus=1,
|
||||||
|
pretrained=True,
|
||||||
|
batch_size=8,
|
||||||
|
accelerator="ddp",
|
||||||
|
gradient_clip_val=0.5,
|
||||||
|
max_epochs=100,
|
||||||
|
learning_rate=1e-5,
|
||||||
|
patience=30,
|
||||||
|
limit_train_batches=1.0,
|
||||||
|
limit_val_batches=1.0,
|
||||||
|
limit_test_batches=1.0,
|
||||||
|
weights_summary=None,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Run the training experiment.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
save_dir: Path to save the checkpoints and logs
|
||||||
|
exp_name: Name of the experiment
|
||||||
|
model: Model name
|
||||||
|
gpus: int. (ie: 2 gpus)
|
||||||
|
OR list to specify which GPUs [0, 1] OR '0,1'
|
||||||
|
OR '-1' / -1 to use all available gpus
|
||||||
|
pretrained: Whether or not to use the pretrained model
|
||||||
|
num_classes: Number of classes
|
||||||
|
accelerator: Distributed computing mode
|
||||||
|
gradient_clip_val: Clip value of gradient norm
|
||||||
|
limit_train_batches: Proportion of training data to use
|
||||||
|
max_epochs: Max number of epochs
|
||||||
|
patience: number of epochs with no improvement after
|
||||||
|
which training will be stopped.
|
||||||
|
tb_path: Path to global tb folder
|
||||||
|
loss_fn: Loss function to use
|
||||||
|
weights_summary: Prints a summary of the weights when training begins.
|
||||||
|
|
||||||
|
Returns: None
|
||||||
|
|
||||||
|
"""
|
||||||
|
num_classes = 2
|
||||||
|
dataset_name = "camera-detection-new"
|
||||||
|
|
||||||
|
args = Args(locals())
|
||||||
|
init_exp_folder(args)
|
||||||
|
task = get_task(args)
|
||||||
|
trainer = Trainer(gpus=gpus,
|
||||||
|
accelerator=accelerator,
|
||||||
|
logger=get_logger(save_dir, exp_name),
|
||||||
|
callbacks=[get_early_stop_callback(patience),
|
||||||
|
get_ckpt_callback(save_dir, exp_name, monitor="mAP", mode="max")],
|
||||||
|
weights_save_path=os.path.join(save_dir, exp_name),
|
||||||
|
gradient_clip_val=gradient_clip_val,
|
||||||
|
limit_train_batches=limit_train_batches,
|
||||||
|
limit_val_batches=limit_val_batches,
|
||||||
|
limit_test_batches=limit_test_batches,
|
||||||
|
weights_summary=weights_summary,
|
||||||
|
max_epochs=max_epochs)
|
||||||
|
trainer.fit(task)
|
||||||
|
return save_dir, exp_name
|
||||||
|
|
||||||
|
|
||||||
|
def test(ckpt_path,
|
||||||
|
visualize=False,
|
||||||
|
deploy=False,
|
||||||
|
limit_test_batches=1.0,
|
||||||
|
gpus=1,
|
||||||
|
deploy_meta_path="/home/haosheng/dataset/camera/deployment/16cityp1.csv",
|
||||||
|
test_batch_size=1,
|
||||||
|
**kwargs):
|
||||||
|
"""
|
||||||
|
Run the testing experiment.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
ckpt_path: Path for the experiment to load
|
||||||
|
gpus: int. (ie: 2 gpus)
|
||||||
|
OR list to specify which GPUs [0, 1] OR '0,1'
|
||||||
|
OR '-1' / -1 to use all available gpus
|
||||||
|
Returns: None
|
||||||
|
|
||||||
|
"""
|
||||||
|
task = load_task(ckpt_path,
|
||||||
|
visualize=visualize,
|
||||||
|
deploy=deploy,
|
||||||
|
deploy_meta_path=deploy_meta_path,
|
||||||
|
test_batch_size=test_batch_size,
|
||||||
|
**kwargs)
|
||||||
|
trainer = Trainer(gpus=gpus,
|
||||||
|
limit_test_batches=limit_test_batches)
|
||||||
|
trainer.test(task)
|
||||||
|
|
||||||
|
|
||||||
|
def nni():
|
||||||
|
run_nni(train, test)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
fire.Fire()
|
||||||
14
detection/models/__init__.py
Normal file
14
detection/models/__init__.py
Normal file
|
|
@ -0,0 +1,14 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
from util import Args
|
||||||
|
from .classification import *
|
||||||
|
from .detection import *
|
||||||
|
|
||||||
|
|
||||||
|
def get_model(model_args):
|
||||||
|
model_args_ = model_args
|
||||||
|
|
||||||
|
if isinstance(model_args, argparse.Namespace):
|
||||||
|
model_args_ = Args(vars(model_args))
|
||||||
|
|
||||||
|
return globals().copy()[model_args_.get("model")](model_args_)
|
||||||
238
detection/models/classification.py
Normal file
238
detection/models/classification.py
Normal file
|
|
@ -0,0 +1,238 @@
|
||||||
|
import pretrainedmodels
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from torchvision import models
|
||||||
|
from efficientnet_pytorch import EfficientNet
|
||||||
|
|
||||||
|
|
||||||
|
class PretrainedModel(nn.Module):
|
||||||
|
"""Pretrained model, either from Cadene or TorchVision."""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super(PretrainedModel, self).__init__()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
raise NotImplementedError('Subclass of PretrainedModel ' +
|
||||||
|
'must implement forward method.')
|
||||||
|
|
||||||
|
def fine_tuning_parameters(self, boundary_layers, lrs):
|
||||||
|
"""Get a list of parameter groups that can be passed to an optimizer.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
boundary_layers: List of names for the boundary layers.
|
||||||
|
lrs: List of learning rates for each parameter group, from earlier
|
||||||
|
to later layers.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
param_groups: List of dictionaries, one per parameter group.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def gen_params(start_layer, end_layer):
|
||||||
|
saw_start_layer = False
|
||||||
|
for name, param in self.named_parameters():
|
||||||
|
if end_layer is not None and name == end_layer:
|
||||||
|
# Saw the last layer -> done
|
||||||
|
return
|
||||||
|
if start_layer is None or name == start_layer:
|
||||||
|
# Saw the first layer -> Start returning layers
|
||||||
|
saw_start_layer = True
|
||||||
|
|
||||||
|
if saw_start_layer:
|
||||||
|
yield param
|
||||||
|
|
||||||
|
if len(lrs) != boundary_layers + 1:
|
||||||
|
raise ValueError(f'Got {boundary_layers + 1} param groups, ' +
|
||||||
|
f'but {lrs} learning rates')
|
||||||
|
|
||||||
|
# Fine-tune the network's layers from encoder.2 onwards
|
||||||
|
boundary_layers = [None] + boundary_layers + [None]
|
||||||
|
param_groups = []
|
||||||
|
for i in range(len(boundary_layers) - 1):
|
||||||
|
start, end = boundary_layers[i:i + 2]
|
||||||
|
param_groups.append({'params': gen_params(start, end),
|
||||||
|
'lr': lrs[i]})
|
||||||
|
return param_groups
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetModel(PretrainedModel):
|
||||||
|
"""EfficientNet models:
|
||||||
|
https://github.com/lukemelas/EfficientNet-PyTorch
|
||||||
|
"""
|
||||||
|
def __init__(self, model_name, model_args=None):
|
||||||
|
super().__init__()
|
||||||
|
num_classes = model_args.get("num_classes", None)
|
||||||
|
pretrained = model_args.get("pretrained", False)
|
||||||
|
|
||||||
|
if pretrained:
|
||||||
|
self.model = EfficientNet.from_pretrained(
|
||||||
|
model_name, num_classes=num_classes)
|
||||||
|
else:
|
||||||
|
self.model = EfficientNet.from_name(
|
||||||
|
model_name, num_classes=num_classes)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.model(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class CadeneModel(PretrainedModel):
|
||||||
|
"""Models from Cadene's GitHub page of pretrained networks:
|
||||||
|
https://github.com/Cadene/pretrained-models.pytorch
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, model_name, model_args=None):
|
||||||
|
super(CadeneModel, self).__init__()
|
||||||
|
|
||||||
|
model_class = pretrainedmodels.__dict__[model_name]
|
||||||
|
pretrained = "imagenet" if model_args['pretrained'] else None
|
||||||
|
self.model = model_class(num_classes=1000,
|
||||||
|
pretrained=pretrained)
|
||||||
|
self.pool = nn.AdaptiveAvgPool2d(1)
|
||||||
|
|
||||||
|
num_ftrs = self.model.last_linear.in_features
|
||||||
|
self.fc = nn.Linear(num_ftrs, model_args['num_classes'])
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.model.features(x)
|
||||||
|
x = F.relu(x, inplace=False)
|
||||||
|
x = self.pool(x).view(x.size(0), -1)
|
||||||
|
x = self.fc(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class TorchVisionModel(PretrainedModel):
|
||||||
|
"""Models from TorchVision's GitHub page of pretrained neural networks:
|
||||||
|
https://github.com/pytorch/vision/tree/master/torchvision/models
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, model_fn, model_args):
|
||||||
|
super(TorchVisionModel, self).__init__()
|
||||||
|
|
||||||
|
self.model = model_fn(pretrained=model_args.pretrained)
|
||||||
|
self.pool = nn.AdaptiveAvgPool2d(1)
|
||||||
|
|
||||||
|
num_outputs = model_args['num_classes']
|
||||||
|
|
||||||
|
if 'fc' in self.model.__dict__:
|
||||||
|
num_ftrs = self.model.classifier.in_features
|
||||||
|
self.model.fc = nn.Linear(num_ftrs, num_outputs)
|
||||||
|
elif 'classifier' in self.model.__dict__:
|
||||||
|
num_ftrs = self.model.classifier.in_features
|
||||||
|
self.model.classifier = nn.Linear(num_ftrs, num_outputs)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.model.features(x)
|
||||||
|
x = F.relu(x, inplace=False)
|
||||||
|
x = self.pool(x).view(x.size(0), -1)
|
||||||
|
x = self.model.classifier(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB0(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b0', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB1(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b1', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB2(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b2', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB3(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b3', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB4(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b4', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB5(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b5', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB6(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b6', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNetB7(EfficientNetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('efficientnet-b7', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class DenseNet121(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(DenseNet121, self).__init__(models.densenet121, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class DenseNet161(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(DenseNet161, self).__init__(models.densenet161, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class DenseNet201(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(DenseNet201, self).__init__(models.densenet201, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class ResNet101(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(ResNet101, self).__init__(models.resnet101, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class ResNet152(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(ResNet152, self).__init__(models.resnet152, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class Inceptionv3(TorchVisionModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(Inceptionv3, self).__init__(models.inception_v3, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class Inceptionv4(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(Inceptionv4, self).__init__('inceptionv4', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class ResNet18(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(ResNet18, self).__init__('resnet18', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class ResNet34(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(ResNet34, self).__init__('resnet34', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class ResNeXt101(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(ResNeXt101, self).__init__('resnext101_64x4d', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class NASNetA(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(NASNetA, self).__init__('nasnetalarge', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class MNASNet(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(MNASNet, self).__init__('nasnetamobile', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class SENet154(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(SENet154, self).__init__('senet154', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class SEResNeXt101(CadeneModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super(SEResNeXt101, self).__init__('se_resnext101_32x4d', model_args)
|
||||||
3
detection/models/detection/__init__.py
Normal file
3
detection/models/detection/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
||||||
|
from .detectron import *
|
||||||
|
from .efficientdet import *
|
||||||
|
from .yolo import *
|
||||||
98
detection/models/detection/detectron.py
Normal file
98
detection/models/detection/detectron.py
Normal file
|
|
@ -0,0 +1,98 @@
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from detectron2.config import get_cfg
|
||||||
|
from detectron2 import model_zoo
|
||||||
|
from detectron2.modeling import build_model
|
||||||
|
from detectron2.utils.events import EventStorage
|
||||||
|
from detectron2.structures import Instances, Boxes
|
||||||
|
from detectron2.checkpoint import DetectionCheckpointer
|
||||||
|
|
||||||
|
|
||||||
|
class Detectron2Model(nn.Module):
|
||||||
|
"""Detectron2 model:
|
||||||
|
https://github.com/facebookresearch/detectron2
|
||||||
|
"""
|
||||||
|
MODEL_CONFIG = {
|
||||||
|
"mask_rcnn": "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml",
|
||||||
|
"faster_rcnn": "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml",
|
||||||
|
"retinanet": "COCO-Detection/retinanet_R_50_FPN_3x.yaml",
|
||||||
|
"rpn": "COCO-Detection/rpn_R_50_FPN_1x.yaml",
|
||||||
|
"fast_rcnn": "COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml"}
|
||||||
|
|
||||||
|
def __init__(self, model_name, model_args=None):
|
||||||
|
super().__init__()
|
||||||
|
num_classes = model_args.get("num_classes", None)
|
||||||
|
pretrained = model_args.get("pretrained", False)
|
||||||
|
nms_threshold = model_args.get("nms_threshold", 0.5)
|
||||||
|
if model_args.get("gpus", None) is None:
|
||||||
|
device = "cpu"
|
||||||
|
else:
|
||||||
|
device = "cuda"
|
||||||
|
|
||||||
|
self.cfg = get_cfg()
|
||||||
|
config_path = self.MODEL_CONFIG[model_name]
|
||||||
|
self.cfg.merge_from_file(model_zoo.get_config_file(config_path))
|
||||||
|
|
||||||
|
# Update number of classes
|
||||||
|
self.cfg.MODEL.ROI_HEADS.NUM_CLASSES = num_classes
|
||||||
|
self.cfg.MODEL.RETINANET.NUM_CLASSES = num_classes
|
||||||
|
|
||||||
|
# Segmentation
|
||||||
|
self.cfg.INPUT.MASK_FORMAT='bitmask'
|
||||||
|
|
||||||
|
# NMS
|
||||||
|
self.cfg.MODEL.ROI_HEADS.NMS_THRESH_TEST = nms_threshold
|
||||||
|
self.cfg.MODEL.RPN.NMS_THRESH_TEST = nms_threshold
|
||||||
|
|
||||||
|
self.cfg.MODEL.DEVICE = device
|
||||||
|
model = build_model(self.cfg)
|
||||||
|
|
||||||
|
# Load pretrained model
|
||||||
|
if pretrained:
|
||||||
|
DetectionCheckpointer(model).load(
|
||||||
|
model_zoo.get_checkpoint_url(config_path))
|
||||||
|
|
||||||
|
self.model = model
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
if self.training:
|
||||||
|
with EventStorage() as storage:
|
||||||
|
out = self.model(x)
|
||||||
|
else:
|
||||||
|
self.model.train()
|
||||||
|
with torch.no_grad(), EventStorage() as storage:
|
||||||
|
out = self.model(x)
|
||||||
|
self.model.eval()
|
||||||
|
return out
|
||||||
|
|
||||||
|
def infer(self, x):
|
||||||
|
with torch.no_grad():
|
||||||
|
out = self.model(x)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class FasterRCNN(Detectron2Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('faster_rcnn', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class MaskRCNN(Detectron2Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('mask_rcnn', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class FastRCNN(Detectron2Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('fast_rcnn', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class RetinaNet(Detectron2Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('retinanet', model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class RPN(Detectron2Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__('rpn', model_args)
|
||||||
103
detection/models/detection/efficientdet/__init__.py
Normal file
103
detection/models/detection/efficientdet/__init__.py
Normal file
|
|
@ -0,0 +1,103 @@
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from detectron2.structures import Instances, Boxes
|
||||||
|
|
||||||
|
from .backbone import EfficientDetWithLoss
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetModel(nn.Module):
|
||||||
|
"""Detectron2 model:
|
||||||
|
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, compound_coef, model_args=None):
|
||||||
|
super().__init__()
|
||||||
|
num_classes = model_args.get("num_classes", None)
|
||||||
|
pretrained = model_args.get("pretrained", False)
|
||||||
|
self.max_bbox = model_args.get("max_bbox", 30)
|
||||||
|
|
||||||
|
self.model = EfficientDetWithLoss(num_classes=num_classes,
|
||||||
|
compound_coef=compound_coef,
|
||||||
|
load_weights=pretrained)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def to_numpy(v):
|
||||||
|
if isinstance(v, np.ndarray):
|
||||||
|
return v
|
||||||
|
else:
|
||||||
|
return v.detach().cpu().numpy()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
N = len(x)
|
||||||
|
imgs = torch.stack([sample['image'].float() for sample in x])
|
||||||
|
annotations = np.ones((N, self.max_bbox, 5)) * -1
|
||||||
|
for i, sample in enumerate(x):
|
||||||
|
instances = sample['instances']
|
||||||
|
boxes = self.to_numpy(instances.gt_boxes.tensor)
|
||||||
|
class_id = self.to_numpy(instances.gt_classes)
|
||||||
|
annotation = np.concatenate([boxes, class_id[:, np.newaxis]], 1)
|
||||||
|
if len(class_id) > self.max_bbox:
|
||||||
|
annotation = annotation[:self.max_bbox, :]
|
||||||
|
annotations[i, :len(class_id), :] = annotation
|
||||||
|
annotations = torch.from_numpy(annotations)
|
||||||
|
return self.model(imgs, annotations, is_train)
|
||||||
|
|
||||||
|
def infer(self, x):
|
||||||
|
imgs = torch.stack([sample['image'].float() for sample in x])
|
||||||
|
rois = self.model.infer(imgs)
|
||||||
|
outs = []
|
||||||
|
for sample_input, sample_output in zip(x, rois):
|
||||||
|
instances = Instances(
|
||||||
|
(sample_input['height'], sample_input['width']))
|
||||||
|
instances.pred_boxes = Boxes(sample_output['rois'])
|
||||||
|
instances.scores = torch.tensor(sample_output['scores'])
|
||||||
|
instances.pred_classes = torch.tensor(sample_output['class_ids'])
|
||||||
|
outs.append({"instances": instances})
|
||||||
|
return outs
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD0(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(0, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD1(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(1, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD2(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(2, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD3(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(3, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD4(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(4, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD5(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(5, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD6(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(6, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD7(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(7, model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetD7X(EfficientDetModel):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__(8, model_args)
|
||||||
119
detection/models/detection/efficientdet/backbone.py
Normal file
119
detection/models/detection/efficientdet/backbone.py
Normal file
|
|
@ -0,0 +1,119 @@
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
|
||||||
|
from .model import BiFPN, Regressor, Classifier, EfficientNet
|
||||||
|
from .utils import Anchors, BBoxTransform, ClipBoxes
|
||||||
|
from .process import postprocess
|
||||||
|
from .loss import FocalLoss
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetWithLoss(nn.Module):
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super().__init__()
|
||||||
|
self.model = EfficientDetBackbone(**kwargs)
|
||||||
|
self.criterion = FocalLoss()
|
||||||
|
self.threshold = kwargs.get("threshold", 0.2)
|
||||||
|
self.iou_threshold = kwargs.get("iou_threshold", 0.2)
|
||||||
|
|
||||||
|
def forward(self, imgs, annotations):
|
||||||
|
if self.training:
|
||||||
|
features, regression, classification, anchors = self.model(imgs)
|
||||||
|
cls_loss, reg_loss = self.criterion(classification, regression, anchors, annotations)
|
||||||
|
else:
|
||||||
|
with torch.no_grad():
|
||||||
|
features, regression, classification, anchors = self.model(imgs)
|
||||||
|
cls_loss, reg_loss = self.criterion(classification, regression, anchors, annotations)
|
||||||
|
losses = {"cls_loss": cls_loss, "reg_loss": reg_loss}
|
||||||
|
return losses
|
||||||
|
|
||||||
|
def infer(self, imgs):
|
||||||
|
with torch.no_grad():
|
||||||
|
features, regression, classification, anchors = self.model(imgs)
|
||||||
|
regressBoxes = BBoxTransform()
|
||||||
|
clipBoxes = ClipBoxes()
|
||||||
|
|
||||||
|
out = postprocess(imgs,
|
||||||
|
anchors, regression, classification,
|
||||||
|
regressBoxes, clipBoxes,
|
||||||
|
self.threshold, self.iou_threshold)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientDetBackbone(nn.Module):
|
||||||
|
def __init__(self, num_classes=80, compound_coef=0, load_weights=False, **kwargs):
|
||||||
|
super().__init__()
|
||||||
|
self.compound_coef = compound_coef
|
||||||
|
|
||||||
|
self.backbone_compound_coef = [0, 1, 2, 3, 4, 5, 6, 6, 7]
|
||||||
|
self.fpn_num_filters = [64, 88, 112, 160, 224, 288, 384, 384, 384]
|
||||||
|
self.fpn_cell_repeats = [3, 4, 5, 6, 7, 7, 8, 8, 8]
|
||||||
|
self.input_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536]
|
||||||
|
self.box_class_repeats = [3, 3, 3, 4, 4, 4, 5, 5, 5]
|
||||||
|
self.pyramid_levels = [5, 5, 5, 5, 5, 5, 5, 5, 6]
|
||||||
|
self.anchor_scale = [4., 4., 4., 4., 4., 4., 4., 5., 4.]
|
||||||
|
self.aspect_ratios = kwargs.get('ratios', [(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)])
|
||||||
|
self.num_scales = len(kwargs.get('scales', [2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]))
|
||||||
|
conv_channel_coef = {
|
||||||
|
# the channels of P3/P4/P5.
|
||||||
|
0: [40, 112, 320],
|
||||||
|
1: [40, 112, 320],
|
||||||
|
2: [48, 120, 352],
|
||||||
|
3: [48, 136, 384],
|
||||||
|
4: [56, 160, 448],
|
||||||
|
5: [64, 176, 512],
|
||||||
|
6: [72, 200, 576],
|
||||||
|
7: [72, 200, 576],
|
||||||
|
8: [80, 224, 640],
|
||||||
|
}
|
||||||
|
|
||||||
|
num_anchors = len(self.aspect_ratios) * self.num_scales
|
||||||
|
|
||||||
|
self.bifpn = nn.Sequential(
|
||||||
|
*[BiFPN(self.fpn_num_filters[self.compound_coef],
|
||||||
|
conv_channel_coef[compound_coef],
|
||||||
|
True if _ == 0 else False,
|
||||||
|
attention=True if compound_coef < 6 else False,
|
||||||
|
use_p8=compound_coef > 7)
|
||||||
|
for _ in range(self.fpn_cell_repeats[compound_coef])])
|
||||||
|
|
||||||
|
self.num_classes = num_classes
|
||||||
|
self.regressor = Regressor(in_channels=self.fpn_num_filters[self.compound_coef], num_anchors=num_anchors,
|
||||||
|
num_layers=self.box_class_repeats[self.compound_coef],
|
||||||
|
pyramid_levels=self.pyramid_levels[self.compound_coef])
|
||||||
|
self.classifier = Classifier(in_channels=self.fpn_num_filters[self.compound_coef], num_anchors=num_anchors,
|
||||||
|
num_classes=num_classes,
|
||||||
|
num_layers=self.box_class_repeats[self.compound_coef],
|
||||||
|
pyramid_levels=self.pyramid_levels[self.compound_coef])
|
||||||
|
|
||||||
|
self.anchors = Anchors(anchor_scale=self.anchor_scale[compound_coef],
|
||||||
|
pyramid_levels=(torch.arange(self.pyramid_levels[self.compound_coef]) + 3).tolist(),
|
||||||
|
**kwargs)
|
||||||
|
|
||||||
|
self.backbone_net = EfficientNet(self.backbone_compound_coef[compound_coef], load_weights)
|
||||||
|
|
||||||
|
def freeze_bn(self):
|
||||||
|
for m in self.modules():
|
||||||
|
if isinstance(m, nn.BatchNorm2d):
|
||||||
|
m.eval()
|
||||||
|
|
||||||
|
def forward(self, inputs):
|
||||||
|
max_size = inputs.shape[-1]
|
||||||
|
|
||||||
|
_, p3, p4, p5 = self.backbone_net(inputs)
|
||||||
|
|
||||||
|
features = (p3, p4, p5)
|
||||||
|
features = self.bifpn(features)
|
||||||
|
|
||||||
|
regression = self.regressor(features)
|
||||||
|
classification = self.classifier(features)
|
||||||
|
anchors = self.anchors(inputs, inputs.dtype)
|
||||||
|
|
||||||
|
return features, regression, classification, anchors
|
||||||
|
|
||||||
|
def init_backbone(self, path):
|
||||||
|
state_dict = torch.load(path)
|
||||||
|
try:
|
||||||
|
ret = self.load_state_dict(state_dict, strict=False)
|
||||||
|
print(ret)
|
||||||
|
except RuntimeError as e:
|
||||||
|
print('Ignoring ' + str(e) + '"')
|
||||||
26
detection/models/detection/efficientdet/config.py
Normal file
26
detection/models/detection/efficientdet/config.py
Normal file
|
|
@ -0,0 +1,26 @@
|
||||||
|
COCO_CLASSES = ["person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat",
|
||||||
|
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog",
|
||||||
|
"horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella",
|
||||||
|
"handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite",
|
||||||
|
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle",
|
||||||
|
"wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange",
|
||||||
|
"broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant",
|
||||||
|
"bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
|
||||||
|
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors",
|
||||||
|
"teddy bear", "hair drier", "toothbrush"]
|
||||||
|
|
||||||
|
colors = [(39, 129, 113), (164, 80, 133), (83, 122, 114), (99, 81, 172), (95, 56, 104), (37, 84, 86), (14, 89, 122),
|
||||||
|
(80, 7, 65), (10, 102, 25), (90, 185, 109), (106, 110, 132), (169, 158, 85), (188, 185, 26), (103, 1, 17),
|
||||||
|
(82, 144, 81), (92, 7, 184), (49, 81, 155), (179, 177, 69), (93, 187, 158), (13, 39, 73), (12, 50, 60),
|
||||||
|
(16, 179, 33), (112, 69, 165), (15, 139, 63), (33, 191, 159), (182, 173, 32), (34, 113, 133), (90, 135, 34),
|
||||||
|
(53, 34, 86), (141, 35, 190), (6, 171, 8), (118, 76, 112), (89, 60, 55), (15, 54, 88), (112, 75, 181),
|
||||||
|
(42, 147, 38), (138, 52, 63), (128, 65, 149), (106, 103, 24), (168, 33, 45), (28, 136, 135), (86, 91, 108),
|
||||||
|
(52, 11, 76), (142, 6, 189), (57, 81, 168), (55, 19, 148), (182, 101, 89), (44, 65, 179), (1, 33, 26),
|
||||||
|
(122, 164, 26), (70, 63, 134), (137, 106, 82), (120, 118, 52), (129, 74, 42), (182, 147, 112), (22, 157, 50),
|
||||||
|
(56, 50, 20), (2, 22, 177), (156, 100, 106), (21, 35, 42), (13, 8, 121), (142, 92, 28), (45, 118, 33),
|
||||||
|
(105, 118, 30), (7, 185, 124), (46, 34, 146), (105, 184, 169), (22, 18, 5), (147, 71, 73), (181, 64, 91),
|
||||||
|
(31, 39, 184), (164, 179, 33), (96, 50, 18), (95, 15, 106), (113, 68, 54), (136, 116, 112), (119, 139, 130),
|
||||||
|
(31, 139, 34), (66, 6, 127), (62, 39, 2), (49, 99, 180), (49, 119, 155), (153, 50, 183), (125, 38, 3),
|
||||||
|
(129, 87, 143), (49, 87, 40), (128, 62, 120), (73, 85, 148), (28, 144, 118), (29, 9, 24), (175, 45, 108),
|
||||||
|
(81, 175, 64), (178, 19, 157), (74, 188, 190), (18, 114, 2), (62, 128, 96), (21, 3, 150), (0, 6, 95),
|
||||||
|
(2, 20, 184), (122, 37, 185)]
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
__version__ = "0.6.1"
|
||||||
|
from .model import EfficientNet
|
||||||
|
from .utils import (
|
||||||
|
GlobalParams,
|
||||||
|
BlockArgs,
|
||||||
|
BlockDecoder,
|
||||||
|
efficientnet,
|
||||||
|
get_model_params,
|
||||||
|
)
|
||||||
|
|
||||||
237
detection/models/detection/efficientdet/efficientnet/model.py
Normal file
237
detection/models/detection/efficientdet/efficientnet/model.py
Normal file
|
|
@ -0,0 +1,237 @@
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
from torch.nn import functional as F
|
||||||
|
|
||||||
|
from .utils import (
|
||||||
|
round_filters,
|
||||||
|
round_repeats,
|
||||||
|
drop_connect,
|
||||||
|
get_same_padding_conv2d,
|
||||||
|
get_model_params,
|
||||||
|
efficientnet_params,
|
||||||
|
load_pretrained_weights,
|
||||||
|
Swish,
|
||||||
|
MemoryEfficientSwish,
|
||||||
|
)
|
||||||
|
|
||||||
|
class MBConvBlock(nn.Module):
|
||||||
|
"""
|
||||||
|
Mobile Inverted Residual Bottleneck Block
|
||||||
|
|
||||||
|
Args:
|
||||||
|
block_args (namedtuple): BlockArgs, see above
|
||||||
|
global_params (namedtuple): GlobalParam, see above
|
||||||
|
|
||||||
|
Attributes:
|
||||||
|
has_se (bool): Whether the block contains a Squeeze and Excitation layer.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, block_args, global_params):
|
||||||
|
super().__init__()
|
||||||
|
self._block_args = block_args
|
||||||
|
self._bn_mom = 1 - global_params.batch_norm_momentum
|
||||||
|
self._bn_eps = global_params.batch_norm_epsilon
|
||||||
|
self.has_se = (self._block_args.se_ratio is not None) and (0 < self._block_args.se_ratio <= 1)
|
||||||
|
self.id_skip = block_args.id_skip # skip connection and drop connect
|
||||||
|
|
||||||
|
# Get static or dynamic convolution depending on image size
|
||||||
|
Conv2d = get_same_padding_conv2d(image_size=global_params.image_size)
|
||||||
|
|
||||||
|
# Expansion phase
|
||||||
|
inp = self._block_args.input_filters # number of input channels
|
||||||
|
oup = self._block_args.input_filters * self._block_args.expand_ratio # number of output channels
|
||||||
|
if self._block_args.expand_ratio != 1:
|
||||||
|
self._expand_conv = Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
|
||||||
|
self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
|
||||||
|
|
||||||
|
# Depthwise convolution phase
|
||||||
|
k = self._block_args.kernel_size
|
||||||
|
s = self._block_args.stride
|
||||||
|
self._depthwise_conv = Conv2d(
|
||||||
|
in_channels=oup, out_channels=oup, groups=oup, # groups makes it depthwise
|
||||||
|
kernel_size=k, stride=s, bias=False)
|
||||||
|
self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
|
||||||
|
|
||||||
|
# Squeeze and Excitation layer, if desired
|
||||||
|
if self.has_se:
|
||||||
|
num_squeezed_channels = max(1, int(self._block_args.input_filters * self._block_args.se_ratio))
|
||||||
|
self._se_reduce = Conv2d(in_channels=oup, out_channels=num_squeezed_channels, kernel_size=1)
|
||||||
|
self._se_expand = Conv2d(in_channels=num_squeezed_channels, out_channels=oup, kernel_size=1)
|
||||||
|
|
||||||
|
# Output phase
|
||||||
|
final_oup = self._block_args.output_filters
|
||||||
|
self._project_conv = Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
|
||||||
|
self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._bn_mom, eps=self._bn_eps)
|
||||||
|
self._swish = MemoryEfficientSwish()
|
||||||
|
|
||||||
|
def forward(self, inputs, drop_connect_rate=None):
|
||||||
|
"""
|
||||||
|
:param inputs: input tensor
|
||||||
|
:param drop_connect_rate: drop connect rate (float, between 0 and 1)
|
||||||
|
:return: output of block
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Expansion and Depthwise Convolution
|
||||||
|
x = inputs
|
||||||
|
if self._block_args.expand_ratio != 1:
|
||||||
|
x = self._expand_conv(inputs)
|
||||||
|
x = self._bn0(x)
|
||||||
|
x = self._swish(x)
|
||||||
|
|
||||||
|
x = self._depthwise_conv(x)
|
||||||
|
x = self._bn1(x)
|
||||||
|
x = self._swish(x)
|
||||||
|
|
||||||
|
# Squeeze and Excitation
|
||||||
|
if self.has_se:
|
||||||
|
x_squeezed = F.adaptive_avg_pool2d(x, 1)
|
||||||
|
x_squeezed = self._se_reduce(x_squeezed)
|
||||||
|
x_squeezed = self._swish(x_squeezed)
|
||||||
|
x_squeezed = self._se_expand(x_squeezed)
|
||||||
|
x = torch.sigmoid(x_squeezed) * x
|
||||||
|
|
||||||
|
x = self._project_conv(x)
|
||||||
|
x = self._bn2(x)
|
||||||
|
|
||||||
|
# Skip connection and drop connect
|
||||||
|
input_filters, output_filters = self._block_args.input_filters, self._block_args.output_filters
|
||||||
|
if self.id_skip and self._block_args.stride == 1 and input_filters == output_filters:
|
||||||
|
if drop_connect_rate:
|
||||||
|
x = drop_connect(x, p=drop_connect_rate, training=self.training)
|
||||||
|
x = x + inputs # skip connection
|
||||||
|
return x
|
||||||
|
|
||||||
|
def set_swish(self, memory_efficient=True):
|
||||||
|
"""Sets swish function as memory efficient (for training) or standard (for export)"""
|
||||||
|
self._swish = MemoryEfficientSwish() if memory_efficient else Swish()
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNet(nn.Module):
|
||||||
|
"""
|
||||||
|
An EfficientNet model. Most easily loaded with the .from_name or .from_pretrained methods
|
||||||
|
|
||||||
|
Args:
|
||||||
|
blocks_args (list): A list of BlockArgs to construct blocks
|
||||||
|
global_params (namedtuple): A set of GlobalParams shared between blocks
|
||||||
|
|
||||||
|
Example:
|
||||||
|
model = EfficientNet.from_pretrained('efficientnet-b0')
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, blocks_args=None, global_params=None):
|
||||||
|
super().__init__()
|
||||||
|
assert isinstance(blocks_args, list), 'blocks_args should be a list'
|
||||||
|
assert len(blocks_args) > 0, 'block args must be greater than 0'
|
||||||
|
self._global_params = global_params
|
||||||
|
self._blocks_args = blocks_args
|
||||||
|
|
||||||
|
# Get static or dynamic convolution depending on image size
|
||||||
|
Conv2d = get_same_padding_conv2d(image_size=global_params.image_size)
|
||||||
|
|
||||||
|
# Batch norm parameters
|
||||||
|
bn_mom = 1 - self._global_params.batch_norm_momentum
|
||||||
|
bn_eps = self._global_params.batch_norm_epsilon
|
||||||
|
|
||||||
|
# Stem
|
||||||
|
in_channels = 3 # rgb
|
||||||
|
out_channels = round_filters(32, self._global_params) # number of output channels
|
||||||
|
self._conv_stem = Conv2d(in_channels, out_channels, kernel_size=3, stride=2, bias=False)
|
||||||
|
self._bn0 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
|
||||||
|
|
||||||
|
# Build blocks
|
||||||
|
self._blocks = nn.ModuleList([])
|
||||||
|
for block_args in self._blocks_args:
|
||||||
|
|
||||||
|
# Update block input and output filters based on depth multiplier.
|
||||||
|
block_args = block_args._replace(
|
||||||
|
input_filters=round_filters(block_args.input_filters, self._global_params),
|
||||||
|
output_filters=round_filters(block_args.output_filters, self._global_params),
|
||||||
|
num_repeat=round_repeats(block_args.num_repeat, self._global_params)
|
||||||
|
)
|
||||||
|
|
||||||
|
# The first block needs to take care of stride and filter size increase.
|
||||||
|
self._blocks.append(MBConvBlock(block_args, self._global_params))
|
||||||
|
if block_args.num_repeat > 1:
|
||||||
|
block_args = block_args._replace(input_filters=block_args.output_filters, stride=1)
|
||||||
|
for _ in range(block_args.num_repeat - 1):
|
||||||
|
self._blocks.append(MBConvBlock(block_args, self._global_params))
|
||||||
|
|
||||||
|
# Head
|
||||||
|
in_channels = block_args.output_filters # output of final block
|
||||||
|
out_channels = round_filters(1280, self._global_params)
|
||||||
|
self._conv_head = Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
|
||||||
|
self._bn1 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
|
||||||
|
|
||||||
|
# Final linear layer
|
||||||
|
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
|
||||||
|
self._dropout = nn.Dropout(self._global_params.dropout_rate)
|
||||||
|
self._fc = nn.Linear(out_channels, self._global_params.num_classes)
|
||||||
|
self._swish = MemoryEfficientSwish()
|
||||||
|
|
||||||
|
def set_swish(self, memory_efficient=True):
|
||||||
|
"""Sets swish function as memory efficient (for training) or standard (for export)"""
|
||||||
|
self._swish = MemoryEfficientSwish() if memory_efficient else Swish()
|
||||||
|
for block in self._blocks:
|
||||||
|
block.set_swish(memory_efficient)
|
||||||
|
|
||||||
|
|
||||||
|
def extract_features(self, inputs):
|
||||||
|
""" Returns output of the final convolution layer """
|
||||||
|
|
||||||
|
# Stem
|
||||||
|
x = self._swish(self._bn0(self._conv_stem(inputs)))
|
||||||
|
|
||||||
|
# Blocks
|
||||||
|
for idx, block in enumerate(self._blocks):
|
||||||
|
drop_connect_rate = self._global_params.drop_connect_rate
|
||||||
|
if drop_connect_rate:
|
||||||
|
drop_connect_rate *= float(idx) / len(self._blocks)
|
||||||
|
x = block(x, drop_connect_rate=drop_connect_rate)
|
||||||
|
# Head
|
||||||
|
x = self._swish(self._bn1(self._conv_head(x)))
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
def forward(self, inputs):
|
||||||
|
""" Calls extract_features to extract features, applies final linear layer, and returns logits. """
|
||||||
|
bs = inputs.size(0)
|
||||||
|
# Convolution layers
|
||||||
|
x = self.extract_features(inputs)
|
||||||
|
|
||||||
|
# Pooling and final linear layer
|
||||||
|
x = self._avg_pooling(x)
|
||||||
|
x = x.view(bs, -1)
|
||||||
|
x = self._dropout(x)
|
||||||
|
x = self._fc(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_name(cls, model_name, override_params=None):
|
||||||
|
cls._check_model_name_is_valid(model_name)
|
||||||
|
blocks_args, global_params = get_model_params(model_name, override_params)
|
||||||
|
return cls(blocks_args, global_params)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_pretrained(cls, model_name, load_weights=True, advprop=False, num_classes=1000, in_channels=3):
|
||||||
|
model = cls.from_name(model_name, override_params={'num_classes': num_classes})
|
||||||
|
if load_weights:
|
||||||
|
load_pretrained_weights(model, model_name, load_fc=(num_classes == 1000), advprop=advprop)
|
||||||
|
if in_channels != 3:
|
||||||
|
Conv2d = get_same_padding_conv2d(image_size = model._global_params.image_size)
|
||||||
|
out_channels = round_filters(32, model._global_params)
|
||||||
|
model._conv_stem = Conv2d(in_channels, out_channels, kernel_size=3, stride=2, bias=False)
|
||||||
|
return model
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_image_size(cls, model_name):
|
||||||
|
cls._check_model_name_is_valid(model_name)
|
||||||
|
_, _, res, _ = efficientnet_params(model_name)
|
||||||
|
return res
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _check_model_name_is_valid(cls, model_name):
|
||||||
|
""" Validates model name. """
|
||||||
|
valid_models = ['efficientnet-b'+str(i) for i in range(9)]
|
||||||
|
if model_name not in valid_models:
|
||||||
|
raise ValueError('model_name should be one of: ' + ', '.join(valid_models))
|
||||||
313
detection/models/detection/efficientdet/efficientnet/utils.py
Normal file
313
detection/models/detection/efficientdet/efficientnet/utils.py
Normal file
|
|
@ -0,0 +1,313 @@
|
||||||
|
"""
|
||||||
|
This file contains helper functions for building the model and for loading model parameters.
|
||||||
|
These helper functions are built to mirror those in the official TensorFlow implementation.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import re
|
||||||
|
import math
|
||||||
|
import collections
|
||||||
|
from functools import partial
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
from torch.nn import functional as F
|
||||||
|
from torch.utils import model_zoo
|
||||||
|
from .utils_extra import Conv2dStaticSamePadding
|
||||||
|
|
||||||
|
########################################################################
|
||||||
|
############### HELPERS FUNCTIONS FOR MODEL ARCHITECTURE ###############
|
||||||
|
########################################################################
|
||||||
|
|
||||||
|
|
||||||
|
# Parameters for the entire model (stem, all blocks, and head)
|
||||||
|
|
||||||
|
GlobalParams = collections.namedtuple('GlobalParams', [
|
||||||
|
'batch_norm_momentum', 'batch_norm_epsilon', 'dropout_rate',
|
||||||
|
'num_classes', 'width_coefficient', 'depth_coefficient',
|
||||||
|
'depth_divisor', 'min_depth', 'drop_connect_rate', 'image_size'])
|
||||||
|
|
||||||
|
# Parameters for an individual model block
|
||||||
|
BlockArgs = collections.namedtuple('BlockArgs', [
|
||||||
|
'kernel_size', 'num_repeat', 'input_filters', 'output_filters',
|
||||||
|
'expand_ratio', 'id_skip', 'stride', 'se_ratio'])
|
||||||
|
|
||||||
|
# Change namedtuple defaults
|
||||||
|
GlobalParams.__new__.__defaults__ = (None,) * len(GlobalParams._fields)
|
||||||
|
BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields)
|
||||||
|
|
||||||
|
|
||||||
|
class SwishImplementation(torch.autograd.Function):
|
||||||
|
@staticmethod
|
||||||
|
def forward(ctx, i):
|
||||||
|
result = i * torch.sigmoid(i)
|
||||||
|
ctx.save_for_backward(i)
|
||||||
|
return result
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def backward(ctx, grad_output):
|
||||||
|
i = ctx.saved_variables[0]
|
||||||
|
sigmoid_i = torch.sigmoid(i)
|
||||||
|
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
|
||||||
|
|
||||||
|
|
||||||
|
class MemoryEfficientSwish(nn.Module):
|
||||||
|
def forward(self, x):
|
||||||
|
return SwishImplementation.apply(x)
|
||||||
|
|
||||||
|
|
||||||
|
class Swish(nn.Module):
|
||||||
|
def forward(self, x):
|
||||||
|
return x * torch.sigmoid(x)
|
||||||
|
|
||||||
|
|
||||||
|
def round_filters(filters, global_params):
|
||||||
|
""" Calculate and round number of filters based on depth multiplier. """
|
||||||
|
multiplier = global_params.width_coefficient
|
||||||
|
if not multiplier:
|
||||||
|
return filters
|
||||||
|
divisor = global_params.depth_divisor
|
||||||
|
min_depth = global_params.min_depth
|
||||||
|
filters *= multiplier
|
||||||
|
min_depth = min_depth or divisor
|
||||||
|
new_filters = max(min_depth, int(filters + divisor / 2) // divisor * divisor)
|
||||||
|
if new_filters < 0.9 * filters: # prevent rounding by more than 10%
|
||||||
|
new_filters += divisor
|
||||||
|
return int(new_filters)
|
||||||
|
|
||||||
|
|
||||||
|
def round_repeats(repeats, global_params):
|
||||||
|
""" Round number of filters based on depth multiplier. """
|
||||||
|
multiplier = global_params.depth_coefficient
|
||||||
|
if not multiplier:
|
||||||
|
return repeats
|
||||||
|
return int(math.ceil(multiplier * repeats))
|
||||||
|
|
||||||
|
|
||||||
|
def drop_connect(inputs, p, training):
|
||||||
|
""" Drop connect. """
|
||||||
|
if not training: return inputs
|
||||||
|
batch_size = inputs.shape[0]
|
||||||
|
keep_prob = 1 - p
|
||||||
|
random_tensor = keep_prob
|
||||||
|
random_tensor += torch.rand([batch_size, 1, 1, 1], dtype=inputs.dtype, device=inputs.device)
|
||||||
|
binary_tensor = torch.floor(random_tensor)
|
||||||
|
output = inputs / keep_prob * binary_tensor
|
||||||
|
return output
|
||||||
|
|
||||||
|
|
||||||
|
def get_same_padding_conv2d(image_size=None):
|
||||||
|
""" Chooses static padding if you have specified an image size, and dynamic padding otherwise.
|
||||||
|
Static padding is necessary for ONNX exporting of models. """
|
||||||
|
if image_size is None:
|
||||||
|
return Conv2dDynamicSamePadding
|
||||||
|
else:
|
||||||
|
return partial(Conv2dStaticSamePadding, image_size=image_size)
|
||||||
|
|
||||||
|
|
||||||
|
class Conv2dDynamicSamePadding(nn.Conv2d):
|
||||||
|
""" 2D Convolutions like TensorFlow, for a dynamic image size """
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels, kernel_size, stride=1, dilation=1, groups=1, bias=True):
|
||||||
|
super().__init__(in_channels, out_channels, kernel_size, stride, 0, dilation, groups, bias)
|
||||||
|
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
ih, iw = x.size()[-2:]
|
||||||
|
kh, kw = self.weight.size()[-2:]
|
||||||
|
sh, sw = self.stride
|
||||||
|
oh, ow = math.ceil(ih / sh), math.ceil(iw / sw)
|
||||||
|
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
|
||||||
|
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
|
||||||
|
if pad_h > 0 or pad_w > 0:
|
||||||
|
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
|
||||||
|
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
|
||||||
|
|
||||||
|
|
||||||
|
class Identity(nn.Module):
|
||||||
|
def __init__(self, ):
|
||||||
|
super(Identity, self).__init__()
|
||||||
|
|
||||||
|
def forward(self, input):
|
||||||
|
return input
|
||||||
|
|
||||||
|
|
||||||
|
########################################################################
|
||||||
|
############## HELPERS FUNCTIONS FOR LOADING MODEL PARAMS ##############
|
||||||
|
########################################################################
|
||||||
|
|
||||||
|
|
||||||
|
def efficientnet_params(model_name):
|
||||||
|
""" Map EfficientNet model name to parameter coefficients. """
|
||||||
|
params_dict = {
|
||||||
|
# Coefficients: width,depth,res,dropout
|
||||||
|
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
|
||||||
|
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
|
||||||
|
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
|
||||||
|
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
|
||||||
|
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
|
||||||
|
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
|
||||||
|
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
|
||||||
|
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
|
||||||
|
'efficientnet-b8': (2.2, 3.6, 672, 0.5),
|
||||||
|
'efficientnet-l2': (4.3, 5.3, 800, 0.5),
|
||||||
|
}
|
||||||
|
return params_dict[model_name]
|
||||||
|
|
||||||
|
|
||||||
|
class BlockDecoder(object):
|
||||||
|
""" Block Decoder for readability, straight from the official TensorFlow repository """
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _decode_block_string(block_string):
|
||||||
|
""" Gets a block through a string notation of arguments. """
|
||||||
|
assert isinstance(block_string, str)
|
||||||
|
|
||||||
|
ops = block_string.split('_')
|
||||||
|
options = {}
|
||||||
|
for op in ops:
|
||||||
|
splits = re.split(r'(\d.*)', op)
|
||||||
|
if len(splits) >= 2:
|
||||||
|
key, value = splits[:2]
|
||||||
|
options[key] = value
|
||||||
|
|
||||||
|
# Check stride
|
||||||
|
assert (('s' in options and len(options['s']) == 1) or
|
||||||
|
(len(options['s']) == 2 and options['s'][0] == options['s'][1]))
|
||||||
|
|
||||||
|
return BlockArgs(
|
||||||
|
kernel_size=int(options['k']),
|
||||||
|
num_repeat=int(options['r']),
|
||||||
|
input_filters=int(options['i']),
|
||||||
|
output_filters=int(options['o']),
|
||||||
|
expand_ratio=int(options['e']),
|
||||||
|
id_skip=('noskip' not in block_string),
|
||||||
|
se_ratio=float(options['se']) if 'se' in options else None,
|
||||||
|
stride=[int(options['s'][0])])
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _encode_block_string(block):
|
||||||
|
"""Encodes a block to a string."""
|
||||||
|
args = [
|
||||||
|
'r%d' % block.num_repeat,
|
||||||
|
'k%d' % block.kernel_size,
|
||||||
|
's%d%d' % (block.strides[0], block.strides[1]),
|
||||||
|
'e%s' % block.expand_ratio,
|
||||||
|
'i%d' % block.input_filters,
|
||||||
|
'o%d' % block.output_filters
|
||||||
|
]
|
||||||
|
if 0 < block.se_ratio <= 1:
|
||||||
|
args.append('se%s' % block.se_ratio)
|
||||||
|
if block.id_skip is False:
|
||||||
|
args.append('noskip')
|
||||||
|
return '_'.join(args)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def decode(string_list):
|
||||||
|
"""
|
||||||
|
Decodes a list of string notations to specify blocks inside the network.
|
||||||
|
|
||||||
|
:param string_list: a list of strings, each string is a notation of block
|
||||||
|
:return: a list of BlockArgs namedtuples of block args
|
||||||
|
"""
|
||||||
|
assert isinstance(string_list, list)
|
||||||
|
blocks_args = []
|
||||||
|
for block_string in string_list:
|
||||||
|
blocks_args.append(BlockDecoder._decode_block_string(block_string))
|
||||||
|
return blocks_args
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def encode(blocks_args):
|
||||||
|
"""
|
||||||
|
Encodes a list of BlockArgs to a list of strings.
|
||||||
|
|
||||||
|
:param blocks_args: a list of BlockArgs namedtuples of block args
|
||||||
|
:return: a list of strings, each string is a notation of block
|
||||||
|
"""
|
||||||
|
block_strings = []
|
||||||
|
for block in blocks_args:
|
||||||
|
block_strings.append(BlockDecoder._encode_block_string(block))
|
||||||
|
return block_strings
|
||||||
|
|
||||||
|
|
||||||
|
def efficientnet(width_coefficient=None, depth_coefficient=None, dropout_rate=0.2,
|
||||||
|
drop_connect_rate=0.2, image_size=None, num_classes=1000):
|
||||||
|
""" Creates a efficientnet model. """
|
||||||
|
|
||||||
|
blocks_args = [
|
||||||
|
'r1_k3_s11_e1_i32_o16_se0.25', 'r2_k3_s22_e6_i16_o24_se0.25',
|
||||||
|
'r2_k5_s22_e6_i24_o40_se0.25', 'r3_k3_s22_e6_i40_o80_se0.25',
|
||||||
|
'r3_k5_s11_e6_i80_o112_se0.25', 'r4_k5_s22_e6_i112_o192_se0.25',
|
||||||
|
'r1_k3_s11_e6_i192_o320_se0.25',
|
||||||
|
]
|
||||||
|
blocks_args = BlockDecoder.decode(blocks_args)
|
||||||
|
|
||||||
|
global_params = GlobalParams(
|
||||||
|
batch_norm_momentum=0.99,
|
||||||
|
batch_norm_epsilon=1e-3,
|
||||||
|
dropout_rate=dropout_rate,
|
||||||
|
drop_connect_rate=drop_connect_rate,
|
||||||
|
# data_format='channels_last', # removed, this is always true in PyTorch
|
||||||
|
num_classes=num_classes,
|
||||||
|
width_coefficient=width_coefficient,
|
||||||
|
depth_coefficient=depth_coefficient,
|
||||||
|
depth_divisor=8,
|
||||||
|
min_depth=None,
|
||||||
|
image_size=image_size,
|
||||||
|
)
|
||||||
|
|
||||||
|
return blocks_args, global_params
|
||||||
|
|
||||||
|
|
||||||
|
def get_model_params(model_name, override_params):
|
||||||
|
""" Get the block args and global params for a given model """
|
||||||
|
if model_name.startswith('efficientnet'):
|
||||||
|
w, d, s, p = efficientnet_params(model_name)
|
||||||
|
# note: all models have drop connect rate = 0.2
|
||||||
|
blocks_args, global_params = efficientnet(
|
||||||
|
width_coefficient=w, depth_coefficient=d, dropout_rate=p, image_size=s)
|
||||||
|
else:
|
||||||
|
raise NotImplementedError('model name is not pre-defined: %s' % model_name)
|
||||||
|
if override_params:
|
||||||
|
# ValueError will be raised here if override_params has fields not included in global_params.
|
||||||
|
global_params = global_params._replace(**override_params)
|
||||||
|
return blocks_args, global_params
|
||||||
|
|
||||||
|
|
||||||
|
url_map = {
|
||||||
|
'efficientnet-b0': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b0-355c32eb.pth',
|
||||||
|
'efficientnet-b1': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b1-f1951068.pth',
|
||||||
|
'efficientnet-b2': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b2-8bb594d6.pth',
|
||||||
|
'efficientnet-b3': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b3-5fb5a3c3.pth',
|
||||||
|
'efficientnet-b4': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b4-6ed6700e.pth',
|
||||||
|
'efficientnet-b5': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b5-b6417697.pth',
|
||||||
|
'efficientnet-b6': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b6-c76e70fd.pth',
|
||||||
|
'efficientnet-b7': 'https://publicmodels.blob.core.windows.net/container/aa/efficientnet-b7-dcc49843.pth',
|
||||||
|
}
|
||||||
|
|
||||||
|
url_map_advprop = {
|
||||||
|
'efficientnet-b0': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b0-b64d5a18.pth',
|
||||||
|
'efficientnet-b1': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b1-0f3ce85a.pth',
|
||||||
|
'efficientnet-b2': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b2-6e9d97e5.pth',
|
||||||
|
'efficientnet-b3': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b3-cdd7c0f4.pth',
|
||||||
|
'efficientnet-b4': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b4-44fb3a87.pth',
|
||||||
|
'efficientnet-b5': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b5-86493f6b.pth',
|
||||||
|
'efficientnet-b6': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b6-ac80338e.pth',
|
||||||
|
'efficientnet-b7': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b7-4652b6dd.pth',
|
||||||
|
'efficientnet-b8': 'https://publicmodels.blob.core.windows.net/container/advprop/efficientnet-b8-22a8fe65.pth',
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def load_pretrained_weights(model, model_name, load_fc=True, advprop=False):
|
||||||
|
""" Loads pretrained weights, and downloads if loading for the first time. """
|
||||||
|
# AutoAugment or Advprop (different preprocessing)
|
||||||
|
url_map_ = url_map_advprop if advprop else url_map
|
||||||
|
state_dict = model_zoo.load_url(url_map_[model_name], map_location=torch.device('cpu'))
|
||||||
|
# state_dict = torch.load('../../weights/backbone_efficientnetb0.pth')
|
||||||
|
if load_fc:
|
||||||
|
ret = model.load_state_dict(state_dict, strict=False)
|
||||||
|
print(ret)
|
||||||
|
else:
|
||||||
|
state_dict.pop('_fc.weight')
|
||||||
|
state_dict.pop('_fc.bias')
|
||||||
|
res = model.load_state_dict(state_dict, strict=False)
|
||||||
|
assert set(res.missing_keys) == set(['_fc.weight', '_fc.bias']), 'issue loading pretrained weights'
|
||||||
|
print('Loaded pretrained weights for {}'.format(model_name))
|
||||||
|
|
@ -0,0 +1,86 @@
|
||||||
|
# Author: Zylo117
|
||||||
|
|
||||||
|
import math
|
||||||
|
|
||||||
|
from torch import nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
|
||||||
|
class Conv2dStaticSamePadding(nn.Module):
|
||||||
|
"""
|
||||||
|
created by Zylo117
|
||||||
|
The real keras/tensorflow conv2d with same padding
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels, kernel_size, stride=1, bias=True, groups=1, dilation=1, **kwargs):
|
||||||
|
super().__init__()
|
||||||
|
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride,
|
||||||
|
bias=bias, groups=groups)
|
||||||
|
self.stride = self.conv.stride
|
||||||
|
self.kernel_size = self.conv.kernel_size
|
||||||
|
self.dilation = self.conv.dilation
|
||||||
|
|
||||||
|
if isinstance(self.stride, int):
|
||||||
|
self.stride = [self.stride] * 2
|
||||||
|
elif len(self.stride) == 1:
|
||||||
|
self.stride = [self.stride[0]] * 2
|
||||||
|
|
||||||
|
if isinstance(self.kernel_size, int):
|
||||||
|
self.kernel_size = [self.kernel_size] * 2
|
||||||
|
elif len(self.kernel_size) == 1:
|
||||||
|
self.kernel_size = [self.kernel_size[0]] * 2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
h, w = x.shape[-2:]
|
||||||
|
|
||||||
|
extra_h = (math.ceil(w / self.stride[1]) - 1) * self.stride[1] - w + self.kernel_size[1]
|
||||||
|
extra_v = (math.ceil(h / self.stride[0]) - 1) * self.stride[0] - h + self.kernel_size[0]
|
||||||
|
|
||||||
|
left = extra_h // 2
|
||||||
|
right = extra_h - left
|
||||||
|
top = extra_v // 2
|
||||||
|
bottom = extra_v - top
|
||||||
|
|
||||||
|
x = F.pad(x, [left, right, top, bottom])
|
||||||
|
|
||||||
|
x = self.conv(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class MaxPool2dStaticSamePadding(nn.Module):
|
||||||
|
"""
|
||||||
|
created by Zylo117
|
||||||
|
The real keras/tensorflow MaxPool2d with same padding
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
super().__init__()
|
||||||
|
self.pool = nn.MaxPool2d(*args, **kwargs)
|
||||||
|
self.stride = self.pool.stride
|
||||||
|
self.kernel_size = self.pool.kernel_size
|
||||||
|
|
||||||
|
if isinstance(self.stride, int):
|
||||||
|
self.stride = [self.stride] * 2
|
||||||
|
elif len(self.stride) == 1:
|
||||||
|
self.stride = [self.stride[0]] * 2
|
||||||
|
|
||||||
|
if isinstance(self.kernel_size, int):
|
||||||
|
self.kernel_size = [self.kernel_size] * 2
|
||||||
|
elif len(self.kernel_size) == 1:
|
||||||
|
self.kernel_size = [self.kernel_size[0]] * 2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
h, w = x.shape[-2:]
|
||||||
|
|
||||||
|
extra_h = (math.ceil(w / self.stride[1]) - 1) * self.stride[1] - w + self.kernel_size[1]
|
||||||
|
extra_v = (math.ceil(h / self.stride[0]) - 1) * self.stride[0] - h + self.kernel_size[0]
|
||||||
|
|
||||||
|
left = extra_h // 2
|
||||||
|
right = extra_h - left
|
||||||
|
top = extra_v // 2
|
||||||
|
bottom = extra_v - top
|
||||||
|
|
||||||
|
x = F.pad(x, [left, right, top, bottom])
|
||||||
|
|
||||||
|
x = self.pool(x)
|
||||||
|
return x
|
||||||
148
detection/models/detection/efficientdet/loss.py
Normal file
148
detection/models/detection/efficientdet/loss.py
Normal file
|
|
@ -0,0 +1,148 @@
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from .utils import BBoxTransform, ClipBoxes
|
||||||
|
from .process import postprocess, invert_affine, display
|
||||||
|
|
||||||
|
|
||||||
|
def calc_iou(a, b):
|
||||||
|
# a(anchor) [boxes, (y1, x1, y2, x2)]
|
||||||
|
# b(gt, coco-style) [boxes, (x1, y1, x2, y2)]
|
||||||
|
|
||||||
|
area = (b[:, 2] - b[:, 0]) * (b[:, 3] - b[:, 1])
|
||||||
|
iw = torch.min(torch.unsqueeze(a[:, 3], dim=1), b[:, 2]) - torch.max(torch.unsqueeze(a[:, 1], 1), b[:, 0])
|
||||||
|
ih = torch.min(torch.unsqueeze(a[:, 2], dim=1), b[:, 3]) - torch.max(torch.unsqueeze(a[:, 0], 1), b[:, 1])
|
||||||
|
iw = torch.clamp(iw, min=0)
|
||||||
|
ih = torch.clamp(ih, min=0)
|
||||||
|
ua = torch.unsqueeze((a[:, 2] - a[:, 0]) * (a[:, 3] - a[:, 1]), dim=1) + area - iw * ih
|
||||||
|
ua = torch.clamp(ua, min=1e-8)
|
||||||
|
intersection = iw * ih
|
||||||
|
IoU = intersection / ua
|
||||||
|
|
||||||
|
return IoU
|
||||||
|
|
||||||
|
|
||||||
|
class FocalLoss(nn.Module):
|
||||||
|
def __init__(self):
|
||||||
|
super(FocalLoss, self).__init__()
|
||||||
|
|
||||||
|
def forward(self, classifications, regressions, anchors, annotations, **kwargs):
|
||||||
|
alpha = 0.25
|
||||||
|
gamma = 2.0
|
||||||
|
batch_size = classifications.shape[0]
|
||||||
|
device = classifications.device
|
||||||
|
annotations = annotations.to(device)
|
||||||
|
anchors = anchors.to(device)
|
||||||
|
classification_losses = []
|
||||||
|
regression_losses = []
|
||||||
|
|
||||||
|
anchor = anchors[0, :, :] # assuming all image sizes are the same, which it is
|
||||||
|
dtype = anchors.dtype
|
||||||
|
|
||||||
|
anchor_widths = anchor[:, 3] - anchor[:, 1]
|
||||||
|
anchor_heights = anchor[:, 2] - anchor[:, 0]
|
||||||
|
anchor_ctr_x = anchor[:, 1] + 0.5 * anchor_widths
|
||||||
|
anchor_ctr_y = anchor[:, 0] + 0.5 * anchor_heights
|
||||||
|
|
||||||
|
for j in range(batch_size):
|
||||||
|
|
||||||
|
classification = classifications[j, :, :]
|
||||||
|
regression = regressions[j, :, :]
|
||||||
|
|
||||||
|
bbox_annotation = annotations[j]
|
||||||
|
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
|
||||||
|
|
||||||
|
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
|
||||||
|
|
||||||
|
if bbox_annotation.shape[0] == 0:
|
||||||
|
alpha_factor = torch.ones_like(classification) * alpha
|
||||||
|
alpha_factor = alpha_factor.to(device)
|
||||||
|
alpha_factor = 1. - alpha_factor
|
||||||
|
focal_weight = classification
|
||||||
|
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
|
||||||
|
|
||||||
|
bce = -(torch.log(1.0 - classification))
|
||||||
|
|
||||||
|
cls_loss = focal_weight * bce
|
||||||
|
|
||||||
|
regression_losses.append(torch.tensor(0).to(dtype).to(device))
|
||||||
|
classification_losses.append(cls_loss.sum())
|
||||||
|
|
||||||
|
continue
|
||||||
|
|
||||||
|
IoU = calc_iou(anchor[:, :], bbox_annotation[:, :4])
|
||||||
|
|
||||||
|
IoU_max, IoU_argmax = torch.max(IoU, dim=1)
|
||||||
|
|
||||||
|
# compute the loss for classification
|
||||||
|
targets = torch.ones_like(classification) * -1
|
||||||
|
targets = targets.to(device)
|
||||||
|
|
||||||
|
targets[torch.lt(IoU_max, 0.4), :] = 0
|
||||||
|
|
||||||
|
positive_indices = torch.ge(IoU_max, 0.5)
|
||||||
|
|
||||||
|
num_positive_anchors = positive_indices.sum()
|
||||||
|
|
||||||
|
assigned_annotations = bbox_annotation[IoU_argmax, :]
|
||||||
|
|
||||||
|
targets[positive_indices, :] = 0
|
||||||
|
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
|
||||||
|
|
||||||
|
alpha_factor = torch.ones_like(targets) * alpha
|
||||||
|
alpha_factor = alpha_factor.to(device)
|
||||||
|
|
||||||
|
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
|
||||||
|
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
|
||||||
|
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
|
||||||
|
|
||||||
|
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
|
||||||
|
|
||||||
|
cls_loss = focal_weight * bce
|
||||||
|
|
||||||
|
zeros = torch.zeros_like(cls_loss)
|
||||||
|
zeros = zeros.to(device)
|
||||||
|
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, zeros)
|
||||||
|
|
||||||
|
classification_losses.append(cls_loss.sum() / torch.clamp(num_positive_anchors.to(dtype), min=1.0))
|
||||||
|
|
||||||
|
if positive_indices.sum() > 0:
|
||||||
|
assigned_annotations = assigned_annotations[positive_indices, :]
|
||||||
|
|
||||||
|
anchor_widths_pi = anchor_widths[positive_indices]
|
||||||
|
anchor_heights_pi = anchor_heights[positive_indices]
|
||||||
|
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
|
||||||
|
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
|
||||||
|
|
||||||
|
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
|
||||||
|
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
|
||||||
|
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
|
||||||
|
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
|
||||||
|
|
||||||
|
# efficientdet style
|
||||||
|
gt_widths = torch.clamp(gt_widths, min=1)
|
||||||
|
gt_heights = torch.clamp(gt_heights, min=1)
|
||||||
|
|
||||||
|
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
|
||||||
|
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
|
||||||
|
targets_dw = torch.log(gt_widths / anchor_widths_pi)
|
||||||
|
targets_dh = torch.log(gt_heights / anchor_heights_pi)
|
||||||
|
|
||||||
|
targets = torch.stack((targets_dy, targets_dx, targets_dh, targets_dw))
|
||||||
|
targets = targets.t()
|
||||||
|
|
||||||
|
regression_diff = torch.abs(targets - regression[positive_indices, :])
|
||||||
|
|
||||||
|
regression_loss = torch.where(
|
||||||
|
torch.le(regression_diff, 1.0 / 9.0),
|
||||||
|
0.5 * 9.0 * torch.pow(regression_diff, 2),
|
||||||
|
regression_diff - 0.5 / 9.0
|
||||||
|
)
|
||||||
|
regression_losses.append(regression_loss.mean())
|
||||||
|
else:
|
||||||
|
regression_losses.append(torch.tensor(0).to(dtype).to(device))
|
||||||
|
|
||||||
|
return torch.stack(classification_losses).mean(dim=0, keepdim=True), \
|
||||||
|
torch.stack(regression_losses).mean(dim=0, keepdim=True) * 50 # https://github.com/google/automl/blob/6fdd1de778408625c1faf368a327fe36ecd41bf7/efficientdet/hparams_config.py#L233
|
||||||
465
detection/models/detection/efficientdet/model.py
Normal file
465
detection/models/detection/efficientdet/model.py
Normal file
|
|
@ -0,0 +1,465 @@
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch
|
||||||
|
from torchvision.ops.boxes import nms as nms_torch
|
||||||
|
|
||||||
|
from .efficientnet import EfficientNet as EffNet
|
||||||
|
from .efficientnet.utils import MemoryEfficientSwish, Swish
|
||||||
|
from .efficientnet.utils_extra import Conv2dStaticSamePadding, MaxPool2dStaticSamePadding
|
||||||
|
|
||||||
|
|
||||||
|
def nms(dets, thresh):
|
||||||
|
return nms_torch(dets[:, :4], dets[:, 4], thresh)
|
||||||
|
|
||||||
|
|
||||||
|
class SeparableConvBlock(nn.Module):
|
||||||
|
"""
|
||||||
|
created by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels=None, norm=True, activation=False, onnx_export=False):
|
||||||
|
super(SeparableConvBlock, self).__init__()
|
||||||
|
if out_channels is None:
|
||||||
|
out_channels = in_channels
|
||||||
|
|
||||||
|
# Q: whether separate conv
|
||||||
|
# share bias between depthwise_conv and pointwise_conv
|
||||||
|
# or just pointwise_conv apply bias.
|
||||||
|
# A: Confirmed, just pointwise_conv applies bias, depthwise_conv has no bias.
|
||||||
|
|
||||||
|
self.depthwise_conv = Conv2dStaticSamePadding(in_channels, in_channels,
|
||||||
|
kernel_size=3, stride=1, groups=in_channels, bias=False)
|
||||||
|
self.pointwise_conv = Conv2dStaticSamePadding(in_channels, out_channels, kernel_size=1, stride=1)
|
||||||
|
|
||||||
|
self.norm = norm
|
||||||
|
if self.norm:
|
||||||
|
# Warning: pytorch momentum is different from tensorflow's, momentum_pytorch = 1 - momentum_tensorflow
|
||||||
|
self.bn = nn.BatchNorm2d(num_features=out_channels, momentum=0.01, eps=1e-3)
|
||||||
|
|
||||||
|
self.activation = activation
|
||||||
|
if self.activation:
|
||||||
|
self.swish = MemoryEfficientSwish() if not onnx_export else Swish()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.depthwise_conv(x)
|
||||||
|
x = self.pointwise_conv(x)
|
||||||
|
|
||||||
|
if self.norm:
|
||||||
|
x = self.bn(x)
|
||||||
|
|
||||||
|
if self.activation:
|
||||||
|
x = self.swish(x)
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class BiFPN(nn.Module):
|
||||||
|
"""
|
||||||
|
modified by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, num_channels, conv_channels, first_time=False, epsilon=1e-4, onnx_export=False, attention=True,
|
||||||
|
use_p8=False):
|
||||||
|
"""
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_channels:
|
||||||
|
conv_channels:
|
||||||
|
first_time: whether the input comes directly from the efficientnet,
|
||||||
|
if True, downchannel it first, and downsample P5 to generate P6 then P7
|
||||||
|
epsilon: epsilon of fast weighted attention sum of BiFPN, not the BN's epsilon
|
||||||
|
onnx_export: if True, use Swish instead of MemoryEfficientSwish
|
||||||
|
"""
|
||||||
|
super(BiFPN, self).__init__()
|
||||||
|
self.epsilon = epsilon
|
||||||
|
self.use_p8 = use_p8
|
||||||
|
|
||||||
|
# Conv layers
|
||||||
|
self.conv6_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv5_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv4_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv3_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv4_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv5_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv6_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv7_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
if use_p8:
|
||||||
|
self.conv7_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
self.conv8_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
|
||||||
|
|
||||||
|
# Feature scaling layers
|
||||||
|
self.p6_upsample = nn.Upsample(scale_factor=2, mode='nearest')
|
||||||
|
self.p5_upsample = nn.Upsample(scale_factor=2, mode='nearest')
|
||||||
|
self.p4_upsample = nn.Upsample(scale_factor=2, mode='nearest')
|
||||||
|
self.p3_upsample = nn.Upsample(scale_factor=2, mode='nearest')
|
||||||
|
|
||||||
|
self.p4_downsample = MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
self.p5_downsample = MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
self.p6_downsample = MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
self.p7_downsample = MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
if use_p8:
|
||||||
|
self.p7_upsample = nn.Upsample(scale_factor=2, mode='nearest')
|
||||||
|
self.p8_downsample = MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
|
||||||
|
self.swish = MemoryEfficientSwish() if not onnx_export else Swish()
|
||||||
|
|
||||||
|
self.first_time = first_time
|
||||||
|
if self.first_time:
|
||||||
|
self.p5_down_channel = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
)
|
||||||
|
self.p4_down_channel = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[1], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
)
|
||||||
|
self.p3_down_channel = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[0], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.p5_to_p6 = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
)
|
||||||
|
self.p6_to_p7 = nn.Sequential(
|
||||||
|
MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
)
|
||||||
|
if use_p8:
|
||||||
|
self.p7_to_p8 = nn.Sequential(
|
||||||
|
MaxPool2dStaticSamePadding(3, 2)
|
||||||
|
)
|
||||||
|
|
||||||
|
self.p4_down_channel_2 = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[1], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
)
|
||||||
|
self.p5_down_channel_2 = nn.Sequential(
|
||||||
|
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
|
||||||
|
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Weight
|
||||||
|
self.p6_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p6_w1_relu = nn.ReLU()
|
||||||
|
self.p5_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p5_w1_relu = nn.ReLU()
|
||||||
|
self.p4_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p4_w1_relu = nn.ReLU()
|
||||||
|
self.p3_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p3_w1_relu = nn.ReLU()
|
||||||
|
|
||||||
|
self.p4_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p4_w2_relu = nn.ReLU()
|
||||||
|
self.p5_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p5_w2_relu = nn.ReLU()
|
||||||
|
self.p6_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p6_w2_relu = nn.ReLU()
|
||||||
|
self.p7_w2 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
|
||||||
|
self.p7_w2_relu = nn.ReLU()
|
||||||
|
|
||||||
|
self.attention = attention
|
||||||
|
|
||||||
|
def forward(self, inputs):
|
||||||
|
"""
|
||||||
|
illustration of a minimal bifpn unit
|
||||||
|
P7_0 -------------------------> P7_2 -------->
|
||||||
|
|-------------| ↑
|
||||||
|
↓ |
|
||||||
|
P6_0 ---------> P6_1 ---------> P6_2 -------->
|
||||||
|
|-------------|--------------↑ ↑
|
||||||
|
↓ |
|
||||||
|
P5_0 ---------> P5_1 ---------> P5_2 -------->
|
||||||
|
|-------------|--------------↑ ↑
|
||||||
|
↓ |
|
||||||
|
P4_0 ---------> P4_1 ---------> P4_2 -------->
|
||||||
|
|-------------|--------------↑ ↑
|
||||||
|
|--------------↓ |
|
||||||
|
P3_0 -------------------------> P3_2 -------->
|
||||||
|
"""
|
||||||
|
|
||||||
|
# downsample channels using same-padding conv2d to target phase's if not the same
|
||||||
|
# judge: same phase as target,
|
||||||
|
# if same, pass;
|
||||||
|
# elif earlier phase, downsample to target phase's by pooling
|
||||||
|
# elif later phase, upsample to target phase's by nearest interpolation
|
||||||
|
|
||||||
|
if self.attention:
|
||||||
|
outs = self._forward_fast_attention(inputs)
|
||||||
|
else:
|
||||||
|
outs = self._forward(inputs)
|
||||||
|
|
||||||
|
return outs
|
||||||
|
|
||||||
|
def _forward_fast_attention(self, inputs):
|
||||||
|
if self.first_time:
|
||||||
|
p3, p4, p5 = inputs
|
||||||
|
|
||||||
|
p6_in = self.p5_to_p6(p5)
|
||||||
|
p7_in = self.p6_to_p7(p6_in)
|
||||||
|
|
||||||
|
p3_in = self.p3_down_channel(p3)
|
||||||
|
p4_in = self.p4_down_channel(p4)
|
||||||
|
p5_in = self.p5_down_channel(p5)
|
||||||
|
|
||||||
|
else:
|
||||||
|
# P3_0, P4_0, P5_0, P6_0 and P7_0
|
||||||
|
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
|
||||||
|
|
||||||
|
# P7_0 to P7_2
|
||||||
|
|
||||||
|
# Weights for P6_0 and P7_0 to P6_1
|
||||||
|
p6_w1 = self.p6_w1_relu(self.p6_w1)
|
||||||
|
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
|
||||||
|
# Connections for P6_0 and P7_0 to P6_1 respectively
|
||||||
|
p6_up = self.conv6_up(self.swish(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in)))
|
||||||
|
|
||||||
|
# Weights for P5_0 and P6_1 to P5_1
|
||||||
|
p5_w1 = self.p5_w1_relu(self.p5_w1)
|
||||||
|
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
|
||||||
|
# Connections for P5_0 and P6_1 to P5_1 respectively
|
||||||
|
p5_up = self.conv5_up(self.swish(weight[0] * p5_in + weight[1] * self.p5_upsample(p6_up)))
|
||||||
|
|
||||||
|
# Weights for P4_0 and P5_1 to P4_1
|
||||||
|
p4_w1 = self.p4_w1_relu(self.p4_w1)
|
||||||
|
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
|
||||||
|
# Connections for P4_0 and P5_1 to P4_1 respectively
|
||||||
|
p4_up = self.conv4_up(self.swish(weight[0] * p4_in + weight[1] * self.p4_upsample(p5_up)))
|
||||||
|
|
||||||
|
# Weights for P3_0 and P4_1 to P3_2
|
||||||
|
p3_w1 = self.p3_w1_relu(self.p3_w1)
|
||||||
|
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
|
||||||
|
# Connections for P3_0 and P4_1 to P3_2 respectively
|
||||||
|
p3_out = self.conv3_up(self.swish(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up)))
|
||||||
|
|
||||||
|
if self.first_time:
|
||||||
|
p4_in = self.p4_down_channel_2(p4)
|
||||||
|
p5_in = self.p5_down_channel_2(p5)
|
||||||
|
|
||||||
|
# Weights for P4_0, P4_1 and P3_2 to P4_2
|
||||||
|
p4_w2 = self.p4_w2_relu(self.p4_w2)
|
||||||
|
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
|
||||||
|
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
|
||||||
|
p4_out = self.conv4_down(
|
||||||
|
self.swish(weight[0] * p4_in + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out)))
|
||||||
|
|
||||||
|
# Weights for P5_0, P5_1 and P4_2 to P5_2
|
||||||
|
p5_w2 = self.p5_w2_relu(self.p5_w2)
|
||||||
|
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
|
||||||
|
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
|
||||||
|
p5_out = self.conv5_down(
|
||||||
|
self.swish(weight[0] * p5_in + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out)))
|
||||||
|
|
||||||
|
# Weights for P6_0, P6_1 and P5_2 to P6_2
|
||||||
|
p6_w2 = self.p6_w2_relu(self.p6_w2)
|
||||||
|
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
|
||||||
|
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
|
||||||
|
p6_out = self.conv6_down(
|
||||||
|
self.swish(weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out)))
|
||||||
|
|
||||||
|
# Weights for P7_0 and P6_2 to P7_2
|
||||||
|
p7_w2 = self.p7_w2_relu(self.p7_w2)
|
||||||
|
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
|
||||||
|
# Connections for P7_0 and P6_2 to P7_2
|
||||||
|
p7_out = self.conv7_down(self.swish(weight[0] * p7_in + weight[1] * self.p7_downsample(p6_out)))
|
||||||
|
|
||||||
|
return p3_out, p4_out, p5_out, p6_out, p7_out
|
||||||
|
|
||||||
|
def _forward(self, inputs):
|
||||||
|
if self.first_time:
|
||||||
|
p3, p4, p5 = inputs
|
||||||
|
|
||||||
|
p6_in = self.p5_to_p6(p5)
|
||||||
|
p7_in = self.p6_to_p7(p6_in)
|
||||||
|
if self.use_p8:
|
||||||
|
p8_in = self.p7_to_p8(p7_in)
|
||||||
|
|
||||||
|
p3_in = self.p3_down_channel(p3)
|
||||||
|
p4_in = self.p4_down_channel(p4)
|
||||||
|
p5_in = self.p5_down_channel(p5)
|
||||||
|
|
||||||
|
else:
|
||||||
|
if self.use_p8:
|
||||||
|
# P3_0, P4_0, P5_0, P6_0, P7_0 and P8_0
|
||||||
|
p3_in, p4_in, p5_in, p6_in, p7_in, p8_in = inputs
|
||||||
|
else:
|
||||||
|
# P3_0, P4_0, P5_0, P6_0 and P7_0
|
||||||
|
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
|
||||||
|
|
||||||
|
if self.use_p8:
|
||||||
|
# P8_0 to P8_2
|
||||||
|
|
||||||
|
# Connections for P7_0 and P8_0 to P7_1 respectively
|
||||||
|
p7_up = self.conv7_up(self.swish(p7_in + self.p7_upsample(p8_in)))
|
||||||
|
|
||||||
|
# Connections for P6_0 and P7_0 to P6_1 respectively
|
||||||
|
p6_up = self.conv6_up(self.swish(p6_in + self.p6_upsample(p7_up)))
|
||||||
|
else:
|
||||||
|
# P7_0 to P7_2
|
||||||
|
|
||||||
|
# Connections for P6_0 and P7_0 to P6_1 respectively
|
||||||
|
p6_up = self.conv6_up(self.swish(p6_in + self.p6_upsample(p7_in)))
|
||||||
|
|
||||||
|
# Connections for P5_0 and P6_1 to P5_1 respectively
|
||||||
|
p5_up = self.conv5_up(self.swish(p5_in + self.p5_upsample(p6_up)))
|
||||||
|
|
||||||
|
# Connections for P4_0 and P5_1 to P4_1 respectively
|
||||||
|
p4_up = self.conv4_up(self.swish(p4_in + self.p4_upsample(p5_up)))
|
||||||
|
|
||||||
|
# Connections for P3_0 and P4_1 to P3_2 respectively
|
||||||
|
p3_out = self.conv3_up(self.swish(p3_in + self.p3_upsample(p4_up)))
|
||||||
|
|
||||||
|
if self.first_time:
|
||||||
|
p4_in = self.p4_down_channel_2(p4)
|
||||||
|
p5_in = self.p5_down_channel_2(p5)
|
||||||
|
|
||||||
|
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
|
||||||
|
p4_out = self.conv4_down(
|
||||||
|
self.swish(p4_in + p4_up + self.p4_downsample(p3_out)))
|
||||||
|
|
||||||
|
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
|
||||||
|
p5_out = self.conv5_down(
|
||||||
|
self.swish(p5_in + p5_up + self.p5_downsample(p4_out)))
|
||||||
|
|
||||||
|
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
|
||||||
|
p6_out = self.conv6_down(
|
||||||
|
self.swish(p6_in + p6_up + self.p6_downsample(p5_out)))
|
||||||
|
|
||||||
|
if self.use_p8:
|
||||||
|
# Connections for P7_0, P7_1 and P6_2 to P7_2 respectively
|
||||||
|
p7_out = self.conv7_down(
|
||||||
|
self.swish(p7_in + p7_up + self.p7_downsample(p6_out)))
|
||||||
|
|
||||||
|
# Connections for P8_0 and P7_2 to P8_2
|
||||||
|
p8_out = self.conv8_down(self.swish(p8_in + self.p8_downsample(p7_out)))
|
||||||
|
|
||||||
|
return p3_out, p4_out, p5_out, p6_out, p7_out, p8_out
|
||||||
|
else:
|
||||||
|
# Connections for P7_0 and P6_2 to P7_2
|
||||||
|
p7_out = self.conv7_down(self.swish(p7_in + self.p7_downsample(p6_out)))
|
||||||
|
|
||||||
|
return p3_out, p4_out, p5_out, p6_out, p7_out
|
||||||
|
|
||||||
|
|
||||||
|
class Regressor(nn.Module):
|
||||||
|
"""
|
||||||
|
modified by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels, num_anchors, num_layers, pyramid_levels=5, onnx_export=False):
|
||||||
|
super(Regressor, self).__init__()
|
||||||
|
self.num_layers = num_layers
|
||||||
|
|
||||||
|
self.conv_list = nn.ModuleList(
|
||||||
|
[SeparableConvBlock(in_channels, in_channels, norm=False, activation=False) for i in range(num_layers)])
|
||||||
|
self.bn_list = nn.ModuleList(
|
||||||
|
[nn.ModuleList([nn.BatchNorm2d(in_channels, momentum=0.01, eps=1e-3) for i in range(num_layers)]) for j in
|
||||||
|
range(pyramid_levels)])
|
||||||
|
self.header = SeparableConvBlock(in_channels, num_anchors * 4, norm=False, activation=False)
|
||||||
|
self.swish = MemoryEfficientSwish() if not onnx_export else Swish()
|
||||||
|
|
||||||
|
def forward(self, inputs):
|
||||||
|
feats = []
|
||||||
|
for feat, bn_list in zip(inputs, self.bn_list):
|
||||||
|
for i, bn, conv in zip(range(self.num_layers), bn_list, self.conv_list):
|
||||||
|
feat = conv(feat)
|
||||||
|
feat = bn(feat)
|
||||||
|
feat = self.swish(feat)
|
||||||
|
feat = self.header(feat)
|
||||||
|
|
||||||
|
feat = feat.permute(0, 2, 3, 1)
|
||||||
|
feat = feat.contiguous().view(feat.shape[0], -1, 4)
|
||||||
|
|
||||||
|
feats.append(feat)
|
||||||
|
|
||||||
|
feats = torch.cat(feats, dim=1)
|
||||||
|
|
||||||
|
return feats
|
||||||
|
|
||||||
|
|
||||||
|
class Classifier(nn.Module):
|
||||||
|
"""
|
||||||
|
modified by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels, num_anchors, num_classes, num_layers, pyramid_levels=5, onnx_export=False):
|
||||||
|
super(Classifier, self).__init__()
|
||||||
|
self.num_anchors = num_anchors
|
||||||
|
self.num_classes = num_classes
|
||||||
|
self.num_layers = num_layers
|
||||||
|
self.conv_list = nn.ModuleList(
|
||||||
|
[SeparableConvBlock(in_channels, in_channels, norm=False, activation=False) for i in range(num_layers)])
|
||||||
|
self.bn_list = nn.ModuleList(
|
||||||
|
[nn.ModuleList([nn.BatchNorm2d(in_channels, momentum=0.01, eps=1e-3) for i in range(num_layers)]) for j in
|
||||||
|
range(pyramid_levels)])
|
||||||
|
self.header = SeparableConvBlock(in_channels, num_anchors * num_classes, norm=False, activation=False)
|
||||||
|
self.swish = MemoryEfficientSwish() if not onnx_export else Swish()
|
||||||
|
|
||||||
|
def forward(self, inputs):
|
||||||
|
feats = []
|
||||||
|
for feat, bn_list in zip(inputs, self.bn_list):
|
||||||
|
for i, bn, conv in zip(range(self.num_layers), bn_list, self.conv_list):
|
||||||
|
feat = conv(feat)
|
||||||
|
feat = bn(feat)
|
||||||
|
feat = self.swish(feat)
|
||||||
|
feat = self.header(feat)
|
||||||
|
|
||||||
|
feat = feat.permute(0, 2, 3, 1)
|
||||||
|
feat = feat.contiguous().view(feat.shape[0], feat.shape[1], feat.shape[2], self.num_anchors,
|
||||||
|
self.num_classes)
|
||||||
|
feat = feat.contiguous().view(feat.shape[0], -1, self.num_classes)
|
||||||
|
|
||||||
|
feats.append(feat)
|
||||||
|
|
||||||
|
feats = torch.cat(feats, dim=1)
|
||||||
|
feats = feats.sigmoid()
|
||||||
|
|
||||||
|
return feats
|
||||||
|
|
||||||
|
|
||||||
|
class EfficientNet(nn.Module):
|
||||||
|
"""
|
||||||
|
modified by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, compound_coef, load_weights=False):
|
||||||
|
super(EfficientNet, self).__init__()
|
||||||
|
model = EffNet.from_pretrained(f'efficientnet-b{compound_coef}', load_weights)
|
||||||
|
del model._conv_head
|
||||||
|
del model._bn1
|
||||||
|
del model._avg_pooling
|
||||||
|
del model._dropout
|
||||||
|
del model._fc
|
||||||
|
self.model = model
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.model._conv_stem(x)
|
||||||
|
x = self.model._bn0(x)
|
||||||
|
x = self.model._swish(x)
|
||||||
|
feature_maps = []
|
||||||
|
|
||||||
|
# TODO: temporarily storing extra tensor last_x and del it later might not be a good idea,
|
||||||
|
# try recording stride changing when creating efficientnet,
|
||||||
|
# and then apply it here.
|
||||||
|
last_x = None
|
||||||
|
for idx, block in enumerate(self.model._blocks):
|
||||||
|
drop_connect_rate = self.model._global_params.drop_connect_rate
|
||||||
|
if drop_connect_rate:
|
||||||
|
drop_connect_rate *= float(idx) / len(self.model._blocks)
|
||||||
|
x = block(x, drop_connect_rate=drop_connect_rate)
|
||||||
|
|
||||||
|
if block._depthwise_conv.stride == [2, 2]:
|
||||||
|
feature_maps.append(last_x)
|
||||||
|
elif idx == len(self.model._blocks) - 1:
|
||||||
|
feature_maps.append(x)
|
||||||
|
last_x = x
|
||||||
|
del last_x
|
||||||
|
return feature_maps[1:]
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
from tensorboardX import SummaryWriter
|
||||||
|
|
||||||
|
|
||||||
|
def count_parameters(model):
|
||||||
|
return sum(p.numel() for p in model.parameters() if p.requires_grad)
|
||||||
314
detection/models/detection/efficientdet/process.py
Normal file
314
detection/models/detection/efficientdet/process.py
Normal file
|
|
@ -0,0 +1,314 @@
|
||||||
|
# Author: Zylo117
|
||||||
|
|
||||||
|
import math
|
||||||
|
import os
|
||||||
|
import uuid
|
||||||
|
from glob import glob
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
#import webcolors
|
||||||
|
from torch import nn
|
||||||
|
from torch.nn.init import _calculate_fan_in_and_fan_out, _no_grad_normal_
|
||||||
|
from torchvision.ops.boxes import batched_nms
|
||||||
|
|
||||||
|
from .sync_batchnorm import SynchronizedBatchNorm2d
|
||||||
|
|
||||||
|
|
||||||
|
def invert_affine(metas: Union[float, list, tuple], preds):
|
||||||
|
for i in range(len(preds)):
|
||||||
|
if len(preds[i]['rois']) == 0:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
if metas is float:
|
||||||
|
preds[i]['rois'][:, [0, 2]] = preds[i]['rois'][:, [0, 2]] / metas
|
||||||
|
preds[i]['rois'][:, [1, 3]] = preds[i]['rois'][:, [1, 3]] / metas
|
||||||
|
else:
|
||||||
|
new_w, new_h, old_w, old_h, padding_w, padding_h = metas[i]
|
||||||
|
preds[i]['rois'][:, [0, 2]] = preds[i]['rois'][:, [0, 2]] / (new_w / old_w)
|
||||||
|
preds[i]['rois'][:, [1, 3]] = preds[i]['rois'][:, [1, 3]] / (new_h / old_h)
|
||||||
|
return preds
|
||||||
|
|
||||||
|
|
||||||
|
def aspectaware_resize_padding(image, width, height, interpolation=None, means=None):
|
||||||
|
old_h, old_w, c = image.shape
|
||||||
|
if old_w > old_h:
|
||||||
|
new_w = width
|
||||||
|
new_h = int(width / old_w * old_h)
|
||||||
|
else:
|
||||||
|
new_w = int(height / old_h * old_w)
|
||||||
|
new_h = height
|
||||||
|
|
||||||
|
canvas = np.zeros((height, height, c), np.float32)
|
||||||
|
if means is not None:
|
||||||
|
canvas[...] = means
|
||||||
|
|
||||||
|
if new_w != old_w or new_h != old_h:
|
||||||
|
if interpolation is None:
|
||||||
|
image = cv2.resize(image, (new_w, new_h))
|
||||||
|
else:
|
||||||
|
image = cv2.resize(image, (new_w, new_h), interpolation=interpolation)
|
||||||
|
|
||||||
|
padding_h = height - new_h
|
||||||
|
padding_w = width - new_w
|
||||||
|
|
||||||
|
if c > 1:
|
||||||
|
canvas[:new_h, :new_w] = image
|
||||||
|
else:
|
||||||
|
if len(image.shape) == 2:
|
||||||
|
canvas[:new_h, :new_w, 0] = image
|
||||||
|
else:
|
||||||
|
canvas[:new_h, :new_w] = image
|
||||||
|
|
||||||
|
return canvas, new_w, new_h, old_w, old_h, padding_w, padding_h,
|
||||||
|
|
||||||
|
|
||||||
|
def preprocess(*image_path, max_size=512, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
|
||||||
|
ori_imgs = [cv2.imread(img_path) for img_path in image_path]
|
||||||
|
normalized_imgs = [(img[..., ::-1] / 255 - mean) / std for img in ori_imgs]
|
||||||
|
imgs_meta = [aspectaware_resize_padding(img, max_size, max_size,
|
||||||
|
means=None) for img in normalized_imgs]
|
||||||
|
framed_imgs = [img_meta[0] for img_meta in imgs_meta]
|
||||||
|
framed_metas = [img_meta[1:] for img_meta in imgs_meta]
|
||||||
|
|
||||||
|
return ori_imgs, framed_imgs, framed_metas
|
||||||
|
|
||||||
|
|
||||||
|
def preprocess_video(*frame_from_video, max_size=512, mean=(0.406, 0.456, 0.485), std=(0.225, 0.224, 0.229)):
|
||||||
|
ori_imgs = frame_from_video
|
||||||
|
normalized_imgs = [(img[..., ::-1] / 255 - mean) / std for img in ori_imgs]
|
||||||
|
imgs_meta = [aspectaware_resize_padding(img, max_size, max_size,
|
||||||
|
means=None) for img in normalized_imgs]
|
||||||
|
framed_imgs = [img_meta[0] for img_meta in imgs_meta]
|
||||||
|
framed_metas = [img_meta[1:] for img_meta in imgs_meta]
|
||||||
|
|
||||||
|
return ori_imgs, framed_imgs, framed_metas
|
||||||
|
|
||||||
|
|
||||||
|
def postprocess(x, anchors, regression, classification, regressBoxes, clipBoxes, threshold=0.2, iou_threshold=0.2):
|
||||||
|
transformed_anchors = regressBoxes(anchors, regression)
|
||||||
|
transformed_anchors = clipBoxes(transformed_anchors, x)
|
||||||
|
scores = torch.max(classification, dim=2, keepdim=True)[0]
|
||||||
|
scores_over_thresh = (scores > threshold)[:, :, 0]
|
||||||
|
out = []
|
||||||
|
for i in range(x.shape[0]):
|
||||||
|
if scores_over_thresh[i].sum() == 0:
|
||||||
|
out.append({
|
||||||
|
'rois': np.array(()),
|
||||||
|
'class_ids': np.array(()),
|
||||||
|
'scores': np.array(()),
|
||||||
|
})
|
||||||
|
continue
|
||||||
|
|
||||||
|
classification_per = classification[i, scores_over_thresh[i, :], ...].permute(1, 0)
|
||||||
|
transformed_anchors_per = transformed_anchors[i, scores_over_thresh[i, :], ...]
|
||||||
|
scores_per = scores[i, scores_over_thresh[i, :], ...]
|
||||||
|
scores_, classes_ = classification_per.max(dim=0)
|
||||||
|
anchors_nms_idx = batched_nms(transformed_anchors_per, scores_per[:, 0], classes_, iou_threshold=iou_threshold)
|
||||||
|
|
||||||
|
if anchors_nms_idx.shape[0] != 0:
|
||||||
|
classes_ = classes_[anchors_nms_idx]
|
||||||
|
scores_ = scores_[anchors_nms_idx]
|
||||||
|
boxes_ = transformed_anchors_per[anchors_nms_idx, :]
|
||||||
|
|
||||||
|
out.append({
|
||||||
|
'rois': boxes_.cpu().numpy(),
|
||||||
|
'class_ids': classes_.cpu().numpy(),
|
||||||
|
'scores': scores_.cpu().numpy(),
|
||||||
|
})
|
||||||
|
else:
|
||||||
|
out.append({
|
||||||
|
'rois': np.array(()),
|
||||||
|
'class_ids': np.array(()),
|
||||||
|
'scores': np.array(()),
|
||||||
|
})
|
||||||
|
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
def display(preds, imgs, obj_list, imshow=True, imwrite=False):
|
||||||
|
for i in range(len(imgs)):
|
||||||
|
if len(preds[i]['rois']) == 0:
|
||||||
|
continue
|
||||||
|
|
||||||
|
imgs[i] = imgs[i].copy()
|
||||||
|
|
||||||
|
for j in range(len(preds[i]['rois'])):
|
||||||
|
(x1, y1, x2, y2) = preds[i]['rois'][j].astype(np.int)
|
||||||
|
obj = obj_list[preds[i]['class_ids'][j]]
|
||||||
|
score = float(preds[i]['scores'][j])
|
||||||
|
|
||||||
|
plot_one_box(imgs[i], [x1, y1, x2, y2], label=obj, score=score,
|
||||||
|
color=color_list[get_index_label(obj, obj_list)])
|
||||||
|
if imshow:
|
||||||
|
cv2.imshow('img', imgs[i])
|
||||||
|
cv2.waitKey(0)
|
||||||
|
|
||||||
|
if imwrite:
|
||||||
|
os.makedirs('test/', exist_ok=True)
|
||||||
|
cv2.imwrite(f'test/{uuid.uuid4().hex}.jpg', imgs[i])
|
||||||
|
|
||||||
|
|
||||||
|
def replace_w_sync_bn(m):
|
||||||
|
for var_name in dir(m):
|
||||||
|
target_attr = getattr(m, var_name)
|
||||||
|
if type(target_attr) == torch.nn.BatchNorm2d:
|
||||||
|
num_features = target_attr.num_features
|
||||||
|
eps = target_attr.eps
|
||||||
|
momentum = target_attr.momentum
|
||||||
|
affine = target_attr.affine
|
||||||
|
|
||||||
|
# get parameters
|
||||||
|
running_mean = target_attr.running_mean
|
||||||
|
running_var = target_attr.running_var
|
||||||
|
if affine:
|
||||||
|
weight = target_attr.weight
|
||||||
|
bias = target_attr.bias
|
||||||
|
|
||||||
|
setattr(m, var_name,
|
||||||
|
SynchronizedBatchNorm2d(num_features, eps, momentum, affine))
|
||||||
|
|
||||||
|
target_attr = getattr(m, var_name)
|
||||||
|
# set parameters
|
||||||
|
target_attr.running_mean = running_mean
|
||||||
|
target_attr.running_var = running_var
|
||||||
|
if affine:
|
||||||
|
target_attr.weight = weight
|
||||||
|
target_attr.bias = bias
|
||||||
|
|
||||||
|
for var_name, children in m.named_children():
|
||||||
|
replace_w_sync_bn(children)
|
||||||
|
|
||||||
|
|
||||||
|
class CustomDataParallel(nn.DataParallel):
|
||||||
|
"""
|
||||||
|
force splitting data to all gpus instead of sending all data to cuda:0 and then moving around.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, module, num_gpus):
|
||||||
|
super().__init__(module)
|
||||||
|
self.num_gpus = num_gpus
|
||||||
|
|
||||||
|
def scatter(self, inputs, kwargs, device_ids):
|
||||||
|
# More like scatter and data prep at the same time. The point is we prep the data in such a way
|
||||||
|
# that no scatter is necessary, and there's no need to shuffle stuff around different GPUs.
|
||||||
|
devices = ['cuda:' + str(x) for x in range(self.num_gpus)]
|
||||||
|
splits = inputs[0].shape[0] // self.num_gpus
|
||||||
|
|
||||||
|
if splits == 0:
|
||||||
|
raise Exception('Batchsize must be greater than num_gpus.')
|
||||||
|
|
||||||
|
return [(inputs[0][splits * device_idx: splits * (device_idx + 1)].to(f'cuda:{device_idx}', non_blocking=True),
|
||||||
|
inputs[1][splits * device_idx: splits * (device_idx + 1)].to(f'cuda:{device_idx}', non_blocking=True))
|
||||||
|
for device_idx in range(len(devices))], \
|
||||||
|
[kwargs] * len(devices)
|
||||||
|
|
||||||
|
|
||||||
|
def get_last_weights(weights_path):
|
||||||
|
weights_path = glob(weights_path + f'/*.pth')
|
||||||
|
weights_path = sorted(weights_path,
|
||||||
|
key=lambda x: int(x.rsplit('_')[-1].rsplit('.')[0]),
|
||||||
|
reverse=True)[0]
|
||||||
|
print(f'using weights {weights_path}')
|
||||||
|
return weights_path
|
||||||
|
|
||||||
|
|
||||||
|
def init_weights(model):
|
||||||
|
for name, module in model.named_modules():
|
||||||
|
is_conv_layer = isinstance(module, nn.Conv2d)
|
||||||
|
|
||||||
|
if is_conv_layer:
|
||||||
|
if "conv_list" or "header" in name:
|
||||||
|
variance_scaling_(module.weight.data)
|
||||||
|
else:
|
||||||
|
nn.init.kaiming_uniform_(module.weight.data)
|
||||||
|
|
||||||
|
if module.bias is not None:
|
||||||
|
if "classifier.header" in name:
|
||||||
|
bias_value = -np.log((1 - 0.01) / 0.01)
|
||||||
|
torch.nn.init.constant_(module.bias, bias_value)
|
||||||
|
else:
|
||||||
|
module.bias.data.zero_()
|
||||||
|
|
||||||
|
|
||||||
|
def variance_scaling_(tensor, gain=1.):
|
||||||
|
# type: (Tensor, float) -> Tensor
|
||||||
|
r"""
|
||||||
|
initializer for SeparableConv in Regressor/Classifier
|
||||||
|
reference: https://keras.io/zh/initializers/ VarianceScaling
|
||||||
|
"""
|
||||||
|
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
||||||
|
std = math.sqrt(gain / float(fan_in))
|
||||||
|
|
||||||
|
return _no_grad_normal_(tensor, 0., std)
|
||||||
|
|
||||||
|
|
||||||
|
STANDARD_COLORS = [
|
||||||
|
'LawnGreen', 'Chartreuse', 'Aqua', 'Beige', 'Azure', 'BlanchedAlmond', 'Bisque',
|
||||||
|
'Aquamarine', 'BlueViolet', 'BurlyWood', 'CadetBlue', 'AntiqueWhite',
|
||||||
|
'Chocolate', 'Coral', 'CornflowerBlue', 'Cornsilk', 'Crimson', 'Cyan',
|
||||||
|
'DarkCyan', 'DarkGoldenRod', 'DarkGrey', 'DarkKhaki', 'DarkOrange',
|
||||||
|
'DarkOrchid', 'DarkSalmon', 'DarkSeaGreen', 'DarkTurquoise', 'DarkViolet',
|
||||||
|
'DeepPink', 'DeepSkyBlue', 'DodgerBlue', 'FireBrick', 'FloralWhite',
|
||||||
|
'ForestGreen', 'Fuchsia', 'Gainsboro', 'GhostWhite', 'Gold', 'GoldenRod',
|
||||||
|
'Salmon', 'Tan', 'HoneyDew', 'HotPink', 'IndianRed', 'Ivory', 'Khaki',
|
||||||
|
'Lavender', 'LavenderBlush', 'AliceBlue', 'LemonChiffon', 'LightBlue',
|
||||||
|
'LightCoral', 'LightCyan', 'LightGoldenRodYellow', 'LightGray', 'LightGrey',
|
||||||
|
'LightGreen', 'LightPink', 'LightSalmon', 'LightSeaGreen', 'LightSkyBlue',
|
||||||
|
'LightSlateGray', 'LightSlateGrey', 'LightSteelBlue', 'LightYellow', 'Lime',
|
||||||
|
'LimeGreen', 'Linen', 'Magenta', 'MediumAquaMarine', 'MediumOrchid',
|
||||||
|
'MediumPurple', 'MediumSeaGreen', 'MediumSlateBlue', 'MediumSpringGreen',
|
||||||
|
'MediumTurquoise', 'MediumVioletRed', 'MintCream', 'MistyRose', 'Moccasin',
|
||||||
|
'NavajoWhite', 'OldLace', 'Olive', 'OliveDrab', 'Orange', 'OrangeRed',
|
||||||
|
'Orchid', 'PaleGoldenRod', 'PaleGreen', 'PaleTurquoise', 'PaleVioletRed',
|
||||||
|
'PapayaWhip', 'PeachPuff', 'Peru', 'Pink', 'Plum', 'PowderBlue', 'Purple',
|
||||||
|
'Red', 'RosyBrown', 'RoyalBlue', 'SaddleBrown', 'Green', 'SandyBrown',
|
||||||
|
'SeaGreen', 'SeaShell', 'Sienna', 'Silver', 'SkyBlue', 'SlateBlue',
|
||||||
|
'SlateGray', 'SlateGrey', 'Snow', 'SpringGreen', 'SteelBlue', 'GreenYellow',
|
||||||
|
'Teal', 'Thistle', 'Tomato', 'Turquoise', 'Violet', 'Wheat', 'White',
|
||||||
|
'WhiteSmoke', 'Yellow', 'YellowGreen'
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def from_colorname_to_bgr(color):
|
||||||
|
rgb_color = webcolors.name_to_rgb(color)
|
||||||
|
result = (rgb_color.blue, rgb_color.green, rgb_color.red)
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def standard_to_bgr(list_color_name):
|
||||||
|
standard = []
|
||||||
|
for i in range(len(list_color_name) - 36): # -36 used to match the len(obj_list)
|
||||||
|
standard.append(from_colorname_to_bgr(list_color_name[i]))
|
||||||
|
return standard
|
||||||
|
|
||||||
|
|
||||||
|
def get_index_label(label, obj_list):
|
||||||
|
index = int(obj_list.index(label))
|
||||||
|
return index
|
||||||
|
|
||||||
|
|
||||||
|
def plot_one_box(img, coord, label=None, score=None, color=None, line_thickness=None):
|
||||||
|
tl = line_thickness or int(round(0.001 * max(img.shape[0:2]))) # line thickness
|
||||||
|
color = color
|
||||||
|
c1, c2 = (int(coord[0]), int(coord[1])), (int(coord[2]), int(coord[3]))
|
||||||
|
cv2.rectangle(img, c1, c2, color, thickness=tl)
|
||||||
|
if label:
|
||||||
|
tf = max(tl - 2, 1) # font thickness
|
||||||
|
s_size = cv2.getTextSize(str('{:.0%}'.format(score)), 0, fontScale=float(tl) / 3, thickness=tf)[0]
|
||||||
|
t_size = cv2.getTextSize(label, 0, fontScale=float(tl) / 3, thickness=tf)[0]
|
||||||
|
c2 = c1[0] + t_size[0] + s_size[0] + 15, c1[1] - t_size[1] - 3
|
||||||
|
cv2.rectangle(img, c1, c2, color, -1) # filled
|
||||||
|
cv2.putText(img, '{}: {:.0%}'.format(label, score), (c1[0], c1[1] - 2), 0, float(tl) / 3, [0, 0, 0],
|
||||||
|
thickness=tf, lineType=cv2.FONT_HERSHEY_SIMPLEX)
|
||||||
|
|
||||||
|
|
||||||
|
#color_list = standard_to_bgr(STANDARD_COLORS)
|
||||||
|
|
||||||
|
|
||||||
|
def boolean_string(s):
|
||||||
|
if s not in {'False', 'True'}:
|
||||||
|
raise ValueError('Not a valid boolean string')
|
||||||
|
return s == 'True'
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : __init__.py
|
||||||
|
# Author : Jiayuan Mao
|
||||||
|
# Email : maojiayuan@gmail.com
|
||||||
|
# Date : 27/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
from .batchnorm import SynchronizedBatchNorm1d, SynchronizedBatchNorm2d, SynchronizedBatchNorm3d
|
||||||
|
from .batchnorm import patch_sync_batchnorm, convert_model
|
||||||
|
from .replicate import DataParallelWithCallback, patch_replication_callback
|
||||||
|
|
@ -0,0 +1,394 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : batchnorm.py
|
||||||
|
# Author : Jiayuan Mao
|
||||||
|
# Email : maojiayuan@gmail.com
|
||||||
|
# Date : 27/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
import collections
|
||||||
|
import contextlib
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from torch.nn.modules.batchnorm import _BatchNorm
|
||||||
|
|
||||||
|
try:
|
||||||
|
from torch.nn.parallel._functions import ReduceAddCoalesced, Broadcast
|
||||||
|
except ImportError:
|
||||||
|
ReduceAddCoalesced = Broadcast = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from jactorch.parallel.comm import SyncMaster
|
||||||
|
from jactorch.parallel.data_parallel import JacDataParallel as DataParallelWithCallback
|
||||||
|
except ImportError:
|
||||||
|
from .comm import SyncMaster
|
||||||
|
from .replicate import DataParallelWithCallback
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
'SynchronizedBatchNorm1d', 'SynchronizedBatchNorm2d', 'SynchronizedBatchNorm3d',
|
||||||
|
'patch_sync_batchnorm', 'convert_model'
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def _sum_ft(tensor):
|
||||||
|
"""sum over the first and last dimention"""
|
||||||
|
return tensor.sum(dim=0).sum(dim=-1)
|
||||||
|
|
||||||
|
|
||||||
|
def _unsqueeze_ft(tensor):
|
||||||
|
"""add new dimensions at the front and the tail"""
|
||||||
|
return tensor.unsqueeze(0).unsqueeze(-1)
|
||||||
|
|
||||||
|
|
||||||
|
_ChildMessage = collections.namedtuple('_ChildMessage', ['sum', 'ssum', 'sum_size'])
|
||||||
|
_MasterMessage = collections.namedtuple('_MasterMessage', ['sum', 'inv_std'])
|
||||||
|
|
||||||
|
|
||||||
|
class _SynchronizedBatchNorm(_BatchNorm):
|
||||||
|
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True):
|
||||||
|
assert ReduceAddCoalesced is not None, 'Can not use Synchronized Batch Normalization without CUDA support.'
|
||||||
|
|
||||||
|
super(_SynchronizedBatchNorm, self).__init__(num_features, eps=eps, momentum=momentum, affine=affine)
|
||||||
|
|
||||||
|
self._sync_master = SyncMaster(self._data_parallel_master)
|
||||||
|
|
||||||
|
self._is_parallel = False
|
||||||
|
self._parallel_id = None
|
||||||
|
self._slave_pipe = None
|
||||||
|
|
||||||
|
def forward(self, input):
|
||||||
|
# If it is not parallel computation or is in evaluation mode, use PyTorch's implementation.
|
||||||
|
if not (self._is_parallel and self.training):
|
||||||
|
return F.batch_norm(
|
||||||
|
input, self.running_mean, self.running_var, self.weight, self.bias,
|
||||||
|
self.training, self.momentum, self.eps)
|
||||||
|
|
||||||
|
# Resize the input to (B, C, -1).
|
||||||
|
input_shape = input.size()
|
||||||
|
input = input.view(input.size(0), self.num_features, -1)
|
||||||
|
|
||||||
|
# Compute the sum and square-sum.
|
||||||
|
sum_size = input.size(0) * input.size(2)
|
||||||
|
input_sum = _sum_ft(input)
|
||||||
|
input_ssum = _sum_ft(input ** 2)
|
||||||
|
|
||||||
|
# Reduce-and-broadcast the statistics.
|
||||||
|
if self._parallel_id == 0:
|
||||||
|
mean, inv_std = self._sync_master.run_master(_ChildMessage(input_sum, input_ssum, sum_size))
|
||||||
|
else:
|
||||||
|
mean, inv_std = self._slave_pipe.run_slave(_ChildMessage(input_sum, input_ssum, sum_size))
|
||||||
|
|
||||||
|
# Compute the output.
|
||||||
|
if self.affine:
|
||||||
|
# MJY:: Fuse the multiplication for speed.
|
||||||
|
output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std * self.weight) + _unsqueeze_ft(self.bias)
|
||||||
|
else:
|
||||||
|
output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std)
|
||||||
|
|
||||||
|
# Reshape it.
|
||||||
|
return output.view(input_shape)
|
||||||
|
|
||||||
|
def __data_parallel_replicate__(self, ctx, copy_id):
|
||||||
|
self._is_parallel = True
|
||||||
|
self._parallel_id = copy_id
|
||||||
|
|
||||||
|
# parallel_id == 0 means master device.
|
||||||
|
if self._parallel_id == 0:
|
||||||
|
ctx.sync_master = self._sync_master
|
||||||
|
else:
|
||||||
|
self._slave_pipe = ctx.sync_master.register_slave(copy_id)
|
||||||
|
|
||||||
|
def _data_parallel_master(self, intermediates):
|
||||||
|
"""Reduce the sum and square-sum, compute the statistics, and broadcast it."""
|
||||||
|
|
||||||
|
# Always using same "device order" makes the ReduceAdd operation faster.
|
||||||
|
# Thanks to:: Tete Xiao (http://tetexiao.com/)
|
||||||
|
intermediates = sorted(intermediates, key=lambda i: i[1].sum.get_device())
|
||||||
|
|
||||||
|
to_reduce = [i[1][:2] for i in intermediates]
|
||||||
|
to_reduce = [j for i in to_reduce for j in i] # flatten
|
||||||
|
target_gpus = [i[1].sum.get_device() for i in intermediates]
|
||||||
|
|
||||||
|
sum_size = sum([i[1].sum_size for i in intermediates])
|
||||||
|
sum_, ssum = ReduceAddCoalesced.apply(target_gpus[0], 2, *to_reduce)
|
||||||
|
mean, inv_std = self._compute_mean_std(sum_, ssum, sum_size)
|
||||||
|
|
||||||
|
broadcasted = Broadcast.apply(target_gpus, mean, inv_std)
|
||||||
|
|
||||||
|
outputs = []
|
||||||
|
for i, rec in enumerate(intermediates):
|
||||||
|
outputs.append((rec[0], _MasterMessage(*broadcasted[i*2:i*2+2])))
|
||||||
|
|
||||||
|
return outputs
|
||||||
|
|
||||||
|
def _compute_mean_std(self, sum_, ssum, size):
|
||||||
|
"""Compute the mean and standard-deviation with sum and square-sum. This method
|
||||||
|
also maintains the moving average on the master device."""
|
||||||
|
assert size > 1, 'BatchNorm computes unbiased standard-deviation, which requires size > 1.'
|
||||||
|
mean = sum_ / size
|
||||||
|
sumvar = ssum - sum_ * mean
|
||||||
|
unbias_var = sumvar / (size - 1)
|
||||||
|
bias_var = sumvar / size
|
||||||
|
|
||||||
|
if hasattr(torch, 'no_grad'):
|
||||||
|
with torch.no_grad():
|
||||||
|
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.data
|
||||||
|
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * unbias_var.data
|
||||||
|
else:
|
||||||
|
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.data
|
||||||
|
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * unbias_var.data
|
||||||
|
|
||||||
|
return mean, bias_var.clamp(self.eps) ** -0.5
|
||||||
|
|
||||||
|
|
||||||
|
class SynchronizedBatchNorm1d(_SynchronizedBatchNorm):
|
||||||
|
r"""Applies Synchronized Batch Normalization over a 2d or 3d input that is seen as a
|
||||||
|
mini-batch.
|
||||||
|
|
||||||
|
.. math::
|
||||||
|
|
||||||
|
y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
|
||||||
|
|
||||||
|
This module differs from the built-in PyTorch BatchNorm1d as the mean and
|
||||||
|
standard-deviation are reduced across all devices during training.
|
||||||
|
|
||||||
|
For example, when one uses `nn.DataParallel` to wrap the network during
|
||||||
|
training, PyTorch's implementation normalize the tensor on each device using
|
||||||
|
the statistics only on that device, which accelerated the computation and
|
||||||
|
is also easy to implement, but the statistics might be inaccurate.
|
||||||
|
Instead, in this synchronized version, the statistics will be computed
|
||||||
|
over all training samples distributed on multiple devices.
|
||||||
|
|
||||||
|
Note that, for one-GPU or CPU-only case, this module behaves exactly same
|
||||||
|
as the built-in PyTorch implementation.
|
||||||
|
|
||||||
|
The mean and standard-deviation are calculated per-dimension over
|
||||||
|
the mini-batches and gamma and beta are learnable parameter vectors
|
||||||
|
of size C (where C is the input size).
|
||||||
|
|
||||||
|
During training, this layer keeps a running estimate of its computed mean
|
||||||
|
and variance. The running sum is kept with a default momentum of 0.1.
|
||||||
|
|
||||||
|
During evaluation, this running mean/variance is used for normalization.
|
||||||
|
|
||||||
|
Because the BatchNorm is done over the `C` dimension, computing statistics
|
||||||
|
on `(N, L)` slices, it's common terminology to call this Temporal BatchNorm
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_features: num_features from an expected input of size
|
||||||
|
`batch_size x num_features [x width]`
|
||||||
|
eps: a value added to the denominator for numerical stability.
|
||||||
|
Default: 1e-5
|
||||||
|
momentum: the value used for the running_mean and running_var
|
||||||
|
computation. Default: 0.1
|
||||||
|
affine: a boolean value that when set to ``True``, gives the layer learnable
|
||||||
|
affine parameters. Default: ``True``
|
||||||
|
|
||||||
|
Shape::
|
||||||
|
- Input: :math:`(N, C)` or :math:`(N, C, L)`
|
||||||
|
- Output: :math:`(N, C)` or :math:`(N, C, L)` (same shape as input)
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
>>> # With Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm1d(100)
|
||||||
|
>>> # Without Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm1d(100, affine=False)
|
||||||
|
>>> input = torch.autograd.Variable(torch.randn(20, 100))
|
||||||
|
>>> output = m(input)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def _check_input_dim(self, input):
|
||||||
|
if input.dim() != 2 and input.dim() != 3:
|
||||||
|
raise ValueError('expected 2D or 3D input (got {}D input)'
|
||||||
|
.format(input.dim()))
|
||||||
|
super(SynchronizedBatchNorm1d, self)._check_input_dim(input)
|
||||||
|
|
||||||
|
|
||||||
|
class SynchronizedBatchNorm2d(_SynchronizedBatchNorm):
|
||||||
|
r"""Applies Batch Normalization over a 4d input that is seen as a mini-batch
|
||||||
|
of 3d inputs
|
||||||
|
|
||||||
|
.. math::
|
||||||
|
|
||||||
|
y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
|
||||||
|
|
||||||
|
This module differs from the built-in PyTorch BatchNorm2d as the mean and
|
||||||
|
standard-deviation are reduced across all devices during training.
|
||||||
|
|
||||||
|
For example, when one uses `nn.DataParallel` to wrap the network during
|
||||||
|
training, PyTorch's implementation normalize the tensor on each device using
|
||||||
|
the statistics only on that device, which accelerated the computation and
|
||||||
|
is also easy to implement, but the statistics might be inaccurate.
|
||||||
|
Instead, in this synchronized version, the statistics will be computed
|
||||||
|
over all training samples distributed on multiple devices.
|
||||||
|
|
||||||
|
Note that, for one-GPU or CPU-only case, this module behaves exactly same
|
||||||
|
as the built-in PyTorch implementation.
|
||||||
|
|
||||||
|
The mean and standard-deviation are calculated per-dimension over
|
||||||
|
the mini-batches and gamma and beta are learnable parameter vectors
|
||||||
|
of size C (where C is the input size).
|
||||||
|
|
||||||
|
During training, this layer keeps a running estimate of its computed mean
|
||||||
|
and variance. The running sum is kept with a default momentum of 0.1.
|
||||||
|
|
||||||
|
During evaluation, this running mean/variance is used for normalization.
|
||||||
|
|
||||||
|
Because the BatchNorm is done over the `C` dimension, computing statistics
|
||||||
|
on `(N, H, W)` slices, it's common terminology to call this Spatial BatchNorm
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_features: num_features from an expected input of
|
||||||
|
size batch_size x num_features x height x width
|
||||||
|
eps: a value added to the denominator for numerical stability.
|
||||||
|
Default: 1e-5
|
||||||
|
momentum: the value used for the running_mean and running_var
|
||||||
|
computation. Default: 0.1
|
||||||
|
affine: a boolean value that when set to ``True``, gives the layer learnable
|
||||||
|
affine parameters. Default: ``True``
|
||||||
|
|
||||||
|
Shape::
|
||||||
|
- Input: :math:`(N, C, H, W)`
|
||||||
|
- Output: :math:`(N, C, H, W)` (same shape as input)
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
>>> # With Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm2d(100)
|
||||||
|
>>> # Without Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm2d(100, affine=False)
|
||||||
|
>>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45))
|
||||||
|
>>> output = m(input)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def _check_input_dim(self, input):
|
||||||
|
if input.dim() != 4:
|
||||||
|
raise ValueError('expected 4D input (got {}D input)'
|
||||||
|
.format(input.dim()))
|
||||||
|
super(SynchronizedBatchNorm2d, self)._check_input_dim(input)
|
||||||
|
|
||||||
|
|
||||||
|
class SynchronizedBatchNorm3d(_SynchronizedBatchNorm):
|
||||||
|
r"""Applies Batch Normalization over a 5d input that is seen as a mini-batch
|
||||||
|
of 4d inputs
|
||||||
|
|
||||||
|
.. math::
|
||||||
|
|
||||||
|
y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
|
||||||
|
|
||||||
|
This module differs from the built-in PyTorch BatchNorm3d as the mean and
|
||||||
|
standard-deviation are reduced across all devices during training.
|
||||||
|
|
||||||
|
For example, when one uses `nn.DataParallel` to wrap the network during
|
||||||
|
training, PyTorch's implementation normalize the tensor on each device using
|
||||||
|
the statistics only on that device, which accelerated the computation and
|
||||||
|
is also easy to implement, but the statistics might be inaccurate.
|
||||||
|
Instead, in this synchronized version, the statistics will be computed
|
||||||
|
over all training samples distributed on multiple devices.
|
||||||
|
|
||||||
|
Note that, for one-GPU or CPU-only case, this module behaves exactly same
|
||||||
|
as the built-in PyTorch implementation.
|
||||||
|
|
||||||
|
The mean and standard-deviation are calculated per-dimension over
|
||||||
|
the mini-batches and gamma and beta are learnable parameter vectors
|
||||||
|
of size C (where C is the input size).
|
||||||
|
|
||||||
|
During training, this layer keeps a running estimate of its computed mean
|
||||||
|
and variance. The running sum is kept with a default momentum of 0.1.
|
||||||
|
|
||||||
|
During evaluation, this running mean/variance is used for normalization.
|
||||||
|
|
||||||
|
Because the BatchNorm is done over the `C` dimension, computing statistics
|
||||||
|
on `(N, D, H, W)` slices, it's common terminology to call this Volumetric BatchNorm
|
||||||
|
or Spatio-temporal BatchNorm
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_features: num_features from an expected input of
|
||||||
|
size batch_size x num_features x depth x height x width
|
||||||
|
eps: a value added to the denominator for numerical stability.
|
||||||
|
Default: 1e-5
|
||||||
|
momentum: the value used for the running_mean and running_var
|
||||||
|
computation. Default: 0.1
|
||||||
|
affine: a boolean value that when set to ``True``, gives the layer learnable
|
||||||
|
affine parameters. Default: ``True``
|
||||||
|
|
||||||
|
Shape::
|
||||||
|
- Input: :math:`(N, C, D, H, W)`
|
||||||
|
- Output: :math:`(N, C, D, H, W)` (same shape as input)
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
>>> # With Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm3d(100)
|
||||||
|
>>> # Without Learnable Parameters
|
||||||
|
>>> m = SynchronizedBatchNorm3d(100, affine=False)
|
||||||
|
>>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45, 10))
|
||||||
|
>>> output = m(input)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def _check_input_dim(self, input):
|
||||||
|
if input.dim() != 5:
|
||||||
|
raise ValueError('expected 5D input (got {}D input)'
|
||||||
|
.format(input.dim()))
|
||||||
|
super(SynchronizedBatchNorm3d, self)._check_input_dim(input)
|
||||||
|
|
||||||
|
|
||||||
|
@contextlib.contextmanager
|
||||||
|
def patch_sync_batchnorm():
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
backup = nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
|
||||||
|
|
||||||
|
nn.BatchNorm1d = SynchronizedBatchNorm1d
|
||||||
|
nn.BatchNorm2d = SynchronizedBatchNorm2d
|
||||||
|
nn.BatchNorm3d = SynchronizedBatchNorm3d
|
||||||
|
|
||||||
|
yield
|
||||||
|
|
||||||
|
nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d = backup
|
||||||
|
|
||||||
|
|
||||||
|
def convert_model(module):
|
||||||
|
"""Traverse the input module and its child recursively
|
||||||
|
and replace all instance of torch.nn.modules.batchnorm.BatchNorm*N*d
|
||||||
|
to SynchronizedBatchNorm*N*d
|
||||||
|
|
||||||
|
Args:
|
||||||
|
module: the input module needs to be convert to SyncBN model
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
>>> import torch.nn as nn
|
||||||
|
>>> import torchvision
|
||||||
|
>>> # m is a standard pytorch model
|
||||||
|
>>> m = torchvision.models.resnet18(True)
|
||||||
|
>>> m = nn.DataParallel(m)
|
||||||
|
>>> # after convert, m is using SyncBN
|
||||||
|
>>> m = convert_model(m)
|
||||||
|
"""
|
||||||
|
if isinstance(module, torch.nn.DataParallel):
|
||||||
|
mod = module.module
|
||||||
|
mod = convert_model(mod)
|
||||||
|
mod = DataParallelWithCallback(mod, device_ids=module.device_ids)
|
||||||
|
return mod
|
||||||
|
|
||||||
|
mod = module
|
||||||
|
for pth_module, sync_module in zip([torch.nn.modules.batchnorm.BatchNorm1d,
|
||||||
|
torch.nn.modules.batchnorm.BatchNorm2d,
|
||||||
|
torch.nn.modules.batchnorm.BatchNorm3d],
|
||||||
|
[SynchronizedBatchNorm1d,
|
||||||
|
SynchronizedBatchNorm2d,
|
||||||
|
SynchronizedBatchNorm3d]):
|
||||||
|
if isinstance(module, pth_module):
|
||||||
|
mod = sync_module(module.num_features, module.eps, module.momentum, module.affine)
|
||||||
|
mod.running_mean = module.running_mean
|
||||||
|
mod.running_var = module.running_var
|
||||||
|
if module.affine:
|
||||||
|
mod.weight.data = module.weight.data.clone().detach()
|
||||||
|
mod.bias.data = module.bias.data.clone().detach()
|
||||||
|
|
||||||
|
for name, child in module.named_children():
|
||||||
|
mod.add_module(name, convert_model(child))
|
||||||
|
|
||||||
|
return mod
|
||||||
|
|
@ -0,0 +1,74 @@
|
||||||
|
#! /usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : batchnorm_reimpl.py
|
||||||
|
# Author : acgtyrant
|
||||||
|
# Date : 11/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.init as init
|
||||||
|
|
||||||
|
__all__ = ['BatchNorm2dReimpl']
|
||||||
|
|
||||||
|
|
||||||
|
class BatchNorm2dReimpl(nn.Module):
|
||||||
|
"""
|
||||||
|
A re-implementation of batch normalization, used for testing the numerical
|
||||||
|
stability.
|
||||||
|
|
||||||
|
Author: acgtyrant
|
||||||
|
See also:
|
||||||
|
https://github.com/vacancy/Synchronized-BatchNorm-PyTorch/issues/14
|
||||||
|
"""
|
||||||
|
def __init__(self, num_features, eps=1e-5, momentum=0.1):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
self.num_features = num_features
|
||||||
|
self.eps = eps
|
||||||
|
self.momentum = momentum
|
||||||
|
self.weight = nn.Parameter(torch.empty(num_features))
|
||||||
|
self.bias = nn.Parameter(torch.empty(num_features))
|
||||||
|
self.register_buffer('running_mean', torch.zeros(num_features))
|
||||||
|
self.register_buffer('running_var', torch.ones(num_features))
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_running_stats(self):
|
||||||
|
self.running_mean.zero_()
|
||||||
|
self.running_var.fill_(1)
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
self.reset_running_stats()
|
||||||
|
init.uniform_(self.weight)
|
||||||
|
init.zeros_(self.bias)
|
||||||
|
|
||||||
|
def forward(self, input_):
|
||||||
|
batchsize, channels, height, width = input_.size()
|
||||||
|
numel = batchsize * height * width
|
||||||
|
input_ = input_.permute(1, 0, 2, 3).contiguous().view(channels, numel)
|
||||||
|
sum_ = input_.sum(1)
|
||||||
|
sum_of_square = input_.pow(2).sum(1)
|
||||||
|
mean = sum_ / numel
|
||||||
|
sumvar = sum_of_square - sum_ * mean
|
||||||
|
|
||||||
|
self.running_mean = (
|
||||||
|
(1 - self.momentum) * self.running_mean
|
||||||
|
+ self.momentum * mean.detach()
|
||||||
|
)
|
||||||
|
unbias_var = sumvar / (numel - 1)
|
||||||
|
self.running_var = (
|
||||||
|
(1 - self.momentum) * self.running_var
|
||||||
|
+ self.momentum * unbias_var.detach()
|
||||||
|
)
|
||||||
|
|
||||||
|
bias_var = sumvar / numel
|
||||||
|
inv_std = 1 / (bias_var + self.eps).pow(0.5)
|
||||||
|
output = (
|
||||||
|
(input_ - mean.unsqueeze(1)) * inv_std.unsqueeze(1) *
|
||||||
|
self.weight.unsqueeze(1) + self.bias.unsqueeze(1))
|
||||||
|
|
||||||
|
return output.view(channels, batchsize, height, width).permute(1, 0, 2, 3).contiguous()
|
||||||
|
|
||||||
137
detection/models/detection/efficientdet/sync_batchnorm/comm.py
Normal file
137
detection/models/detection/efficientdet/sync_batchnorm/comm.py
Normal file
|
|
@ -0,0 +1,137 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : comm.py
|
||||||
|
# Author : Jiayuan Mao
|
||||||
|
# Email : maojiayuan@gmail.com
|
||||||
|
# Date : 27/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
import queue
|
||||||
|
import collections
|
||||||
|
import threading
|
||||||
|
|
||||||
|
__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster']
|
||||||
|
|
||||||
|
|
||||||
|
class FutureResult(object):
|
||||||
|
"""A thread-safe future implementation. Used only as one-to-one pipe."""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self._result = None
|
||||||
|
self._lock = threading.Lock()
|
||||||
|
self._cond = threading.Condition(self._lock)
|
||||||
|
|
||||||
|
def put(self, result):
|
||||||
|
with self._lock:
|
||||||
|
assert self._result is None, 'Previous result has\'t been fetched.'
|
||||||
|
self._result = result
|
||||||
|
self._cond.notify()
|
||||||
|
|
||||||
|
def get(self):
|
||||||
|
with self._lock:
|
||||||
|
if self._result is None:
|
||||||
|
self._cond.wait()
|
||||||
|
|
||||||
|
res = self._result
|
||||||
|
self._result = None
|
||||||
|
return res
|
||||||
|
|
||||||
|
|
||||||
|
_MasterRegistry = collections.namedtuple('MasterRegistry', ['result'])
|
||||||
|
_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result'])
|
||||||
|
|
||||||
|
|
||||||
|
class SlavePipe(_SlavePipeBase):
|
||||||
|
"""Pipe for master-slave communication."""
|
||||||
|
|
||||||
|
def run_slave(self, msg):
|
||||||
|
self.queue.put((self.identifier, msg))
|
||||||
|
ret = self.result.get()
|
||||||
|
self.queue.put(True)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
|
||||||
|
class SyncMaster(object):
|
||||||
|
"""An abstract `SyncMaster` object.
|
||||||
|
|
||||||
|
- During the replication, as the data parallel will trigger an callback of each module, all slave devices should
|
||||||
|
call `register(id)` and obtain an `SlavePipe` to communicate with the master.
|
||||||
|
- During the forward pass, master device invokes `run_master`, all messages from slave devices will be collected,
|
||||||
|
and passed to a registered callback.
|
||||||
|
- After receiving the messages, the master device should gather the information and determine to message passed
|
||||||
|
back to each slave devices.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, master_callback):
|
||||||
|
"""
|
||||||
|
|
||||||
|
Args:
|
||||||
|
master_callback: a callback to be invoked after having collected messages from slave devices.
|
||||||
|
"""
|
||||||
|
self._master_callback = master_callback
|
||||||
|
self._queue = queue.Queue()
|
||||||
|
self._registry = collections.OrderedDict()
|
||||||
|
self._activated = False
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
return {'master_callback': self._master_callback}
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
self.__init__(state['master_callback'])
|
||||||
|
|
||||||
|
def register_slave(self, identifier):
|
||||||
|
"""
|
||||||
|
Register an slave device.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
identifier: an identifier, usually is the device id.
|
||||||
|
|
||||||
|
Returns: a `SlavePipe` object which can be used to communicate with the master device.
|
||||||
|
|
||||||
|
"""
|
||||||
|
if self._activated:
|
||||||
|
assert self._queue.empty(), 'Queue is not clean before next initialization.'
|
||||||
|
self._activated = False
|
||||||
|
self._registry.clear()
|
||||||
|
future = FutureResult()
|
||||||
|
self._registry[identifier] = _MasterRegistry(future)
|
||||||
|
return SlavePipe(identifier, self._queue, future)
|
||||||
|
|
||||||
|
def run_master(self, master_msg):
|
||||||
|
"""
|
||||||
|
Main entry for the master device in each forward pass.
|
||||||
|
The messages were first collected from each devices (including the master device), and then
|
||||||
|
an callback will be invoked to compute the message to be sent back to each devices
|
||||||
|
(including the master device).
|
||||||
|
|
||||||
|
Args:
|
||||||
|
master_msg: the message that the master want to send to itself. This will be placed as the first
|
||||||
|
message when calling `master_callback`. For detailed usage, see `_SynchronizedBatchNorm` for an example.
|
||||||
|
|
||||||
|
Returns: the message to be sent back to the master device.
|
||||||
|
|
||||||
|
"""
|
||||||
|
self._activated = True
|
||||||
|
|
||||||
|
intermediates = [(0, master_msg)]
|
||||||
|
for i in range(self.nr_slaves):
|
||||||
|
intermediates.append(self._queue.get())
|
||||||
|
|
||||||
|
results = self._master_callback(intermediates)
|
||||||
|
assert results[0][0] == 0, 'The first result should belongs to the master.'
|
||||||
|
|
||||||
|
for i, res in results:
|
||||||
|
if i == 0:
|
||||||
|
continue
|
||||||
|
self._registry[i].result.put(res)
|
||||||
|
|
||||||
|
for i in range(self.nr_slaves):
|
||||||
|
assert self._queue.get() is True
|
||||||
|
|
||||||
|
return results[0][1]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def nr_slaves(self):
|
||||||
|
return len(self._registry)
|
||||||
|
|
@ -0,0 +1,94 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : replicate.py
|
||||||
|
# Author : Jiayuan Mao
|
||||||
|
# Email : maojiayuan@gmail.com
|
||||||
|
# Date : 27/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
import functools
|
||||||
|
|
||||||
|
from torch.nn.parallel.data_parallel import DataParallel
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
'CallbackContext',
|
||||||
|
'execute_replication_callbacks',
|
||||||
|
'DataParallelWithCallback',
|
||||||
|
'patch_replication_callback'
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class CallbackContext(object):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def execute_replication_callbacks(modules):
|
||||||
|
"""
|
||||||
|
Execute an replication callback `__data_parallel_replicate__` on each module created by original replication.
|
||||||
|
|
||||||
|
The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
|
||||||
|
|
||||||
|
Note that, as all modules are isomorphism, we assign each sub-module with a context
|
||||||
|
(shared among multiple copies of this module on different devices).
|
||||||
|
Through this context, different copies can share some information.
|
||||||
|
|
||||||
|
We guarantee that the callback on the master copy (the first copy) will be called ahead of calling the callback
|
||||||
|
of any slave copies.
|
||||||
|
"""
|
||||||
|
master_copy = modules[0]
|
||||||
|
nr_modules = len(list(master_copy.modules()))
|
||||||
|
ctxs = [CallbackContext() for _ in range(nr_modules)]
|
||||||
|
|
||||||
|
for i, module in enumerate(modules):
|
||||||
|
for j, m in enumerate(module.modules()):
|
||||||
|
if hasattr(m, '__data_parallel_replicate__'):
|
||||||
|
m.__data_parallel_replicate__(ctxs[j], i)
|
||||||
|
|
||||||
|
|
||||||
|
class DataParallelWithCallback(DataParallel):
|
||||||
|
"""
|
||||||
|
Data Parallel with a replication callback.
|
||||||
|
|
||||||
|
An replication callback `__data_parallel_replicate__` of each module will be invoked after being created by
|
||||||
|
original `replicate` function.
|
||||||
|
The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
> sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
|
||||||
|
> sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
|
||||||
|
# sync_bn.__data_parallel_replicate__ will be invoked.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def replicate(self, module, device_ids):
|
||||||
|
modules = super(DataParallelWithCallback, self).replicate(module, device_ids)
|
||||||
|
execute_replication_callbacks(modules)
|
||||||
|
return modules
|
||||||
|
|
||||||
|
|
||||||
|
def patch_replication_callback(data_parallel):
|
||||||
|
"""
|
||||||
|
Monkey-patch an existing `DataParallel` object. Add the replication callback.
|
||||||
|
Useful when you have customized `DataParallel` implementation.
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
> sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
|
||||||
|
> sync_bn = DataParallel(sync_bn, device_ids=[0, 1])
|
||||||
|
> patch_replication_callback(sync_bn)
|
||||||
|
# this is equivalent to
|
||||||
|
> sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
|
||||||
|
> sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
|
||||||
|
"""
|
||||||
|
|
||||||
|
assert isinstance(data_parallel, DataParallel)
|
||||||
|
|
||||||
|
old_replicate = data_parallel.replicate
|
||||||
|
|
||||||
|
@functools.wraps(old_replicate)
|
||||||
|
def new_replicate(module, device_ids):
|
||||||
|
modules = old_replicate(module, device_ids)
|
||||||
|
execute_replication_callbacks(modules)
|
||||||
|
return modules
|
||||||
|
|
||||||
|
data_parallel.replicate = new_replicate
|
||||||
|
|
@ -0,0 +1,29 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
# File : unittest.py
|
||||||
|
# Author : Jiayuan Mao
|
||||||
|
# Email : maojiayuan@gmail.com
|
||||||
|
# Date : 27/01/2018
|
||||||
|
#
|
||||||
|
# This file is part of Synchronized-BatchNorm-PyTorch.
|
||||||
|
# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
|
||||||
|
# Distributed under MIT License.
|
||||||
|
|
||||||
|
import unittest
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
class TorchTestCase(unittest.TestCase):
|
||||||
|
def assertTensorClose(self, x, y):
|
||||||
|
adiff = float((x - y).abs().max())
|
||||||
|
if (y == 0).all():
|
||||||
|
rdiff = 'NaN'
|
||||||
|
else:
|
||||||
|
rdiff = float((adiff / y).abs().max())
|
||||||
|
|
||||||
|
message = (
|
||||||
|
'Tensor close check failed\n'
|
||||||
|
'adiff={}\n'
|
||||||
|
'rdiff={}\n'
|
||||||
|
).format(adiff, rdiff)
|
||||||
|
self.assertTrue(torch.allclose(x, y), message)
|
||||||
|
|
||||||
139
detection/models/detection/efficientdet/utils.py
Normal file
139
detection/models/detection/efficientdet/utils.py
Normal file
|
|
@ -0,0 +1,139 @@
|
||||||
|
import itertools
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
|
class BBoxTransform(nn.Module):
|
||||||
|
def forward(self, anchors, regression):
|
||||||
|
"""
|
||||||
|
decode_box_outputs adapted from https://github.com/google/automl/blob/master/efficientdet/anchors.py
|
||||||
|
|
||||||
|
Args:
|
||||||
|
anchors: [batchsize, boxes, (y1, x1, y2, x2)]
|
||||||
|
regression: [batchsize, boxes, (dy, dx, dh, dw)]
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
|
||||||
|
"""
|
||||||
|
y_centers_a = (anchors[..., 0] + anchors[..., 2]) / 2
|
||||||
|
x_centers_a = (anchors[..., 1] + anchors[..., 3]) / 2
|
||||||
|
ha = anchors[..., 2] - anchors[..., 0]
|
||||||
|
wa = anchors[..., 3] - anchors[..., 1]
|
||||||
|
|
||||||
|
w = regression[..., 3].exp() * wa
|
||||||
|
h = regression[..., 2].exp() * ha
|
||||||
|
|
||||||
|
y_centers = regression[..., 0] * ha + y_centers_a
|
||||||
|
x_centers = regression[..., 1] * wa + x_centers_a
|
||||||
|
|
||||||
|
ymin = y_centers - h / 2.
|
||||||
|
xmin = x_centers - w / 2.
|
||||||
|
ymax = y_centers + h / 2.
|
||||||
|
xmax = x_centers + w / 2.
|
||||||
|
|
||||||
|
return torch.stack([xmin, ymin, xmax, ymax], dim=2)
|
||||||
|
|
||||||
|
|
||||||
|
class ClipBoxes(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super(ClipBoxes, self).__init__()
|
||||||
|
|
||||||
|
def forward(self, boxes, img):
|
||||||
|
batch_size, num_channels, height, width = img.shape
|
||||||
|
|
||||||
|
boxes[:, :, 0] = torch.clamp(boxes[:, :, 0], min=0)
|
||||||
|
boxes[:, :, 1] = torch.clamp(boxes[:, :, 1], min=0)
|
||||||
|
|
||||||
|
boxes[:, :, 2] = torch.clamp(boxes[:, :, 2], max=width - 1)
|
||||||
|
boxes[:, :, 3] = torch.clamp(boxes[:, :, 3], max=height - 1)
|
||||||
|
|
||||||
|
return boxes
|
||||||
|
|
||||||
|
|
||||||
|
class Anchors(nn.Module):
|
||||||
|
"""
|
||||||
|
adapted and modified from https://github.com/google/automl/blob/master/efficientdet/anchors.py by Zylo117
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, anchor_scale=4., pyramid_levels=None, **kwargs):
|
||||||
|
super().__init__()
|
||||||
|
self.anchor_scale = anchor_scale
|
||||||
|
|
||||||
|
if pyramid_levels is None:
|
||||||
|
self.pyramid_levels = [3, 4, 5, 6, 7]
|
||||||
|
else:
|
||||||
|
self.pyramid_levels = pyramid_levels
|
||||||
|
|
||||||
|
self.strides = kwargs.get('strides', [2 ** x for x in self.pyramid_levels])
|
||||||
|
self.scales = np.array(kwargs.get('scales', [2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]))
|
||||||
|
self.ratios = kwargs.get('ratios', [(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)])
|
||||||
|
|
||||||
|
self.last_anchors = {}
|
||||||
|
self.last_shape = None
|
||||||
|
|
||||||
|
def forward(self, image, dtype=torch.float32):
|
||||||
|
"""Generates multiscale anchor boxes.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
image_size: integer number of input image size. The input image has the
|
||||||
|
same dimension for width and height. The image_size should be divided by
|
||||||
|
the largest feature stride 2^max_level.
|
||||||
|
anchor_scale: float number representing the scale of size of the base
|
||||||
|
anchor to the feature stride 2^level.
|
||||||
|
anchor_configs: a dictionary with keys as the levels of anchors and
|
||||||
|
values as a list of anchor configuration.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
anchor_boxes: a numpy array with shape [N, 4], which stacks anchors on all
|
||||||
|
feature levels.
|
||||||
|
Raises:
|
||||||
|
ValueError: input size must be the multiple of largest feature stride.
|
||||||
|
"""
|
||||||
|
image_shape = image.shape[2:]
|
||||||
|
|
||||||
|
if image_shape == self.last_shape and image.device in self.last_anchors:
|
||||||
|
return self.last_anchors[image.device]
|
||||||
|
|
||||||
|
if self.last_shape is None or self.last_shape != image_shape:
|
||||||
|
self.last_shape = image_shape
|
||||||
|
|
||||||
|
if dtype == torch.float16:
|
||||||
|
dtype = np.float16
|
||||||
|
else:
|
||||||
|
dtype = np.float32
|
||||||
|
|
||||||
|
boxes_all = []
|
||||||
|
for stride in self.strides:
|
||||||
|
boxes_level = []
|
||||||
|
for scale, ratio in itertools.product(self.scales, self.ratios):
|
||||||
|
if image_shape[1] % stride != 0:
|
||||||
|
raise ValueError('input size must be divided by the stride.')
|
||||||
|
base_anchor_size = self.anchor_scale * stride * scale
|
||||||
|
anchor_size_x_2 = base_anchor_size * ratio[0] / 2.0
|
||||||
|
anchor_size_y_2 = base_anchor_size * ratio[1] / 2.0
|
||||||
|
|
||||||
|
x = np.arange(stride / 2, image_shape[1], stride)
|
||||||
|
y = np.arange(stride / 2, image_shape[0], stride)
|
||||||
|
xv, yv = np.meshgrid(x, y)
|
||||||
|
xv = xv.reshape(-1)
|
||||||
|
yv = yv.reshape(-1)
|
||||||
|
|
||||||
|
# y1,x1,y2,x2
|
||||||
|
boxes = np.vstack((yv - anchor_size_y_2, xv - anchor_size_x_2,
|
||||||
|
yv + anchor_size_y_2, xv + anchor_size_x_2))
|
||||||
|
boxes = np.swapaxes(boxes, 0, 1)
|
||||||
|
boxes_level.append(np.expand_dims(boxes, axis=1))
|
||||||
|
# concat anchors on the same level to the reshape NxAx4
|
||||||
|
boxes_level = np.concatenate(boxes_level, axis=1)
|
||||||
|
boxes_all.append(boxes_level.reshape([-1, 4]))
|
||||||
|
|
||||||
|
anchor_boxes = np.vstack(boxes_all)
|
||||||
|
|
||||||
|
anchor_boxes = torch.from_numpy(anchor_boxes.astype(dtype)).to(image.device)
|
||||||
|
anchor_boxes = anchor_boxes.unsqueeze(0)
|
||||||
|
|
||||||
|
# save it for later use to reduce overhead
|
||||||
|
self.last_anchors[image.device] = anchor_boxes
|
||||||
|
return anchor_boxes
|
||||||
96
detection/models/detection/yolo/__init__.py
Normal file
96
detection/models/detection/yolo/__init__.py
Normal file
|
|
@ -0,0 +1,96 @@
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from detectron2.structures import Instances, Boxes
|
||||||
|
|
||||||
|
from .backbone import Darknet
|
||||||
|
from .utils import (xy_to_cxcy,
|
||||||
|
non_max_suppression)
|
||||||
|
from . import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOv3Model(nn.Module):
|
||||||
|
"""YOLO V3 model:
|
||||||
|
https://github.com/eriklindernoren/PyTorch-YOLOv3.git
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, cfg_name, model_args=None):
|
||||||
|
super().__init__()
|
||||||
|
num_classes = model_args.get("num_classes", None)
|
||||||
|
self.conf_threshold = model_args.get("conf_threshold", 0.8)
|
||||||
|
self.nms_threshold = model_args.get("nms_threshold", 0.4)
|
||||||
|
pretrained = model_args.get("pretrained", False)
|
||||||
|
ignore_width = model_args.get("ignore_width", 0)
|
||||||
|
cfg_path = C.CONFIGS[cfg_name]
|
||||||
|
self.model = Darknet(cfg_path,
|
||||||
|
num_classes=num_classes,
|
||||||
|
ignore_width=ignore_width)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def to_numpy(v):
|
||||||
|
if isinstance(v, np.ndarray):
|
||||||
|
return v
|
||||||
|
else:
|
||||||
|
return v.detach().cpu().numpy()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
"""
|
||||||
|
To N x (img_id, class_id, cx, cy, w, h) format
|
||||||
|
"""
|
||||||
|
N = len(x)
|
||||||
|
imgs = torch.stack([sample['image'].float() for sample in x])
|
||||||
|
width = imgs.shape[2]
|
||||||
|
height = imgs.shape[3]
|
||||||
|
if height != 416 or width != 416:
|
||||||
|
raise ValueError(
|
||||||
|
f"Input images must of size 416 x 416 but is {width} x {height}")
|
||||||
|
|
||||||
|
annotations = []
|
||||||
|
for i, sample in enumerate(x):
|
||||||
|
instances = sample['instances']
|
||||||
|
boxes = self.to_numpy(instances.gt_boxes.tensor)
|
||||||
|
class_ids = self.to_numpy(instances.gt_classes)
|
||||||
|
for class_id, box in zip(class_ids, boxes):
|
||||||
|
cx, cy, w, h = xy_to_cxcy(box, width, height)
|
||||||
|
annotations.append([i, class_id, cx, cy, w, h])
|
||||||
|
annotations = np.stack(annotations, 0)
|
||||||
|
annotations = torch.from_numpy(annotations).float()
|
||||||
|
return self.model(imgs, annotations)[0]
|
||||||
|
|
||||||
|
def infer(self, x):
|
||||||
|
"""
|
||||||
|
From N x (xmin, ymin, xmax, ymax, conf, cls_conf_1, cls_conf_2, ..., cls_conf_k) format
|
||||||
|
"""
|
||||||
|
imgs = torch.stack([sample['image'].float() for sample in x])
|
||||||
|
width = imgs.shape[2]
|
||||||
|
height = imgs.shape[3]
|
||||||
|
if height != 416 or width != 416:
|
||||||
|
raise ValueError(
|
||||||
|
f"Input images must of size 416 x 416 but is {width} x {height}")
|
||||||
|
rois = self.model.infer(imgs)
|
||||||
|
rois = non_max_suppression(rois,
|
||||||
|
self.conf_threshold,
|
||||||
|
self.nms_threshold)
|
||||||
|
outs = []
|
||||||
|
for sample_input, sample_output in zip(x, rois):
|
||||||
|
instances = Instances(
|
||||||
|
(sample_input['height'], sample_input['width']))
|
||||||
|
print(sample_output)
|
||||||
|
if sample_output is not None and len(sample_output):
|
||||||
|
instances.pred_boxes = Boxes(sample_output[:, :4])
|
||||||
|
instances.scores = torch.tensor(sample_output[:, 4])
|
||||||
|
class_conf, class_id = sample_output[:, 5:].max(1)
|
||||||
|
instances.pred_classes = torch.tensor(class_id)
|
||||||
|
outs.append({"instances": instances})
|
||||||
|
return outs
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOv3(YOLOv3Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__("yolov3", model_args)
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOv3Tiny(YOLOv3Model):
|
||||||
|
def __init__(self, model_args=None):
|
||||||
|
super().__init__("yolov3-tiny", model_args)
|
||||||
408
detection/models/detection/yolo/backbone.py
Normal file
408
detection/models/detection/yolo/backbone.py
Normal file
|
|
@ -0,0 +1,408 @@
|
||||||
|
'''
|
||||||
|
ABOUT THIS SCRIPT:
|
||||||
|
This is a yolov3 implementation that constructs the appropriate
|
||||||
|
yolov3 model layers and performs forward runs as per these modules
|
||||||
|
|
||||||
|
This script is a slightly modified version of the follwoing repo:
|
||||||
|
https://github.com/eriklindernoren/PyTorch-YOLOv3.git
|
||||||
|
|
||||||
|
'''
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from torch.autograd import Variable
|
||||||
|
|
||||||
|
from .utils import (slice_boundary,
|
||||||
|
parse_model_config,
|
||||||
|
to_cpu,
|
||||||
|
build_targets)
|
||||||
|
|
||||||
|
from . import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def create_modules(module_defs, ignore_width):
|
||||||
|
"""
|
||||||
|
Constructs module list of layer blocks from module configuration in module_defs
|
||||||
|
"""
|
||||||
|
hyperparams = module_defs.pop(0)
|
||||||
|
output_filters = [int(hyperparams["channels"])]
|
||||||
|
module_list = nn.ModuleList()
|
||||||
|
for module_i, module_def in enumerate(module_defs):
|
||||||
|
modules = nn.Sequential()
|
||||||
|
|
||||||
|
if module_def["type"] == "convolutional":
|
||||||
|
bn = int(module_def["batch_normalize"])
|
||||||
|
filters = int(module_def["filters"])
|
||||||
|
kernel_size = int(module_def["size"])
|
||||||
|
pad = (kernel_size - 1) // 2
|
||||||
|
modules.add_module(
|
||||||
|
f"conv_{module_i}",
|
||||||
|
nn.Conv2d(
|
||||||
|
in_channels=output_filters[-1],
|
||||||
|
out_channels=filters,
|
||||||
|
kernel_size=kernel_size,
|
||||||
|
stride=int(module_def["stride"]),
|
||||||
|
padding=pad,
|
||||||
|
bias=not bn,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
if bn:
|
||||||
|
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(
|
||||||
|
filters, momentum=0.9, eps=1e-5))
|
||||||
|
if module_def["activation"] == "leaky":
|
||||||
|
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))
|
||||||
|
|
||||||
|
elif module_def["type"] == "maxpool":
|
||||||
|
kernel_size = int(module_def["size"])
|
||||||
|
stride = int(module_def["stride"])
|
||||||
|
if kernel_size == 2 and stride == 1:
|
||||||
|
modules.add_module(
|
||||||
|
f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
|
||||||
|
maxpool = nn.MaxPool2d(
|
||||||
|
kernel_size=kernel_size,
|
||||||
|
stride=stride,
|
||||||
|
padding=int(
|
||||||
|
(kernel_size - 1) // 2))
|
||||||
|
modules.add_module(f"maxpool_{module_i}", maxpool)
|
||||||
|
|
||||||
|
elif module_def["type"] == "upsample":
|
||||||
|
upsample = Upsample(scale_factor=int(
|
||||||
|
module_def["stride"]), mode="nearest")
|
||||||
|
modules.add_module(f"upsample_{module_i}", upsample)
|
||||||
|
|
||||||
|
elif module_def["type"] == "route":
|
||||||
|
layers = [int(x) for x in module_def["layers"].split(",")]
|
||||||
|
filters = sum([output_filters[1:][i] for i in layers])
|
||||||
|
modules.add_module(f"route_{module_i}", EmptyLayer())
|
||||||
|
|
||||||
|
elif module_def["type"] == "shortcut":
|
||||||
|
filters = output_filters[1:][int(module_def["from"])]
|
||||||
|
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
|
||||||
|
|
||||||
|
elif module_def["type"] == "yolo":
|
||||||
|
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
|
||||||
|
# Extract anchors
|
||||||
|
anchors = [int(x) for x in module_def["anchors"].split(",")]
|
||||||
|
anchors = [(anchors[i], anchors[i + 1])
|
||||||
|
for i in range(0, len(anchors), 2)]
|
||||||
|
anchors = [anchors[i] for i in anchor_idxs]
|
||||||
|
num_classes = int(module_def["classes"])
|
||||||
|
img_size = int(hyperparams["height"])
|
||||||
|
# Define detection layer
|
||||||
|
yolo_layer = YOLOLayer(anchors, num_classes, ignore_width, img_size)
|
||||||
|
modules.add_module(f"yolo_{module_i}", yolo_layer)
|
||||||
|
# Register module list and number of output filters
|
||||||
|
module_list.append(modules)
|
||||||
|
output_filters.append(filters)
|
||||||
|
|
||||||
|
return hyperparams, module_list
|
||||||
|
|
||||||
|
|
||||||
|
class Upsample(nn.Module):
|
||||||
|
""" nn.Upsample is deprecated """
|
||||||
|
|
||||||
|
def __init__(self, scale_factor, mode="nearest"):
|
||||||
|
super(Upsample, self).__init__()
|
||||||
|
self.scale_factor = scale_factor
|
||||||
|
self.mode = mode
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class EmptyLayer(nn.Module):
|
||||||
|
"""Placeholder for 'route' and 'shortcut' layers"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super(EmptyLayer, self).__init__()
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOLayer(nn.Module):
|
||||||
|
"""Detection layer"""
|
||||||
|
|
||||||
|
def __init__(self, anchors, num_classes, ignore_width=32, img_dim=416):
|
||||||
|
super(YOLOLayer, self).__init__()
|
||||||
|
self.anchors = anchors
|
||||||
|
self.num_anchors = len(anchors)
|
||||||
|
self.num_classes = num_classes
|
||||||
|
self.ignore_width = ignore_width
|
||||||
|
self.ignore_thres = 0.5
|
||||||
|
self.mse_loss = nn.MSELoss()
|
||||||
|
self.bce_loss = nn.BCELoss()
|
||||||
|
self.obj_scale = 1
|
||||||
|
self.noobj_scale = 100
|
||||||
|
self.metrics = {}
|
||||||
|
self.img_dim = img_dim
|
||||||
|
self.grid_size = 0 # grid size
|
||||||
|
|
||||||
|
def compute_grid_offsets(self, grid_size, cuda=True):
|
||||||
|
self.grid_size = grid_size
|
||||||
|
g = self.grid_size
|
||||||
|
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
|
||||||
|
self.stride = self.img_dim / self.grid_size
|
||||||
|
# Calculate offsets for each grid
|
||||||
|
self.grid_x = torch.arange(g).repeat(
|
||||||
|
g, 1).view([1, 1, g, g]).type(FloatTensor)
|
||||||
|
self.grid_y = torch.arange(g).repeat(
|
||||||
|
g, 1).t().view([1, 1, g, g]).type(FloatTensor)
|
||||||
|
self.scaled_anchors = FloatTensor(
|
||||||
|
[(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
|
||||||
|
self.anchor_w = self.scaled_anchors[:, 0:1].view(
|
||||||
|
(1, self.num_anchors, 1, 1))
|
||||||
|
self.anchor_h = self.scaled_anchors[:, 1:2].view(
|
||||||
|
(1, self.num_anchors, 1, 1))
|
||||||
|
|
||||||
|
def forward(self, x, targets=None, image_size=416, return_metrics=False):
|
||||||
|
# Tensors for cuda support
|
||||||
|
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
|
||||||
|
self.img_dim = image_size
|
||||||
|
num_samples = x.size(0)
|
||||||
|
grid_size = x.size(2)
|
||||||
|
|
||||||
|
prediction = (
|
||||||
|
x.view(num_samples, self.num_anchors,
|
||||||
|
self.num_classes + 5, grid_size, grid_size)
|
||||||
|
.permute(0, 1, 3, 4, 2)
|
||||||
|
.contiguous()
|
||||||
|
)
|
||||||
|
|
||||||
|
# Get outputs
|
||||||
|
x = torch.sigmoid(prediction[..., 0]) # Center x
|
||||||
|
y = torch.sigmoid(prediction[..., 1]) # Center y
|
||||||
|
w = prediction[..., 2] # Width
|
||||||
|
h = prediction[..., 3] # Height
|
||||||
|
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
|
||||||
|
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
|
||||||
|
|
||||||
|
if grid_size != self.grid_size:
|
||||||
|
self.compute_grid_offsets(grid_size, cuda=x.is_cuda)
|
||||||
|
|
||||||
|
# Add offset and scale with anchors
|
||||||
|
pred_boxes = FloatTensor(prediction[..., :4].shape)
|
||||||
|
pred_boxes[..., 0] = x.data + self.grid_x
|
||||||
|
pred_boxes[..., 1] = y.data + self.grid_y
|
||||||
|
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
|
||||||
|
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
|
||||||
|
|
||||||
|
# Only keep predictions inside the boundary
|
||||||
|
# Note: Due to FPN, predictions across different scales are combined
|
||||||
|
# Need to adjust slice boundary accordingly
|
||||||
|
assert (grid_size * self.ignore_width) % C.SIZE == 0
|
||||||
|
boundary = grid_size * self.ignore_width // C.SIZE
|
||||||
|
output = torch.cat(
|
||||||
|
(slice_boundary(
|
||||||
|
pred_boxes, boundary).view(
|
||||||
|
num_samples, -1, 4) * self.stride, slice_boundary(
|
||||||
|
pred_conf, boundary).view(
|
||||||
|
num_samples, -1, 1), pred_cls.view(
|
||||||
|
num_samples, -1, self.num_classes), ), -1, )
|
||||||
|
if targets is None:
|
||||||
|
return output, 0
|
||||||
|
|
||||||
|
iou_scores, obj_mask, noobj_mask, tx, ty, tw, th, tconf =\
|
||||||
|
build_targets(
|
||||||
|
pred_boxes=pred_boxes,
|
||||||
|
target=targets,
|
||||||
|
anchors=self.scaled_anchors,
|
||||||
|
ignore_thres=self.ignore_thres,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Remove the boundary from predictions, ground truth, and masks
|
||||||
|
# when computing the loss.
|
||||||
|
tensors = [pred_boxes, pred_conf, tconf, x, tx, y, ty,
|
||||||
|
w, tw, h, th, iou_scores, obj_mask, noobj_mask]
|
||||||
|
(pred_boxes, pred_conf, tconf, x, tx, y, ty,
|
||||||
|
w, tw, h, th, iou_scores, obj_mask, noobj_mask) = [
|
||||||
|
slice_boundary(tensor, boundary)
|
||||||
|
for tensor in tensors
|
||||||
|
]
|
||||||
|
# Loss : Mask outputs to ignore non-existing objects (except with conf.
|
||||||
|
# loss)
|
||||||
|
loss_x = self.mse_loss(x[obj_mask.bool()], tx[obj_mask.bool()])
|
||||||
|
loss_y = self.mse_loss(y[obj_mask.bool()], ty[obj_mask.bool()])
|
||||||
|
loss_w = self.mse_loss(w[obj_mask.bool()], tw[obj_mask.bool()])
|
||||||
|
loss_h = self.mse_loss(h[obj_mask.bool()], th[obj_mask.bool()])
|
||||||
|
loss_conf_obj = self.bce_loss(
|
||||||
|
pred_conf[obj_mask.bool()], tconf[obj_mask.bool()])
|
||||||
|
loss_conf_noobj = self.bce_loss(
|
||||||
|
pred_conf[noobj_mask.bool()], tconf[noobj_mask.bool()])
|
||||||
|
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
|
||||||
|
|
||||||
|
if obj_mask.bool().sum().item() == 0:
|
||||||
|
total_loss = self.noobj_scale * loss_conf_noobj
|
||||||
|
else:
|
||||||
|
# Ignore useless classification loss
|
||||||
|
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf
|
||||||
|
|
||||||
|
if torch.isnan(total_loss).item():
|
||||||
|
import pdb
|
||||||
|
pdb.set_trace()
|
||||||
|
|
||||||
|
if not return_metrics:
|
||||||
|
return output, total_loss
|
||||||
|
else:
|
||||||
|
# Metrics
|
||||||
|
conf_obj = pred_conf[obj_mask.bool()].mean()
|
||||||
|
conf_noobj = pred_conf[noobj_mask.bool()].mean()
|
||||||
|
conf50 = (pred_conf > 0.5).float()
|
||||||
|
iou50 = (iou_scores > 0.5).float()
|
||||||
|
iou75 = (iou_scores > 0.75).float()
|
||||||
|
detected_mask = conf50 * tconf
|
||||||
|
precision = torch.sum(iou50 * detected_mask) / \
|
||||||
|
(conf50.sum() + 1e-16)
|
||||||
|
recall50 = torch.sum(iou50 * detected_mask) / \
|
||||||
|
(obj_mask.sum() + 1e-16)
|
||||||
|
recall75 = torch.sum(iou75 * detected_mask) / \
|
||||||
|
(obj_mask.sum() + 1e-16)
|
||||||
|
|
||||||
|
self.metrics = {
|
||||||
|
"loss": to_cpu(total_loss).item(),
|
||||||
|
"x": to_cpu(loss_x).item(),
|
||||||
|
"y": to_cpu(loss_y).item(),
|
||||||
|
"w": to_cpu(loss_w).item(),
|
||||||
|
"h": to_cpu(loss_h).item(),
|
||||||
|
"conf": to_cpu(loss_conf).item(),
|
||||||
|
"recall50": to_cpu(recall50).item(),
|
||||||
|
"recall75": to_cpu(recall75).item(),
|
||||||
|
"precision": to_cpu(precision).item(),
|
||||||
|
"conf_obj": to_cpu(conf_obj).item(),
|
||||||
|
"conf_noobj": to_cpu(conf_noobj).item(),
|
||||||
|
"grid_size": grid_size,
|
||||||
|
}
|
||||||
|
return output, total_loss, self.metrics
|
||||||
|
|
||||||
|
|
||||||
|
class Darknet(nn.Module):
|
||||||
|
"""YOLOv3 object detection model"""
|
||||||
|
|
||||||
|
def __init__(self, config_path, ignore_width, num_classes=80, img_size=416):
|
||||||
|
super(Darknet, self).__init__()
|
||||||
|
self.module_defs = parse_model_config(config_path, num_classes)
|
||||||
|
self.hyperparams, self.module_list = create_modules(
|
||||||
|
self.module_defs, ignore_width)
|
||||||
|
self.yolo_layers = [
|
||||||
|
layer[0] for layer in self.module_list if hasattr(
|
||||||
|
layer[0], "metrics")]
|
||||||
|
self.img_size = img_size
|
||||||
|
self.seen = 0
|
||||||
|
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
|
||||||
|
|
||||||
|
def forward(self, x, targets):
|
||||||
|
img_dim = x.shape[2]
|
||||||
|
loss = 0
|
||||||
|
layer_outputs, yolo_outputs = [], []
|
||||||
|
for i, (module_def, module) in enumerate(
|
||||||
|
zip(self.module_defs, self.module_list)):
|
||||||
|
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
|
||||||
|
x = module(x)
|
||||||
|
elif module_def["type"] == "route":
|
||||||
|
x = torch.cat([layer_outputs[int(layer_i)]
|
||||||
|
for layer_i in module_def["layers"].split(",")], 1)
|
||||||
|
elif module_def["type"] == "shortcut":
|
||||||
|
layer_i = int(module_def["from"])
|
||||||
|
x = layer_outputs[-1] + layer_outputs[layer_i]
|
||||||
|
elif module_def["type"] == "yolo":
|
||||||
|
outputs = module[0](x, targets, img_dim)
|
||||||
|
x, layer_loss = module[0](x, targets, img_dim)
|
||||||
|
loss += layer_loss
|
||||||
|
yolo_outputs.append(x)
|
||||||
|
layer_outputs.append(x)
|
||||||
|
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))
|
||||||
|
return loss, yolo_outputs
|
||||||
|
|
||||||
|
def infer(self, x):
|
||||||
|
loss, yolo_outputs = self.forward(x, None)
|
||||||
|
return yolo_outputs
|
||||||
|
|
||||||
|
def load_darknet_weights(self, weights_path):
|
||||||
|
"""Parses and loads the weights stored in 'weights_path'"""
|
||||||
|
|
||||||
|
# Open the weights file
|
||||||
|
with open(weights_path, "rb") as f:
|
||||||
|
# First five are header values
|
||||||
|
header = np.fromfile(f, dtype=np.int32, count=5)
|
||||||
|
self.header_info = header # Needed to write header when saving weights
|
||||||
|
self.seen = header[3] # number of images seen during training
|
||||||
|
weights = np.fromfile(f, dtype=np.float32) # The rest are weights
|
||||||
|
|
||||||
|
# Establish cutoff for loading backbone weights
|
||||||
|
cutoff = None
|
||||||
|
if "darknet53.conv.74" in weights_path:
|
||||||
|
cutoff = 75
|
||||||
|
|
||||||
|
ptr = 0
|
||||||
|
for i, (module_def, module) in enumerate(
|
||||||
|
zip(self.module_defs, self.module_list)):
|
||||||
|
if i == cutoff:
|
||||||
|
break
|
||||||
|
if module_def["type"] == "convolutional":
|
||||||
|
conv_layer = module[0]
|
||||||
|
if module_def["batch_normalize"]:
|
||||||
|
# Load BN bias, weights, running mean and running variance
|
||||||
|
bn_layer = module[1]
|
||||||
|
num_b = bn_layer.bias.numel() # Number of biases
|
||||||
|
# Bias
|
||||||
|
bn_b = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_b]).view_as(bn_layer.bias)
|
||||||
|
bn_layer.bias.data.copy_(bn_b)
|
||||||
|
ptr += num_b
|
||||||
|
# Weight
|
||||||
|
bn_w = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_b]).view_as(bn_layer.weight)
|
||||||
|
bn_layer.weight.data.copy_(bn_w)
|
||||||
|
ptr += num_b
|
||||||
|
# Running Mean
|
||||||
|
bn_rm = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_b]).view_as(bn_layer.running_mean)
|
||||||
|
bn_layer.running_mean.data.copy_(bn_rm)
|
||||||
|
ptr += num_b
|
||||||
|
# Running Var
|
||||||
|
bn_rv = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_b]).view_as(bn_layer.running_var)
|
||||||
|
bn_layer.running_var.data.copy_(bn_rv)
|
||||||
|
ptr += num_b
|
||||||
|
else:
|
||||||
|
# Load conv. bias
|
||||||
|
num_b = conv_layer.bias.numel()
|
||||||
|
conv_b = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_b]).view_as(conv_layer.bias)
|
||||||
|
conv_layer.bias.data.copy_(conv_b)
|
||||||
|
ptr += num_b
|
||||||
|
# Load conv. weights
|
||||||
|
num_w = conv_layer.weight.numel()
|
||||||
|
conv_w = torch.from_numpy(
|
||||||
|
weights[ptr: ptr + num_w]).view_as(conv_layer.weight)
|
||||||
|
conv_layer.weight.data.copy_(conv_w)
|
||||||
|
ptr += num_w
|
||||||
|
|
||||||
|
def save_darknet_weights(self, path, cutoff=-1):
|
||||||
|
"""
|
||||||
|
@:param path - path of the new weights file
|
||||||
|
@:param cutoff - save layers between 0 and cutoff (cutoff = -1 -> all are saved)
|
||||||
|
"""
|
||||||
|
fp = open(path, "wb")
|
||||||
|
self.header_info[3] = self.seen
|
||||||
|
self.header_info.tofile(fp)
|
||||||
|
|
||||||
|
# Iterate through layers
|
||||||
|
for i, (module_def, module) in enumerate(
|
||||||
|
zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
|
||||||
|
if module_def["type"] == "convolutional":
|
||||||
|
conv_layer = module[0]
|
||||||
|
# If batch norm, load bn first
|
||||||
|
if module_def["batch_normalize"]:
|
||||||
|
bn_layer = module[1]
|
||||||
|
bn_layer.bias.data.cpu().numpy().tofile(fp)
|
||||||
|
bn_layer.weight.data.cpu().numpy().tofile(fp)
|
||||||
|
bn_layer.running_mean.data.cpu().numpy().tofile(fp)
|
||||||
|
bn_layer.running_var.data.cpu().numpy().tofile(fp)
|
||||||
|
# Load conv bias
|
||||||
|
else:
|
||||||
|
conv_layer.bias.data.cpu().numpy().tofile(fp)
|
||||||
|
# Load conv weights
|
||||||
|
conv_layer.weight.data.cpu().numpy().tofile(fp)
|
||||||
|
|
||||||
|
fp.close()
|
||||||
7
detection/models/detection/yolo/constants.py
Normal file
7
detection/models/detection/yolo/constants.py
Normal file
|
|
@ -0,0 +1,7 @@
|
||||||
|
import os
|
||||||
|
|
||||||
|
|
||||||
|
SIZE = 416
|
||||||
|
CONFIG_DIR = os.path.dirname(__file__)
|
||||||
|
CONFIGS = {"yolov3": os.path.join(CONFIG_DIR, "yolov3.cfg"),
|
||||||
|
"yolov3-tiny": os.path.join(CONFIG_DIR, "yolov3-tiny.cfg")}
|
||||||
292
detection/models/detection/yolo/utils.py
Normal file
292
detection/models/detection/yolo/utils.py
Normal file
|
|
@ -0,0 +1,292 @@
|
||||||
|
"""Define Logger class for logging information to stdout and disk."""
|
||||||
|
import collections
|
||||||
|
import os
|
||||||
|
import json
|
||||||
|
import torch
|
||||||
|
import numpy as np
|
||||||
|
import time
|
||||||
|
import torchvision
|
||||||
|
from os.path import join
|
||||||
|
|
||||||
|
|
||||||
|
def xywh2xyxy(x):
|
||||||
|
y = x.new(x.shape)
|
||||||
|
y[..., 0] = x[..., 0] - x[..., 2] / 2
|
||||||
|
y[..., 1] = x[..., 1] - x[..., 3] / 2
|
||||||
|
y[..., 2] = x[..., 0] + x[..., 2] / 2
|
||||||
|
y[..., 3] = x[..., 1] + x[..., 3] / 2
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def bbox_iou(box1, box2, x1y1x2y2=True):
|
||||||
|
"""
|
||||||
|
Returns the IoU of two bounding boxes
|
||||||
|
"""
|
||||||
|
if not x1y1x2y2:
|
||||||
|
# Transform from center and width to exact coordinates
|
||||||
|
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
|
||||||
|
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
|
||||||
|
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
|
||||||
|
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
|
||||||
|
else:
|
||||||
|
# Get the coordinates of bounding boxes
|
||||||
|
b1_x1, b1_y1, b1_x2, b1_y2 = (box1[:, 0], box1[:, 1],
|
||||||
|
box1[:, 2], box1[:, 3])
|
||||||
|
b2_x1, b2_y1, b2_x2, b2_y2 = (box2[:, 0], box2[:, 1],
|
||||||
|
box2[:, 2], box2[:, 3])
|
||||||
|
|
||||||
|
# get the corrdinates of the intersection rectangle
|
||||||
|
inter_rect_x1 = torch.max(b1_x1, b2_x1)
|
||||||
|
inter_rect_y1 = torch.max(b1_y1, b2_y1)
|
||||||
|
inter_rect_x2 = torch.min(b1_x2, b2_x2)
|
||||||
|
inter_rect_y2 = torch.min(b1_y2, b2_y2)
|
||||||
|
# Intersection area
|
||||||
|
inter_area = (torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0) *
|
||||||
|
torch.clamp(inter_rect_y2 - inter_rect_y1 + 1, min=0))
|
||||||
|
# Union Area
|
||||||
|
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
|
||||||
|
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
|
||||||
|
|
||||||
|
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
|
||||||
|
|
||||||
|
return iou
|
||||||
|
|
||||||
|
|
||||||
|
def bbox_wh_iou(wh1, wh2):
|
||||||
|
wh2 = wh2.t()
|
||||||
|
w1, h1 = wh1[0], wh1[1]
|
||||||
|
w2, h2 = wh2[0], wh2[1]
|
||||||
|
inter_area = torch.min(w1, w2) * torch.min(h1, h2)
|
||||||
|
union_area = (w1 * h1 + 1e-16) + w2 * h2 - inter_area
|
||||||
|
return inter_area / union_area
|
||||||
|
|
||||||
|
|
||||||
|
def build_targets(pred_boxes, target, anchors, ignore_thres):
|
||||||
|
|
||||||
|
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda\
|
||||||
|
else torch.ByteTensor
|
||||||
|
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda\
|
||||||
|
else torch.FloatTensor
|
||||||
|
|
||||||
|
nB = pred_boxes.size(0)
|
||||||
|
nA = pred_boxes.size(1)
|
||||||
|
nG = pred_boxes.size(2)
|
||||||
|
|
||||||
|
# Output tensors
|
||||||
|
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1)
|
||||||
|
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
th = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||||
|
|
||||||
|
# Convert to position relative to box
|
||||||
|
target_boxes = target[:, 2:6] * nG
|
||||||
|
gxy = target_boxes[:, :2]
|
||||||
|
gwh = target_boxes[:, 2:]
|
||||||
|
# Get anchors with best iou
|
||||||
|
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors])
|
||||||
|
best_ious, best_n = ious.max(0)
|
||||||
|
# Separate target values
|
||||||
|
b, target_labels = target[:, :2].long().t()
|
||||||
|
gx, gy = gxy.t()
|
||||||
|
gw, gh = gwh.t()
|
||||||
|
gi, gj = gxy.long().t()
|
||||||
|
# Set masks
|
||||||
|
obj_mask[b, best_n, gj, gi] = 1
|
||||||
|
noobj_mask[b, best_n, gj, gi] = 0
|
||||||
|
|
||||||
|
# Set noobj mask to zero where iou exceeds ignore threshold
|
||||||
|
for i, anchor_ious in enumerate(ious.t()):
|
||||||
|
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
|
||||||
|
|
||||||
|
# Coordinates
|
||||||
|
tx[b, best_n, gj, gi] = gx - gx.floor()
|
||||||
|
ty[b, best_n, gj, gi] = gy - gy.floor()
|
||||||
|
# Width and height
|
||||||
|
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
|
||||||
|
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
|
||||||
|
|
||||||
|
iou_scores[b, best_n, gj, gi] = bbox_iou(
|
||||||
|
pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
|
||||||
|
|
||||||
|
tconf = obj_mask.float()
|
||||||
|
return (iou_scores, obj_mask, noobj_mask,
|
||||||
|
tx, ty, tw, th, tconf)
|
||||||
|
|
||||||
|
|
||||||
|
def slice_boundary(t, width):
|
||||||
|
"""Assumes shape (B, C, W, H, ...)."""
|
||||||
|
if not isinstance(width, int):
|
||||||
|
raise ValueError(f"ignore_width must be an integer. Got {width}.")
|
||||||
|
if width < 0:
|
||||||
|
raise ValueError(f"ignore_width must be positive. Got {width}.")
|
||||||
|
if width > t.shape[2] // 2:
|
||||||
|
raise ValueError("ignore_width * 2 must be less than image dim. " +
|
||||||
|
f"Got {width}.")
|
||||||
|
|
||||||
|
if width != 0:
|
||||||
|
return t[:, :, width:-width, width:-width].contiguous()
|
||||||
|
else:
|
||||||
|
return t
|
||||||
|
|
||||||
|
|
||||||
|
def parse_model_config(path, num_classes=80):
|
||||||
|
"""Parses the yolo-v3 layer configuration file and returns module definitions"""
|
||||||
|
file = open(path, 'r')
|
||||||
|
lines = file.read().split('\n')
|
||||||
|
lines = [x for x in lines if x and not x.startswith('#')]
|
||||||
|
lines = [x.rstrip().lstrip()
|
||||||
|
for x in lines] # get rid of fringe whitespaces
|
||||||
|
module_defs = []
|
||||||
|
for line in lines:
|
||||||
|
if line.startswith('['): # This marks the start of a new block
|
||||||
|
module_defs.append({})
|
||||||
|
module_defs[-1]['type'] = line[1:-1].rstrip()
|
||||||
|
if module_defs[-1]['type'] == 'convolutional':
|
||||||
|
module_defs[-1]['batch_normalize'] = 0
|
||||||
|
else:
|
||||||
|
key, value = line.split("=")
|
||||||
|
value = value.strip()
|
||||||
|
module_defs[-1][key.rstrip()] = value.strip()
|
||||||
|
|
||||||
|
# Overwrite number of classes
|
||||||
|
yolo_layers = []
|
||||||
|
for i, module_def in enumerate(module_defs):
|
||||||
|
if module_def['type'] == 'yolo':
|
||||||
|
yolo_layers.append(i)
|
||||||
|
module_defs[i]['classes'] = str(num_classes)
|
||||||
|
|
||||||
|
for i in yolo_layers:
|
||||||
|
module_defs[i - 1]['filters'] = str((num_classes + 5) * 3)
|
||||||
|
|
||||||
|
return module_defs
|
||||||
|
|
||||||
|
|
||||||
|
def parse_data_config(path):
|
||||||
|
"""Parses the data configuration file"""
|
||||||
|
options = dict()
|
||||||
|
options['gpus'] = '0,1,2,3'
|
||||||
|
options['num_workers'] = '10'
|
||||||
|
with open(path, 'r') as fp:
|
||||||
|
lines = fp.readlines()
|
||||||
|
for line in lines:
|
||||||
|
line = line.strip()
|
||||||
|
if line == '' or line.startswith('#'):
|
||||||
|
continue
|
||||||
|
key, value = line.split('=')
|
||||||
|
options[key.strip()] = value.strip()
|
||||||
|
return options
|
||||||
|
|
||||||
|
|
||||||
|
def to_cpu(tensor):
|
||||||
|
return tensor.detach().cpu()
|
||||||
|
|
||||||
|
|
||||||
|
def xy_to_cxcy(xy, height, width):
|
||||||
|
return [(xy[0] + xy[2]) / 2 / width,
|
||||||
|
(xy[1] + xy[3]) / 2 / height,
|
||||||
|
(xy[2] - xy[0]) / width,
|
||||||
|
(xy[3] - xy[1]) / height]
|
||||||
|
|
||||||
|
|
||||||
|
def non_max_suppression(
|
||||||
|
prediction,
|
||||||
|
conf_thres=0.25,
|
||||||
|
iou_thres=0.45,
|
||||||
|
classes=None,
|
||||||
|
agnostic=False,
|
||||||
|
labels=()):
|
||||||
|
"""Performs Non-Maximum Suppression (NMS) on inference results
|
||||||
|
Returns:
|
||||||
|
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
|
||||||
|
"""
|
||||||
|
|
||||||
|
nc = prediction.shape[2] - 5 # number of classes
|
||||||
|
xc = prediction[..., 4] > conf_thres # candidates
|
||||||
|
|
||||||
|
# Settings
|
||||||
|
# (pixels) minimum and maximum box width and height
|
||||||
|
min_wh, max_wh = 2, 4096
|
||||||
|
max_det = 300 # maximum number of detections per image
|
||||||
|
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
|
||||||
|
time_limit = 20.0 # seconds to quit after
|
||||||
|
redundant = True # require redundant detections
|
||||||
|
multi_label = nc > 1 # multiple labels per box (adds 0.5ms/img)
|
||||||
|
merge = False # use merge-NMS
|
||||||
|
|
||||||
|
t = time.time()
|
||||||
|
output = [torch.zeros((0, 6), device=prediction.device)
|
||||||
|
] * prediction.shape[0]
|
||||||
|
for xi, x in enumerate(prediction): # image index, image inference
|
||||||
|
# Apply constraints
|
||||||
|
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 #
|
||||||
|
# width-height
|
||||||
|
x = x[xc[xi]] # confidence
|
||||||
|
|
||||||
|
# Cat apriori labels if autolabelling
|
||||||
|
if labels and len(labels[xi]):
|
||||||
|
l = labels[xi]
|
||||||
|
v = torch.zeros((len(l), nc + 5), device=x.device)
|
||||||
|
v[:, :4] = l[:, 1:5] # box
|
||||||
|
v[:, 4] = 1.0 # conf
|
||||||
|
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
|
||||||
|
x = torch.cat((x, v), 0)
|
||||||
|
|
||||||
|
# If none remain process next image
|
||||||
|
if not x.shape[0]:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Compute conf
|
||||||
|
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
|
||||||
|
|
||||||
|
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
|
||||||
|
box = xywh2xyxy(x[:, :4])
|
||||||
|
|
||||||
|
# Detections matrix nx6 (xyxy, conf, cls)
|
||||||
|
if multi_label:
|
||||||
|
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
|
||||||
|
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
|
||||||
|
else: # best class only
|
||||||
|
conf, j = x[:, 5:].max(1, keepdim=True)
|
||||||
|
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
|
||||||
|
|
||||||
|
# Filter by class
|
||||||
|
if classes is not None:
|
||||||
|
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
|
||||||
|
|
||||||
|
# Apply finite constraint
|
||||||
|
# if not torch.isfinite(x).all():
|
||||||
|
# x = x[torch.isfinite(x).all(1)]
|
||||||
|
|
||||||
|
# Check shape
|
||||||
|
n = x.shape[0] # number of boxes
|
||||||
|
if not n: # no boxes
|
||||||
|
continue
|
||||||
|
elif n > max_nms: # excess boxes
|
||||||
|
# sort by confidence
|
||||||
|
x = x[x[:, 4].argsort(descending=True)[:max_nms]]
|
||||||
|
|
||||||
|
# Batched NMS
|
||||||
|
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
|
||||||
|
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
|
||||||
|
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
|
||||||
|
if i.shape[0] > max_det: # limit detections
|
||||||
|
i = i[:max_det]
|
||||||
|
if merge and (
|
||||||
|
1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
|
||||||
|
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
|
||||||
|
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
|
||||||
|
weights = iou * scores[None] # box weights
|
||||||
|
x[i, :4] = torch.mm(weights, x[:, :4]).float(
|
||||||
|
) / weights.sum(1, keepdim=True) # merged boxes
|
||||||
|
if redundant:
|
||||||
|
i = i[iou.sum(1) > 1] # require redundancy
|
||||||
|
|
||||||
|
output[xi] = x[i]
|
||||||
|
if (time.time() - t) > time_limit:
|
||||||
|
print(f'WARNING: NMS time limit {time_limit}s exceeded')
|
||||||
|
break # time limit exceeded
|
||||||
|
|
||||||
|
return output
|
||||||
206
detection/models/detection/yolo/yolov3-tiny.cfg
Normal file
206
detection/models/detection/yolo/yolov3-tiny.cfg
Normal file
|
|
@ -0,0 +1,206 @@
|
||||||
|
[net]
|
||||||
|
# Testing
|
||||||
|
#batch=1
|
||||||
|
#subdivisions=1
|
||||||
|
# Training
|
||||||
|
batch=64
|
||||||
|
subdivisions=2
|
||||||
|
width=416
|
||||||
|
height=416
|
||||||
|
channels=3
|
||||||
|
momentum=0.9
|
||||||
|
decay=0.0005
|
||||||
|
angle=0
|
||||||
|
saturation = 1.5
|
||||||
|
exposure = 1.5
|
||||||
|
hue=.1
|
||||||
|
|
||||||
|
learning_rate=0.001
|
||||||
|
burn_in=1000
|
||||||
|
max_batches = 500200
|
||||||
|
policy=steps
|
||||||
|
steps=400000,450000
|
||||||
|
scales=.1,.1
|
||||||
|
|
||||||
|
# 0
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=16
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 1
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 2
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=32
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 3
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 4
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=64
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 5
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 6
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 7
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 8
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 9
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 10
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 11
|
||||||
|
[maxpool]
|
||||||
|
size=2
|
||||||
|
stride=1
|
||||||
|
|
||||||
|
# 12
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
###########
|
||||||
|
|
||||||
|
# 13
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 14
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 15
|
||||||
|
[convolutional]
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=255
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# 16
|
||||||
|
[yolo]
|
||||||
|
mask = 3,4,5
|
||||||
|
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
|
||||||
|
classes=80
|
||||||
|
num=6
|
||||||
|
jitter=.3
|
||||||
|
ignore_thresh = .7
|
||||||
|
truth_thresh = 1
|
||||||
|
random=1
|
||||||
|
|
||||||
|
# 17
|
||||||
|
[route]
|
||||||
|
layers = -4
|
||||||
|
|
||||||
|
# 18
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 19
|
||||||
|
[upsample]
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
# 20
|
||||||
|
[route]
|
||||||
|
layers = -1, 8
|
||||||
|
|
||||||
|
# 21
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# 22
|
||||||
|
[convolutional]
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=255
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
# 23
|
||||||
|
[yolo]
|
||||||
|
mask = 1,2,3
|
||||||
|
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
|
||||||
|
classes=80
|
||||||
|
num=6
|
||||||
|
jitter=.3
|
||||||
|
ignore_thresh = .7
|
||||||
|
truth_thresh = 1
|
||||||
|
random=1
|
||||||
788
detection/models/detection/yolo/yolov3.cfg
Normal file
788
detection/models/detection/yolo/yolov3.cfg
Normal file
|
|
@ -0,0 +1,788 @@
|
||||||
|
[net]
|
||||||
|
# Testing
|
||||||
|
#batch=1
|
||||||
|
#subdivisions=1
|
||||||
|
# Training
|
||||||
|
batch=16
|
||||||
|
subdivisions=1
|
||||||
|
width=416
|
||||||
|
height=416
|
||||||
|
channels=3
|
||||||
|
momentum=0.9
|
||||||
|
decay=0.0005
|
||||||
|
angle=0
|
||||||
|
saturation = 1.5
|
||||||
|
exposure = 1.5
|
||||||
|
hue=.1
|
||||||
|
|
||||||
|
learning_rate=0.001
|
||||||
|
burn_in=1000
|
||||||
|
max_batches = 500200
|
||||||
|
policy=steps
|
||||||
|
steps=400000,450000
|
||||||
|
scales=.1,.1
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=32
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
# Downsample
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=64
|
||||||
|
size=3
|
||||||
|
stride=2
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=32
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=64
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
# Downsample
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=3
|
||||||
|
stride=2
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=64
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=64
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
# Downsample
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=2
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
# Downsample
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=2
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
# Downsample
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=2
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=1024
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[shortcut]
|
||||||
|
from=-3
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
######################
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=1024
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=1024
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=512
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=1024
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=255
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[yolo]
|
||||||
|
mask = 6,7,8
|
||||||
|
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||||
|
classes=80
|
||||||
|
num=9
|
||||||
|
jitter=.3
|
||||||
|
ignore_thresh = .7
|
||||||
|
truth_thresh = 1
|
||||||
|
random=1
|
||||||
|
|
||||||
|
|
||||||
|
[route]
|
||||||
|
layers = -4
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[upsample]
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
[route]
|
||||||
|
layers = -1, 61
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=512
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=512
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=256
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=512
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=255
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[yolo]
|
||||||
|
mask = 3,4,5
|
||||||
|
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||||
|
classes=80
|
||||||
|
num=9
|
||||||
|
jitter=.3
|
||||||
|
ignore_thresh = .7
|
||||||
|
truth_thresh = 1
|
||||||
|
random=1
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[route]
|
||||||
|
layers = -4
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[upsample]
|
||||||
|
stride=2
|
||||||
|
|
||||||
|
[route]
|
||||||
|
layers = -1, 36
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=256
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=256
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
filters=128
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
batch_normalize=1
|
||||||
|
size=3
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=256
|
||||||
|
activation=leaky
|
||||||
|
|
||||||
|
[convolutional]
|
||||||
|
size=1
|
||||||
|
stride=1
|
||||||
|
pad=1
|
||||||
|
filters=255
|
||||||
|
activation=linear
|
||||||
|
|
||||||
|
|
||||||
|
[yolo]
|
||||||
|
mask = 0,1,2
|
||||||
|
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||||
|
classes=80
|
||||||
|
num=9
|
||||||
|
jitter=.3
|
||||||
|
ignore_thresh = .7
|
||||||
|
truth_thresh = 1
|
||||||
|
random=1
|
||||||
0
detection/plots/.keepme
Normal file
0
detection/plots/.keepme
Normal file
0
detection/sandbox/.keepme
Normal file
0
detection/sandbox/.keepme
Normal file
0
detection/util/.keepme
Normal file
0
detection/util/.keepme
Normal file
2
detection/util/__init__.py
Normal file
2
detection/util/__init__.py
Normal file
|
|
@ -0,0 +1,2 @@
|
||||||
|
from .constants import *
|
||||||
|
from .util import Args, init_exp_folder, get_concat_h_cut
|
||||||
25
detection/util/constants.py
Normal file
25
detection/util/constants.py
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
"""Define constants to be used throughout the repository."""
|
||||||
|
import os
|
||||||
|
from detectron2.data.catalog import Metadata
|
||||||
|
# Main paths
|
||||||
|
|
||||||
|
# Dataset constants
|
||||||
|
IMAGENET_MEAN = [0.485, 0.456, 0.406]
|
||||||
|
IMAGENET_STD = [0.229, 0.224, 0.225]
|
||||||
|
|
||||||
|
# US latitude/longitude boundaries
|
||||||
|
US_N = 49.4
|
||||||
|
US_S = 24.5
|
||||||
|
US_E = -66.93
|
||||||
|
US_W = -124.784
|
||||||
|
|
||||||
|
# Test image
|
||||||
|
TEST_IMG_PATH = [".circleci/images/test_image.png"] * 2
|
||||||
|
|
||||||
|
|
||||||
|
SANDBOX_PATH = './sandbox'
|
||||||
|
TB_PATH = os.path.join(SANDBOX_PATH, 'tb')
|
||||||
|
|
||||||
|
META = Metadata()
|
||||||
|
META.thing_classes = ["Camera", "Camera"]
|
||||||
|
META.thing_colors = [[20, 200, 60], [11, 119, 32]]
|
||||||
45
detection/util/nni.py
Normal file
45
detection/util/nni.py
Normal file
|
|
@ -0,0 +1,45 @@
|
||||||
|
import os
|
||||||
|
import nni
|
||||||
|
import time
|
||||||
|
import logging
|
||||||
|
import json
|
||||||
|
import traceback
|
||||||
|
from glob import glob
|
||||||
|
|
||||||
|
|
||||||
|
def _cast_value(v):
|
||||||
|
if v == "True":
|
||||||
|
v = True
|
||||||
|
elif v == "False":
|
||||||
|
v = False
|
||||||
|
elif v == "None":
|
||||||
|
v = None
|
||||||
|
return v
|
||||||
|
|
||||||
|
|
||||||
|
def run_nni(train_func, test_func):
|
||||||
|
try:
|
||||||
|
params = nni.get_next_parameter()
|
||||||
|
params = {k: _cast_value(v) for k, v in params.items()}
|
||||||
|
params['exp_name'] = "nni" + str(time.time())
|
||||||
|
logging.info("Final Params:")
|
||||||
|
logging.info(params)
|
||||||
|
|
||||||
|
save_dir, exp_name = train_func(**params)
|
||||||
|
ckpt_reg = os.path.join(save_dir, exp_name, "*.ckpt")
|
||||||
|
print(ckpt_reg)
|
||||||
|
ckpt_path = list(glob(ckpt_reg))[-1]
|
||||||
|
|
||||||
|
test_func(ckpt_path=ckpt_path)
|
||||||
|
|
||||||
|
except RuntimeError as re:
|
||||||
|
if 'out of memory' in str(re):
|
||||||
|
time.sleep(600)
|
||||||
|
params['batch_size'] = int(0.5 * params['batch_size'])
|
||||||
|
train(**params)
|
||||||
|
else:
|
||||||
|
traceback.print_exc()
|
||||||
|
nni.report_final_result(-1)
|
||||||
|
except Exception as e:
|
||||||
|
traceback.print_exc()
|
||||||
|
nni.report_final_result(-2)
|
||||||
31
detection/util/sbatch_template.sh
Executable file
31
detection/util/sbatch_template.sh
Executable file
|
|
@ -0,0 +1,31 @@
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --partition=deep --qos=normal
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --cpus-per-task=4
|
||||||
|
#SBATCH --mem=16G
|
||||||
|
|
||||||
|
# only use the following on partition with GPUs
|
||||||
|
#SBATCH --gres=gpu:1
|
||||||
|
|
||||||
|
#SBATCH --job-name="NAME"
|
||||||
|
#SBATCH --output=/deep/group/aicc-bootcamp/wind/job_logs/NAME-%j.out
|
||||||
|
|
||||||
|
# only use the following if you want email notification
|
||||||
|
####SBATCH --mail-user=youremailaddress
|
||||||
|
####SBATCH --mail-type=ALL
|
||||||
|
|
||||||
|
# list out some useful information (optional)
|
||||||
|
echo "SLURM_JOBID="$SLURM_JOBID
|
||||||
|
echo "SLURM_JOB_NODELIST"=$SLURM_JOB_NODELIST
|
||||||
|
echo "SLURM_NNODES"=$SLURM_NNODES
|
||||||
|
echo "SLURMTMPDIR="$SLURMTMPDIR
|
||||||
|
echo "working directory = "$SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
# sample process (list hostnames of the nodes you've requested)
|
||||||
|
NPROCS=`srun --nodes=${SLURM_NNODES} bash -c 'hostname' |wc -l`
|
||||||
|
echo NPROCS=$NPROCS
|
||||||
|
|
||||||
|
COMMAND
|
||||||
|
|
||||||
|
# done
|
||||||
|
echo "Done"
|
||||||
70
detection/util/util.py
Normal file
70
detection/util/util.py
Normal file
|
|
@ -0,0 +1,70 @@
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
from os.path import join
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
|
||||||
|
LIGHTNING_CKPT_PATH = 'lightning_logs/version_0/checkpoints/'
|
||||||
|
LIGHTNING_TB_PATH = 'lightning_logs/version_0/'
|
||||||
|
LIGHTNING_METRICS_PATH = 'lightning_logs/version_0/metrics.csv'
|
||||||
|
|
||||||
|
|
||||||
|
class Args(dict):
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
self.__dict__.update(args[0])
|
||||||
|
|
||||||
|
def __getattr__(self, name):
|
||||||
|
if name in self:
|
||||||
|
return self[name]
|
||||||
|
raise AttributeError("No such attribute: " + name)
|
||||||
|
|
||||||
|
def __setattr__(self, name, value):
|
||||||
|
self[name] = value
|
||||||
|
|
||||||
|
def __delattr__(self, name):
|
||||||
|
if name in self:
|
||||||
|
del self[name]
|
||||||
|
else:
|
||||||
|
AttributeError("No such attribute: " + name)
|
||||||
|
|
||||||
|
|
||||||
|
def init_exp_folder(args):
|
||||||
|
save_dir = os.path.abspath(args.get("save_dir"))
|
||||||
|
exp_name = args.get("exp_name")
|
||||||
|
exp_path = join(save_dir, exp_name)
|
||||||
|
exp_metrics_path = join(exp_path, "metrics.csv")
|
||||||
|
exp_tb_path = join(exp_path, "tb")
|
||||||
|
global_tb_path = args.get("tb_path")
|
||||||
|
global_tb_exp_path = join(global_tb_path, exp_name)
|
||||||
|
if os.environ.get('LOCAL_RANK') is not None:
|
||||||
|
return
|
||||||
|
|
||||||
|
# init exp path
|
||||||
|
if os.path.exists(exp_path):
|
||||||
|
raise FileExistsError(f"Experiment path [{exp_path}] already exists!")
|
||||||
|
os.makedirs(exp_path, exist_ok=True)
|
||||||
|
|
||||||
|
os.makedirs(global_tb_path, exist_ok=True)
|
||||||
|
if os.path.exists(global_tb_exp_path):
|
||||||
|
raise FileExistsError(f"Experiment exists in the global "
|
||||||
|
f"Tensorboard path [{global_tb_path}]!")
|
||||||
|
os.makedirs(global_tb_path, exist_ok=True)
|
||||||
|
|
||||||
|
# dump hyper-parameters/arguments
|
||||||
|
with open(join(save_dir, exp_name, "args.json"), "w") as f:
|
||||||
|
json.dump(args, f)
|
||||||
|
|
||||||
|
# ln -s for metrics
|
||||||
|
os.symlink(join(exp_path, LIGHTNING_METRICS_PATH),
|
||||||
|
exp_metrics_path)
|
||||||
|
|
||||||
|
# ln -s for tb
|
||||||
|
os.symlink(join(exp_path, LIGHTNING_TB_PATH), exp_tb_path)
|
||||||
|
os.symlink(exp_tb_path, global_tb_exp_path)
|
||||||
|
|
||||||
|
def get_concat_h_cut(im1, im2):
|
||||||
|
dst = Image.new('RGB', (im1.width + im2.width, min(im1.height, im2.height)))
|
||||||
|
dst.paste(im1, (0, 0))
|
||||||
|
dst.paste(im2, (im1.width, 0))
|
||||||
|
return dst
|
||||||
11
main.py
Normal file
11
main.py
Normal file
|
|
@ -0,0 +1,11 @@
|
||||||
|
import fire
|
||||||
|
|
||||||
|
from plot import plot_all
|
||||||
|
from streetview import (download_streetview_image
|
||||||
|
calculate_coverage,
|
||||||
|
calculate_zone,
|
||||||
|
calculate_road_length)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
fire.Fire()
|
||||||
11
plot/__init__.py
Normal file
11
plot/__init__.py
Normal file
|
|
@ -0,0 +1,11 @@
|
||||||
|
from .spatial_distribution import (plot_spatial_distribution,
|
||||||
|
plot_prepost,
|
||||||
|
plot_post,
|
||||||
|
plot_samples)
|
||||||
|
from .coverage import plot_coverage
|
||||||
|
from .precision_recall_curve import plot_precision_recall
|
||||||
|
|
||||||
|
def plot_all():
|
||||||
|
plot_spatial_distribution()
|
||||||
|
plot_coverage()
|
||||||
|
plot_precision_recall()
|
||||||
42
plot/coverage.py
Normal file
42
plot/coverage.py
Normal file
|
|
@ -0,0 +1,42 @@
|
||||||
|
import pandas as pd
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
from util import constants as C
|
||||||
|
from scipy.stats.mstats import winsorize
|
||||||
|
import numpy as np
|
||||||
|
import matplotlib.collections as collections
|
||||||
|
import seaborn as sb
|
||||||
|
import matplotlib
|
||||||
|
|
||||||
|
LABEL = [('SF', 'San Francisco, California, USA'), ('Chicago',
|
||||||
|
'Chicago, Illinois, USA'), ('NYC', 'New York City, New York, USA')]
|
||||||
|
|
||||||
|
|
||||||
|
def plot_coverage():
|
||||||
|
plt.figure(figsize=(8, 4))
|
||||||
|
font = {'family': 'normal',
|
||||||
|
'weight': 'normal',
|
||||||
|
'size': 15}
|
||||||
|
|
||||||
|
matplotlib.rc('font', **font)
|
||||||
|
T = 60
|
||||||
|
COLOR = ['C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7']
|
||||||
|
for i, (name, place) in enumerate(LABEL):
|
||||||
|
data = pd.read_csv(
|
||||||
|
f"/home/haosheng/dataset/camera/sample/meta_0228/{name}_coverage.csv")
|
||||||
|
sb.kdeplot(data.coverage, label=place.split(",")[0], linewidth=2)
|
||||||
|
threshold = np.clip(data.coverage, 0, T).mean()
|
||||||
|
plt.axvline(x=threshold, linestyle='-.', color=COLOR[i])
|
||||||
|
print(f"Average coverage for city {place}: {threshold}")
|
||||||
|
plt.xlim([0, 120])
|
||||||
|
|
||||||
|
plt.legend(loc='upper right')
|
||||||
|
plt.xlabel("Estimated Road Segment Coverage (meter)")
|
||||||
|
plt.ylabel("Probability Density")
|
||||||
|
|
||||||
|
t = np.arange(T, 130, 0.01)
|
||||||
|
collection = collections.BrokenBarHCollection.span_where(
|
||||||
|
t, ymin=0, ymax=1, where=t > 0, facecolor='gray', alpha=0.15)
|
||||||
|
ax = plt.gca()
|
||||||
|
ax.add_collection(collection)
|
||||||
|
plt.subplots_adjust(bottom=0.2)
|
||||||
|
plt.savefig("figures/coverage.png")
|
||||||
29
plot/precision_recall_curve.py
Normal file
29
plot/precision_recall_curve.py
Normal file
|
|
@ -0,0 +1,29 @@
|
||||||
|
from sklearn.metrics import precision_recall_curve, precision_score, recall_score
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
from pathlib import Path
|
||||||
|
from tqdm import tqdm
|
||||||
|
import seaborn as sb
|
||||||
|
import cv2 as cv
|
||||||
|
|
||||||
|
def plot_precision_recall():
|
||||||
|
data = pd.read_csv("/home/haosheng/dataset/camera/test/test_result.csv")
|
||||||
|
plt.figure(figsize=(8,6))
|
||||||
|
sb.set_style("white")
|
||||||
|
for f in [50, 200, 500, 1000]:
|
||||||
|
data_plot = data.query(f"f == {f}")
|
||||||
|
sb.lineplot(x="p", y="recall",
|
||||||
|
data=data_plot,
|
||||||
|
label=f"Pixel threshold: {f}",
|
||||||
|
linewidth=2.5,
|
||||||
|
ci=None)
|
||||||
|
plt.xlim([0.145,1.05])
|
||||||
|
plt.ylim([0,1.05])
|
||||||
|
plt.axvline(x=0.583333, ymin=0, ymax=0.6, linestyle='-.', color='gray')
|
||||||
|
plt.axhline(y=0.624400, xmin=0, xmax=0.48, linestyle='-.', color='gray')
|
||||||
|
plt.plot(0.583333, 0.624400,'ro')
|
||||||
|
plt.xlabel("Precision")
|
||||||
|
plt.ylabel("Recall")
|
||||||
|
plt.legend()
|
||||||
|
plt.savefig("figures/precision_recall.png")
|
||||||
125
plot/spatial_distribution.py
Normal file
125
plot/spatial_distribution.py
Normal file
|
|
@ -0,0 +1,125 @@
|
||||||
|
from util import constants as C
|
||||||
|
import osmnx as ox
|
||||||
|
import pandas as pd
|
||||||
|
import pickle as pkl
|
||||||
|
from tqdm import tqdm
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
import seaborn as sb
|
||||||
|
sb.set()
|
||||||
|
|
||||||
|
|
||||||
|
def plot_samples(
|
||||||
|
meta_file_path="/home/haosheng/dataset/camera/deployment/verified_0425.csv"):
|
||||||
|
data = pd.read_csv(meta_file_path)
|
||||||
|
for city, place in list(C.CITIES.items()):
|
||||||
|
with open(f"/home/haosheng/dataset/camera/shape/graph/{city}.pkl", "rb") as f:
|
||||||
|
G = pkl.load(f)
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
figsize=(12, 12),
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
edge_alpha=0.5,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
sample = data.query(f'city == "{city}"')
|
||||||
|
|
||||||
|
plt.scatter(
|
||||||
|
sample.lon_anchor,
|
||||||
|
sample.lat_anchor,
|
||||||
|
s=0.2,
|
||||||
|
c='blue',
|
||||||
|
alpha=1)
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig(f"figures/samples_{city}.png")
|
||||||
|
print(f"Save figure to [figures/samples_{city}.png]")
|
||||||
|
|
||||||
|
|
||||||
|
def plot_prepost(
|
||||||
|
meta_file_path="/home/haosheng/dataset/camera/deployment/verified_prepost_0425.csv"):
|
||||||
|
data = pd.read_csv(meta_file_path)
|
||||||
|
|
||||||
|
for city, place in list(C.CITIES.items())[:10]:
|
||||||
|
with open(f"/home/haosheng/dataset/camera/shape/graph/{city}.pkl", "rb") as f:
|
||||||
|
G = pkl.load(f)
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
figsize=(12, 12),
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
edge_alpha=0.5,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
|
||||||
|
print("Generating the plot .. ")
|
||||||
|
|
||||||
|
pre = data.query(
|
||||||
|
f'camera_count > 0 and split == "pre" and city == "{city}"')
|
||||||
|
post = data.query(
|
||||||
|
f'camera_count > 0 and split == "post" and city == "{city}"')
|
||||||
|
|
||||||
|
plt.scatter(
|
||||||
|
pre.lon_anchor,
|
||||||
|
pre.lat_anchor,
|
||||||
|
s=150,
|
||||||
|
facecolors='none',
|
||||||
|
edgecolors='red',
|
||||||
|
linewidth=2.0,
|
||||||
|
marker='o')
|
||||||
|
plt.scatter(
|
||||||
|
post.lon_anchor,
|
||||||
|
post.lat_anchor,
|
||||||
|
s=120,
|
||||||
|
c='black',
|
||||||
|
marker='x')
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig(f"figures/prepost_spatial_distribution_{city}.png")
|
||||||
|
print(
|
||||||
|
f"Save figure to [figures/prepost_spatial_distribution_{city}.png]")
|
||||||
|
|
||||||
|
|
||||||
|
def plot_post(
|
||||||
|
meta_file_path="/home/haosheng/dataset/camera/deployment/verified_0425.csv"):
|
||||||
|
data = pd.read_csv(meta_file_path)
|
||||||
|
for city, place in C.CITIES.items():
|
||||||
|
with open(f"/home/haosheng/dataset/camera/shape/graph/{city}.pkl", "rb") as f:
|
||||||
|
G = pkl.load(f)
|
||||||
|
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
figsize=(12, 12),
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
edge_alpha=0.5,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
|
||||||
|
print("Generating the plot .. ")
|
||||||
|
|
||||||
|
pre = data.query(f'camera_count > 0 and city == "{city}"')
|
||||||
|
post = data.query(f'camera_count > 0 and city == "{city}"')
|
||||||
|
|
||||||
|
plt.scatter(
|
||||||
|
pre.lon_anchor,
|
||||||
|
pre.lat_anchor,
|
||||||
|
color='red',
|
||||||
|
#color='#BE0000',
|
||||||
|
s=30,
|
||||||
|
linewidth=2.0,
|
||||||
|
marker='o',
|
||||||
|
alpha=1)
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig(f"figures/post_spatial_distribution_{city}.png")
|
||||||
|
print(f"Save figure to [figures/post_spatial_distribution_{city}.png]")
|
||||||
|
|
||||||
|
|
||||||
|
def plot_spatial_distribution():
|
||||||
|
plot_samples()
|
||||||
|
plot_prepost()
|
||||||
|
plot_post()
|
||||||
17
requirements.txt
Normal file
17
requirements.txt
Normal file
|
|
@ -0,0 +1,17 @@
|
||||||
|
pytorch-lightning==1.1.4
|
||||||
|
test-tube==0.7.1
|
||||||
|
numpy==1.17.2
|
||||||
|
tqdm>=4.36.1
|
||||||
|
pretrainedmodels==0.7.4
|
||||||
|
Pillow==6.2.0
|
||||||
|
fire==0.2.1
|
||||||
|
tensorboardX==1.9
|
||||||
|
streamlit==0.53.0
|
||||||
|
albumentations==0.4.6
|
||||||
|
imgaug==0.4.0
|
||||||
|
pytorch-ignite
|
||||||
|
scikit-learn==0.23.2
|
||||||
|
seaborn==0.10.1
|
||||||
|
segmentation-models-pytorch
|
||||||
|
torch==1.8.1+cu102
|
||||||
|
torchvision==0.9.1+cu102
|
||||||
7
streetview/__init__.py
Normal file
7
streetview/__init__.py
Normal file
|
|
@ -0,0 +1,7 @@
|
||||||
|
from .download import download_streetview_image
|
||||||
|
from .sample import random_points, random_stratified_points
|
||||||
|
from .coverage import calculate_coverage
|
||||||
|
from .zoning import calculate_zone
|
||||||
|
from .road import calculate_road_length
|
||||||
|
|
||||||
|
|
||||||
75
streetview/coverage.py
Normal file
75
streetview/coverage.py
Normal file
|
|
@ -0,0 +1,75 @@
|
||||||
|
import os
|
||||||
|
import osmnx as ox
|
||||||
|
from shapely.geometry import Point
|
||||||
|
from shapely.ops import nearest_points
|
||||||
|
from geopy import distance
|
||||||
|
from tqdm import tqdm
|
||||||
|
import pickle as pkl
|
||||||
|
import pandas as pd
|
||||||
|
import geopandas as gpd
|
||||||
|
import multiprocessing
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from util import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def get_buildings(city, city_tag):
|
||||||
|
tags = tags = {'building': True}
|
||||||
|
building_path = f"/share/data/camera/shape/building/{city}.pkl"
|
||||||
|
if False:#os.path.exists(building_path):
|
||||||
|
with open(building_path, "rb") as f:
|
||||||
|
gdf = pkl.load(f)
|
||||||
|
else:
|
||||||
|
gdf = ox.geometries_from_place(city_tag, tags)
|
||||||
|
with open(building_path, "wb") as f:
|
||||||
|
pkl.dump(gdf, f)
|
||||||
|
rows = []
|
||||||
|
for rid, row in tqdm(gdf.iterrows(), total=len(gdf)):
|
||||||
|
if isinstance(row['geometry'], Point):
|
||||||
|
continue
|
||||||
|
row['centroid_lat'] = row['geometry'].centroid.y
|
||||||
|
row['centroid_lon'] = row['geometry'].centroid.x
|
||||||
|
rows.append(row)
|
||||||
|
buildings = gpd.GeoDataFrame(rows)
|
||||||
|
return buildings
|
||||||
|
|
||||||
|
def get_coverage(lat, lon, buildings, t=0.005, default=50):
|
||||||
|
dist = default
|
||||||
|
try:
|
||||||
|
near_buildings = buildings.query(f"{lat-t} < centroid_lat < {lat+t} and \
|
||||||
|
{lon-t} < centroid_lon < {lon+t}")
|
||||||
|
for rid, row in near_buildings.iterrows():
|
||||||
|
building = row['geometry']
|
||||||
|
|
||||||
|
p = nearest_points(building, Point(lon, lat))[0]
|
||||||
|
_lat, _lon = p.y, p.x
|
||||||
|
_dist = distance.distance((lat, lon), (_lat, _lon)).m
|
||||||
|
dist = min(dist, _dist)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(str(e))
|
||||||
|
pass
|
||||||
|
return 2 * dist
|
||||||
|
|
||||||
|
def get_coverage_df(rtuple):
|
||||||
|
global buildings
|
||||||
|
rid, row = rtuple
|
||||||
|
lat, lon = row['lat'], row['lon']
|
||||||
|
row['coverage'] = get_coverage(lat, lon, buildings)
|
||||||
|
return row
|
||||||
|
|
||||||
|
def calculate_coverage(meta_path="/share/data/camera/deployment/verified_0425.csv"):
|
||||||
|
df = pd.read_csv(meta_path)
|
||||||
|
dfs = []
|
||||||
|
for city, place in list(C.CITIES.items())[:10]:
|
||||||
|
print(f"Load building footprint [{place}]..")
|
||||||
|
buildings = get_buildings(city, place)
|
||||||
|
pano = df.query(f"city == '{city}'")
|
||||||
|
print(f"Start coverage calculation ..")
|
||||||
|
with multiprocessing.Pool(50) as p:
|
||||||
|
rows = list(tqdm(p.imap(get_coverage_df, pano.iterrows()),
|
||||||
|
total=len(pano),
|
||||||
|
smoothing=0.1))
|
||||||
|
pano = pd.DataFrame(rows)
|
||||||
|
dfs.append(pano)
|
||||||
|
pd.concat(dfs).to_csv("/share/data/camera/deployment/verified_0425_coverage.csv", index=False)
|
||||||
130
streetview/download.py
Normal file
130
streetview/download.py
Normal file
|
|
@ -0,0 +1,130 @@
|
||||||
|
import time
|
||||||
|
import traceback
|
||||||
|
import sys
|
||||||
|
import random
|
||||||
|
import hashlib
|
||||||
|
import hmac
|
||||||
|
import base64
|
||||||
|
import fire
|
||||||
|
import os
|
||||||
|
import logging
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
import multiprocessing as mp
|
||||||
|
from tqdm import tqdm
|
||||||
|
import requests as r
|
||||||
|
import urllib.parse as urlparse
|
||||||
|
|
||||||
|
from util import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def _init_downloader(*args):
|
||||||
|
global downloader
|
||||||
|
downloader = SVImageDownloader(*args)
|
||||||
|
|
||||||
|
|
||||||
|
def _download(key):
|
||||||
|
global downloader
|
||||||
|
return downloader.download(key)
|
||||||
|
|
||||||
|
|
||||||
|
class SVImageDownloader:
|
||||||
|
def __init__(self,
|
||||||
|
key_to_sec,
|
||||||
|
save_dir,
|
||||||
|
sleep_time=0.0):
|
||||||
|
self.key_to_sec = key_to_sec
|
||||||
|
self.sleep_time = sleep_time
|
||||||
|
self.save_dir = save_dir
|
||||||
|
|
||||||
|
def get_url(self, panoid, head, keysec):
|
||||||
|
key, secret = keysec
|
||||||
|
url = (f"https://maps.googleapis.com/maps/api/streetview?"
|
||||||
|
f"size={C.SV_SIZE}&pano={panoid}&fov={C.SV_FOV}&"
|
||||||
|
f"heading={head}&pitch={C.SV_PITCH}&key={key}")
|
||||||
|
url = urlparse.urlparse(url)
|
||||||
|
|
||||||
|
# We only need to sign the path+query part of the string
|
||||||
|
url_to_sign = url.path + "?" + url.query
|
||||||
|
# Decode the private key into its binary format
|
||||||
|
# We need to decode the URL-encoded private key
|
||||||
|
decoded_key = base64.urlsafe_b64decode(secret)
|
||||||
|
|
||||||
|
# Create a signature using the private key and the URL-encoded
|
||||||
|
# string using HMAC SHA1. This signature will be binary.
|
||||||
|
signature = hmac.new(decoded_key,
|
||||||
|
str.encode(url_to_sign),
|
||||||
|
hashlib.sha1)
|
||||||
|
|
||||||
|
# Encode the binary signature into base64 for use within a URL
|
||||||
|
encoded_signature = base64.urlsafe_b64encode(signature.digest())
|
||||||
|
original_url = f'{url.scheme}://{url.netloc}{url.path}?{url.query}'
|
||||||
|
|
||||||
|
return original_url + "&signature=" + encoded_signature.decode()
|
||||||
|
|
||||||
|
def download_image(self,
|
||||||
|
panoid,
|
||||||
|
head,
|
||||||
|
keysec,
|
||||||
|
save_path,
|
||||||
|
):
|
||||||
|
os.makedirs(save_path, exist_ok=True)
|
||||||
|
url = self.get_url(panoid, head, keysec)
|
||||||
|
resp = r.get(url)
|
||||||
|
img_binary = resp._content
|
||||||
|
write_path = os.path.join(save_path, f'{panoid}_{head}.jpg')
|
||||||
|
with open(write_path, "wb+") as f:
|
||||||
|
f.write(img_binary)
|
||||||
|
|
||||||
|
def download(self, rtuple):
|
||||||
|
rid, row = rtuple
|
||||||
|
time.sleep(np.random.rand() * self.sleep_time)
|
||||||
|
head = row['heading']
|
||||||
|
try:
|
||||||
|
key_idx = rid % len(self.key_to_sec)
|
||||||
|
keysec = list(self.key_to_sec)[key_idx]
|
||||||
|
self.download_image(panoid=row['panoid'],
|
||||||
|
head=head,
|
||||||
|
keysec=keysec,
|
||||||
|
save_path=self.save_dir)
|
||||||
|
except BaseException as e:
|
||||||
|
traceback.print_exception(*sys.exc_info())
|
||||||
|
return {"panoid": row['panoid'],
|
||||||
|
"heading": head,
|
||||||
|
"exception": str(e)}
|
||||||
|
return {"panoid": None}
|
||||||
|
|
||||||
|
class ParallelSVImageDownloader:
|
||||||
|
def __init__(self,
|
||||||
|
key_to_sec,
|
||||||
|
save_dir,
|
||||||
|
sleep_time=0.0,
|
||||||
|
nthread=10,
|
||||||
|
):
|
||||||
|
self.key_to_sec = key_to_sec
|
||||||
|
self.save_dir = save_dir
|
||||||
|
self.sleep_time = sleep_time
|
||||||
|
self.nthread = nthread
|
||||||
|
os.makedirs(self.save_dir, exist_ok=True)
|
||||||
|
|
||||||
|
def download(self, df, sample_frac=1.0):
|
||||||
|
df = df.sample(frac=sample_frac)
|
||||||
|
|
||||||
|
print("Start downloading ...")
|
||||||
|
with mp.Pool(self.nthread,
|
||||||
|
initializer=_init_downloader,
|
||||||
|
initargs=(self.key_to_sec, self.save_dir, self.sleep_time)) as p:
|
||||||
|
df = list(tqdm(p.imap(_download, df.iterrows()),
|
||||||
|
total=len(df),
|
||||||
|
smoothing=0.1))
|
||||||
|
|
||||||
|
image_errors = pd.DataFrame(df)
|
||||||
|
image_errors.dropna(subset=['panoid'], inplace=True)
|
||||||
|
return image_errors
|
||||||
|
|
||||||
|
|
||||||
|
def download_streetview_image(key, sec):
|
||||||
|
df = pd.read_csv("data/meta.csv")
|
||||||
|
downloader = ParallelSVImageDownloader(key_to_sec=[(key, sec)],
|
||||||
|
save_dir="./data/image")
|
||||||
|
downloader.download(df)
|
||||||
71
streetview/evaluate.py
Normal file
71
streetview/evaluate.py
Normal file
|
|
@ -0,0 +1,71 @@
|
||||||
|
import seaborn as sb
|
||||||
|
import numpy as np
|
||||||
|
import osmnx as ox
|
||||||
|
from geopy.distance import distance
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
|
||||||
|
|
||||||
|
def evaluate_coverage_distance(df):
|
||||||
|
sb.set_style("dark")
|
||||||
|
f, axes = plt.subplots(2, 2, figsize=(12,8))
|
||||||
|
axes[0][0].title.set_text(f"Coverage of [2011-2015]: {len(df)} / 5000 = {len(df)/5000*100:.2f}%")
|
||||||
|
axes[0][1].title.set_text(f"Coverage of [2016-2020]: {len(df)} / 5000 = {len(df)/5000*100:.2f}%")
|
||||||
|
sb.countplot(x="year_pre", data=df, ax=axes[0][0], palette=['#432371'])
|
||||||
|
sb.countplot(x="year_post", data=df, ax=axes[0][1], palette=["#FAAE7B"])
|
||||||
|
axes[0][0].set_xlabel('')
|
||||||
|
axes[0][1].set_xlabel('')
|
||||||
|
|
||||||
|
d1, i1 = zip(*get_closest_distances(df, 'pre'))
|
||||||
|
d2, i2 = zip(*get_closest_distances(df, 'post'))
|
||||||
|
sb.lineplot(x=range(len(d1)), y=d1, ax=axes[1][0])
|
||||||
|
sb.lineplot(x=range(len(d2)), y=d2, ax=axes[1][1])
|
||||||
|
axes[1][0].title.set_text(f"Top 50 closest distance of [2011-2015] panoramas")
|
||||||
|
axes[1][1].title.set_text(f"Top 50 closest distance of [2016-2020] panoramas")
|
||||||
|
return f
|
||||||
|
|
||||||
|
def get_closest_distances(df, suffix='pre', n=50):
|
||||||
|
lat = df[f'lat_{suffix}'].values
|
||||||
|
lon = df[f'lon_{suffix}'].values
|
||||||
|
D = np.sqrt(np.square(lat[:,np.newaxis] - lat) + np.square(lon[:,np.newaxis] - lon))
|
||||||
|
D = np.tril(D) + np.triu(np.ones_like(D))
|
||||||
|
d = []
|
||||||
|
for i in range(n):
|
||||||
|
x, y = np.unravel_index(D.argmin(), D.shape)
|
||||||
|
_d = distance((lat[x], lon[x]), (lat[y], lon[y])).m
|
||||||
|
d.append((_d, x))
|
||||||
|
D[x,:] = D[:,x] = 1
|
||||||
|
return sorted(d)
|
||||||
|
|
||||||
|
def evaluate_spatial_distribution(df, city):
|
||||||
|
sb.set_style("white")
|
||||||
|
G = ox.graph_from_place(city, network_type='drive')
|
||||||
|
try:
|
||||||
|
G = ox.simplify_graph(G)
|
||||||
|
except:
|
||||||
|
G = G
|
||||||
|
|
||||||
|
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(24,12))
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
ax=ax1,
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
ax1.scatter(df.lon_anchor, df.lat_anchor, s=3, c='red', alpha=0.5)
|
||||||
|
ax1.scatter(df.lon_pre, df.lat_pre, s=3, c='blue', alpha=0.5)
|
||||||
|
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
ax=ax2,
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
ax2.scatter(df.lon_anchor, df.lat_anchor, s=3, c='red', alpha=0.5)
|
||||||
|
ax2.scatter(df.lon_post, df.lat_post, s=3, c='blue', alpha=0.5)
|
||||||
|
plt.show()
|
||||||
39
streetview/plot.py
Normal file
39
streetview/plot.py
Normal file
|
|
@ -0,0 +1,39 @@
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
import seaborn as sb
|
||||||
|
import osmnx as ox
|
||||||
|
|
||||||
|
|
||||||
|
def evaluate_spatial_distribution(df):
|
||||||
|
sb.set_style("white")
|
||||||
|
G = ox.graph_from_place('San Francisco, California, USA',
|
||||||
|
network_type='drive')
|
||||||
|
try:
|
||||||
|
G = ox.simplify_graph(G)
|
||||||
|
except:
|
||||||
|
G = G
|
||||||
|
|
||||||
|
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(24,12))
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
ax=ax1,
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
ax1.scatter(df.lon_anchor, df.lat_anchor, s=3, c='red', alpha=0.5)
|
||||||
|
ax1.scatter(df.lon_pre, df.lat_pre, s=3, c='blue', alpha=0.5)
|
||||||
|
|
||||||
|
ox.plot.plot_graph(G,
|
||||||
|
ax=ax2,
|
||||||
|
bgcolor='white',
|
||||||
|
node_color='#696969',
|
||||||
|
edge_color="#A9A9A9",
|
||||||
|
edge_linewidth=0.8,
|
||||||
|
node_size=0,
|
||||||
|
save=False,
|
||||||
|
show=False)
|
||||||
|
ax2.scatter(df.lon_anchor, df.lat_anchor, s=3, c='red', alpha=0.5)
|
||||||
|
ax2.scatter(df.lon_post, df.lat_post, s=3, c='blue', alpha=0.5)
|
||||||
|
plt.show()
|
||||||
28
streetview/road.py
Normal file
28
streetview/road.py
Normal file
|
|
@ -0,0 +1,28 @@
|
||||||
|
import os
|
||||||
|
import osmnx as ox
|
||||||
|
import pandas as pd
|
||||||
|
from tqdm import tqdm
|
||||||
|
import geopandas as gpd
|
||||||
|
|
||||||
|
from util import constants as C
|
||||||
|
|
||||||
|
|
||||||
|
def calculate_road_length():
|
||||||
|
metas = []
|
||||||
|
for name, place in tqdm(C.CITIES.items(), total=len(C.CITIES)):
|
||||||
|
meta = ox.geocode_to_gdf(place)
|
||||||
|
meta = meta.to_crs('EPSG:3395')
|
||||||
|
meta['area'] = meta.geometry.apply(lambda x: x.area / 1e6)
|
||||||
|
|
||||||
|
G = ox.graph_from_place(place, network_type='drive')
|
||||||
|
try:
|
||||||
|
G = ox.simplify_graph(G)
|
||||||
|
except:
|
||||||
|
G = G
|
||||||
|
gdf = ox.utils_graph.graph_to_gdfs(G, nodes=False, edges=True)
|
||||||
|
meta['length'] = gdf['length'].sum() / 1e3
|
||||||
|
metas.append(meta)
|
||||||
|
stats = gpd.GeoDataFrame(pd.concat(metas))[['display_name', 'area', 'length']] \
|
||||||
|
.rename(columns={"area": "area(km^2)", "length": "length(km)"})
|
||||||
|
print(stats)
|
||||||
|
|
||||||
173
streetview/sample.py
Normal file
173
streetview/sample.py
Normal file
|
|
@ -0,0 +1,173 @@
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
from tqdm import tqdm
|
||||||
|
import random
|
||||||
|
import os
|
||||||
|
from geopy.distance import distance
|
||||||
|
from shapely.geometry import MultiPoint
|
||||||
|
|
||||||
|
from .util import get_heading
|
||||||
|
|
||||||
|
def random_points(edges,
|
||||||
|
n=100,
|
||||||
|
d=None,
|
||||||
|
verbose=False):
|
||||||
|
m = len(edges)
|
||||||
|
lengths = edges['length'].tolist()
|
||||||
|
total_length = edges.sum()['length']
|
||||||
|
lengths_normalized = [l/total_length for l in lengths]
|
||||||
|
|
||||||
|
rows = []
|
||||||
|
points = []
|
||||||
|
indices = np.random.choice(range(m),
|
||||||
|
size=2*n,
|
||||||
|
p=lengths_normalized)
|
||||||
|
pbar = tqdm(total=n)
|
||||||
|
i = j = 0
|
||||||
|
while i < n:
|
||||||
|
index = indices[j]
|
||||||
|
row = edges.iloc[index]
|
||||||
|
u, v, key = edges.index[index]
|
||||||
|
line = row['geometry']
|
||||||
|
offset = np.random.rand() * line.length
|
||||||
|
point = line.interpolate(offset)
|
||||||
|
lat = point.y
|
||||||
|
lon = point.x
|
||||||
|
flag = 1
|
||||||
|
if d is not None:
|
||||||
|
for _lat, _lon in points:
|
||||||
|
_d = np.sqrt(np.square(lat-_lat) + np.square(lon-_lon))
|
||||||
|
if _d < 1e-4 and distance((lat, lon), (_lat, _lon)).m < d:
|
||||||
|
flag = 0
|
||||||
|
break
|
||||||
|
if flag:
|
||||||
|
i += 1
|
||||||
|
pbar.update(1)
|
||||||
|
start = line.interpolate(offset*0.9)
|
||||||
|
end = line.interpolate(min(line.length, offset*1.1))
|
||||||
|
heading = get_heading(start.y, start.x, end.y, end.x)
|
||||||
|
rows.append({"lat": lat,
|
||||||
|
"lon": lon,
|
||||||
|
"id": i,
|
||||||
|
"u": u,
|
||||||
|
"v": v,
|
||||||
|
"heading": heading,
|
||||||
|
"offset": offset,
|
||||||
|
"key": key})
|
||||||
|
points.append((lat, lon))
|
||||||
|
j += 1
|
||||||
|
pbar.close()
|
||||||
|
return pd.DataFrame(rows)
|
||||||
|
|
||||||
|
def random_stratified_points(edges, n=10):
|
||||||
|
m = len(edges)
|
||||||
|
rows = []
|
||||||
|
for index in range(len(edges)):
|
||||||
|
row = edges.iloc[index]
|
||||||
|
u, v, key = edges.index[index]
|
||||||
|
line = row['geometry']
|
||||||
|
|
||||||
|
for _ in range(n):
|
||||||
|
offset = np.random.rand() * line.length
|
||||||
|
point = line.interpolate(offset)
|
||||||
|
lat = point.y
|
||||||
|
lon = point.x
|
||||||
|
rows.append({"lat": lat,
|
||||||
|
"lon": lon,
|
||||||
|
"u": u,
|
||||||
|
"v": v,
|
||||||
|
"key": key})
|
||||||
|
return pd.DataFrame(rows)
|
||||||
|
|
||||||
|
def select_panoid(meta,
|
||||||
|
n=5000,
|
||||||
|
distance=10,
|
||||||
|
selection="closest",
|
||||||
|
seed=123):
|
||||||
|
YEARS = ["2010<year<2016", "2016<=year"]
|
||||||
|
|
||||||
|
# Set random seed
|
||||||
|
np.random.seed(seed)
|
||||||
|
random.seed(seed)
|
||||||
|
|
||||||
|
# Filter by distance
|
||||||
|
meta = meta.query(f"distance < {distance}")
|
||||||
|
|
||||||
|
# Filter by occurance for both pre and post
|
||||||
|
meta_pre = meta.query(YEARS[0]).drop_duplicates(["lat_anchor", "lon_anchor"])
|
||||||
|
meta_post = meta.query(YEARS[1]).drop_duplicates(["lat_anchor", "lon_anchor"])
|
||||||
|
meta_both = meta_pre.merge(meta_post, on=["lat_anchor", "lon_anchor"], how="inner")
|
||||||
|
|
||||||
|
# Sample anchor points
|
||||||
|
meta_sample = meta_both.drop_duplicates(['lat_anchor', 'lon_anchor']).sample(n, replace=False)
|
||||||
|
lat_anchor_chosen = meta_sample.lat_anchor.unique()
|
||||||
|
lon_anchor_chosen = meta_sample.lon_anchor.unique()
|
||||||
|
|
||||||
|
# Sample for pre and post
|
||||||
|
meta_sub = meta[meta.lat_anchor.isin(lat_anchor_chosen)]
|
||||||
|
meta_sub = meta_sub[meta_sub.lon_anchor.isin(lon_anchor_chosen)]
|
||||||
|
|
||||||
|
# Select panoid
|
||||||
|
groups = []
|
||||||
|
for years in YEARS:
|
||||||
|
group = meta_sub.query(years)
|
||||||
|
if selection == "closest":
|
||||||
|
group = group.sort_values(['lat_anchor','lon_anchor', 'distance'])
|
||||||
|
else:
|
||||||
|
group = group.sort_values(['lat_anchor','lon_anchor', 'year'], ascending=False)
|
||||||
|
group = group.groupby(['lat_anchor','lon_anchor']).first().reset_index()
|
||||||
|
group['year'] = group.year.apply(int)
|
||||||
|
groups.append(group)
|
||||||
|
|
||||||
|
# Random select the orthogonal heading
|
||||||
|
merged = groups[0].merge(groups[1],
|
||||||
|
on=['lat_anchor', 'lon_anchor', 'u', 'v', 'key', 'heading', 'offset'],
|
||||||
|
suffixes=("_pre", "_post"))
|
||||||
|
|
||||||
|
merged['heading_pre'] = merged['heading_post'] = (merged.heading + 360 + 90 - 180 * (np.random.rand(n) > 0.5)) % 360
|
||||||
|
merged['heading_pre'] = merged['heading_pre'].apply(int)
|
||||||
|
merged['heading_post'] = merged['heading_post'].apply(int)
|
||||||
|
return merged
|
||||||
|
|
||||||
|
def select_panoid_recent(meta,
|
||||||
|
year,
|
||||||
|
n=5000,
|
||||||
|
distance=10,
|
||||||
|
seed=123):
|
||||||
|
|
||||||
|
# Set random seed
|
||||||
|
np.random.seed(seed)
|
||||||
|
random.seed(seed)
|
||||||
|
|
||||||
|
# Filter by distance
|
||||||
|
meta = meta.query(f"distance < {distance}")
|
||||||
|
meta = meta.query(f"year >= {year}")
|
||||||
|
|
||||||
|
# Sample anchor points
|
||||||
|
meta_sample = meta.drop_duplicates(['id']).sample(n, replace=False)
|
||||||
|
lat_anchor_chosen = meta_sample.lat_anchor.unique()
|
||||||
|
lon_anchor_chosen = meta_sample.lon_anchor.unique()
|
||||||
|
|
||||||
|
# Sample for pre and post
|
||||||
|
meta_sub = meta[meta.lat_anchor.isin(lat_anchor_chosen)]
|
||||||
|
meta_sub = meta_sub[meta_sub.lon_anchor.isin(lon_anchor_chosen)]
|
||||||
|
|
||||||
|
# Select panoid
|
||||||
|
|
||||||
|
meta = meta_sub.sort_values(['lat_anchor','lon_anchor', 'distance']) \
|
||||||
|
.groupby(['lat_anchor','lon_anchor']) \
|
||||||
|
.first().reset_index()
|
||||||
|
|
||||||
|
# Random select the orthogonal heading
|
||||||
|
meta['road_heading'] = meta.heading
|
||||||
|
meta['heading'] = (meta.heading + 360 + 90 - 180 * (np.random.rand(n) > 0.5)) % 360
|
||||||
|
meta['heading'] = meta['heading'].apply(int)
|
||||||
|
meta['year'] = meta['year'].apply(int)
|
||||||
|
meta['month'] = meta['month'].apply(int)
|
||||||
|
meta['save_path'] = meta.apply(get_path, 1)
|
||||||
|
return meta
|
||||||
|
|
||||||
|
def get_path(row):
|
||||||
|
panoid = row['panoid']
|
||||||
|
heading = row['heading']
|
||||||
|
return os.path.join("/scratch/haosheng/camera/", panoid[:2], panoid[2:4], panoid[4:6], panoid[6:], f"{heading}.png")
|
||||||
8
streetview/util.py
Normal file
8
streetview/util.py
Normal file
|
|
@ -0,0 +1,8 @@
|
||||||
|
from geographiclib.geodesic import Geodesic
|
||||||
|
|
||||||
|
|
||||||
|
def get_heading(lat1, lon1, lat2, lon2):
|
||||||
|
return Geodesic.WGS84.Inverse(lat1, lon1, lat2, lon2)['azi1']
|
||||||
|
|
||||||
|
#def is_close(lat1, lon1, lat2, lon2, d=None):
|
||||||
|
|
||||||
78
streetview/zoning.py
Normal file
78
streetview/zoning.py
Normal file
|
|
@ -0,0 +1,78 @@
|
||||||
|
import geopandas as gpd
|
||||||
|
from geopy import distance
|
||||||
|
import pandas as pd
|
||||||
|
from shapely.geometry import Point
|
||||||
|
import numpy as np
|
||||||
|
from shapely.ops import nearest_points
|
||||||
|
from sklearn.neighbors import KDTree
|
||||||
|
from tqdm import tqdm
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
import sys
|
||||||
|
|
||||||
|
from util import constants as C
|
||||||
|
|
||||||
|
CITIES = [('NYC', 'New York'), ('SF', 'San Francisco'), ('Seattle', 'Seattle'), ('Boston', 'Boston'), ('Chicago', 'Chicago'), ('Philadelphia', 'Philadelphia'), ('DC', 'Washington'),
|
||||||
|
('LA', 'Los Angeles'), ('Baltimore', 'Baltimore'), ('Milwaukee', 'Milwaukee')]
|
||||||
|
|
||||||
|
class Zoning:
|
||||||
|
def __init__(self, path):
|
||||||
|
self.path = path
|
||||||
|
self.gdf = gpd.read_file(self.path)
|
||||||
|
self.zone_type = self.gdf.zone_type.tolist()
|
||||||
|
self._get_centroids()
|
||||||
|
|
||||||
|
def _get_centroids(self):
|
||||||
|
centroids = self.gdf.centroid
|
||||||
|
coords = []
|
||||||
|
for i, c in enumerate(centroids):
|
||||||
|
if c is None or self.zone_type[i] == 'roads':
|
||||||
|
coords.append([10000, 10000])
|
||||||
|
else:
|
||||||
|
coords.append([c.y, c.x])
|
||||||
|
self.coords = KDTree(np.array(coords), leaf_size=30)
|
||||||
|
|
||||||
|
def get_zone(self, lat, lon, n=-1, return_polygon=False):
|
||||||
|
if n == -1:
|
||||||
|
ind = range(len(self.gdf))
|
||||||
|
else:
|
||||||
|
ind = self.coords.query(np.array([lat, lon])[np.newaxis,:], k=n, return_distance=False).flatten()
|
||||||
|
dist = 10000
|
||||||
|
zone_type = None
|
||||||
|
zone = None
|
||||||
|
for i in list(ind):
|
||||||
|
_zone = self.gdf.geometry.iloc[i]
|
||||||
|
#for p in nearest_points(_zone, Point(lon, lat)):
|
||||||
|
p = nearest_points(_zone, Point(lon, lat))[0]
|
||||||
|
_lat, _lon = p.y, p.x
|
||||||
|
_dist = distance.distance((lat, lon), (_lat, _lon)).m
|
||||||
|
if _dist < dist:
|
||||||
|
zone_type = self.zone_type[i]
|
||||||
|
dist = _dist
|
||||||
|
zone = _zone
|
||||||
|
if return_polygon:
|
||||||
|
return zone_type, dist, zone
|
||||||
|
else:
|
||||||
|
return zone_type, dist
|
||||||
|
|
||||||
|
def calculate_zone(meta_path="/share/data/camera/deployment/verified_0425.csv"):
|
||||||
|
|
||||||
|
df = pd.read_csv(meta_path)
|
||||||
|
dfs = []
|
||||||
|
for city, city_tag in CITIES:
|
||||||
|
print(f"Loading zoning shapefile for [{city_tag}]..")
|
||||||
|
try:
|
||||||
|
zone = Zoning(f"/share/data/camera/zoning/{city_tag}_zoning_clean.shp")
|
||||||
|
except Exception as e:
|
||||||
|
print(str(e))
|
||||||
|
continue
|
||||||
|
|
||||||
|
final = df.query(f"city == '{city}'")
|
||||||
|
rows = []
|
||||||
|
for rid, row in tqdm(final.iterrows(), total=len(final)):
|
||||||
|
z, d = zone.get_zone(row['lat'], row['lon'], n=5)
|
||||||
|
row['zone_type'] = z
|
||||||
|
row['zone_distance'] = d
|
||||||
|
rows.append(row)
|
||||||
|
zone_final = pd.DataFrame(rows)
|
||||||
|
dfs.append(zone_final)
|
||||||
|
pd.concat(dfs).to_csv("/share/data/camera/deployment/verified_0425_zone.csv", index=False)
|
||||||
22
util/constants.py
Normal file
22
util/constants.py
Normal file
|
|
@ -0,0 +1,22 @@
|
||||||
|
# SV configuration
|
||||||
|
SV_FOV = '90'
|
||||||
|
SV_SIZE = '640x640'
|
||||||
|
SV_PITCH = '0'
|
||||||
|
|
||||||
|
# Network configuration
|
||||||
|
CITIES = {'NYC': 'New York City, New York, USA',
|
||||||
|
'SF': 'San Francisco, California, USA',
|
||||||
|
'Seattle': 'Seattle, Washington, USA',
|
||||||
|
'Boston': 'Boston, Massachusetts, USA',
|
||||||
|
'Chicago': 'Chicago, Illinois, USA',
|
||||||
|
'Philadelphia': 'Philadelphia, Pennsylvania, USA',
|
||||||
|
'DC': 'Washington, D.C, USA',
|
||||||
|
'LA': 'Los Angeles, California, USA',
|
||||||
|
'Baltimore': 'Baltimore, Maryland, USA',
|
||||||
|
'Milwaukee': 'Milwaukee, Wisconsin, USA',
|
||||||
|
'London': 'London, UK',
|
||||||
|
'Paris': 'Paris, France',
|
||||||
|
'Tokyo': 'Tokyo, Japan',
|
||||||
|
'Bangkok': 'Bangkok, Thailand',
|
||||||
|
'Singapore': 'Singapore, Singapore',
|
||||||
|
'Seoul': 'Seoul, South Korea'}
|
||||||
Loading…
Reference in a new issue